��HADOOP�������ţ�
| HADOOP�������� |
HADOOP�������� |
HADOOP�������� |
| HADOOP�ڴ����ݡ��Ƽ����е�λ�ú�ϵ |
||
| ������HADOOPӦ�ð������� |
||
| ����HADOOP�ľ�ҵ����������γ̴�ٽ��� |
||
| �ֲ�ʽϵͳ���� |
||
| HADOOP��̬Ȧ�Լ�����ɲ��ֵļ�� |
||
| Hive�������� |
Hive�������� |
Hive�������� |
| Hive��ʹ�� |
||
| ���ݲֿ����֪ʶ |
||
| ���ݷ���������ʾ |
������� |
���У��������������ݸ�ʽ |
| ���ݻ�ȡ |
��ҵ�л�ȡ���ݵļ��ַ�ʽ |
|
| ���ļ�ֱ�ӵ��뵽���ݲֿ� |
||
| �����ݿ�����ݵ��뵽���ݲֿ⣨sqoop�� |
||
| ���ݴ��� |
ʹ��Hive����������ϴ��ETL�Ĺ��̣� |
|
| ���ݼ��� |
ʹ��Hive�����ݽ��м��� |
|
| ����չ�� |
��������ݵ�����mysql��sqoop�� |
1. HADOOP��������
1.1 ʲô��HADOOP
- HADOOP��apache���µ�һ��Դ����ƽ̨
- HADOOP�ṩ�Ĺ��ܣ����÷�������Ⱥ�������û����Զ���ҵ�������Ժ������ݽ��зֲ�ʽ����
- HADOOP��������
-
- HDFS���ֲ�ʽ�ļ�ϵͳ��
- YARN��������Դ����ϵͳ��
- MAPREDUCE���ֲ�ʽ�����̿�ܣ�
-
- ��������˵��HADOOPͨ����ָһ�����㷺�ĸ����HADOOP��̬Ȧ
1.2 HADOOP��������
- HADOOP������Դ��Nutch��Nutch�����Ŀ���ǹ���һ�����͵�ȫ���������棬������ҳץȡ����������ѯ�ȹ��ܣ�������ץȡ��ҳ���������ӣ����������صĿ���չ�����⡪����ν����ʮ����ҳ�Ĵ洢���������⡣
- 2003�ꡢ2004���ȸ跢������ƪ����Ϊ�������ṩ�˿��еĽ��������
�����ֲ�ʽ�ļ�ϵͳ��GFS���������ڴ���������ҳ���洢
�����ֲ�ʽ������MAPREDUCE�������ڴ���������ҳ�������������⡣
- Nutch�Ŀ�����Ա�������Ӧ����Դʵ��HDFS��MAPREDUCE������Nutch�а����Ϊ������ĿHADOOP����2008��1�£�HADOOP��ΪApache������Ŀ��ӭ�������Ŀ��ٷ�չ�ڡ�
1.3 HADOOP�ڴ����ݡ��Ƽ����е�λ�ú�ϵ
- �Ƽ����Ƿֲ�ʽ���㡢���м��㡢������㡢��˼��㡢����洢�����⻯�����ؾ���ȴ�ͳ����������ͻ����������ںϷ�չ�IJ������IaaS(������ʩ������)��PaaS(ƽ̨������)��SaaS������������ҵ��ģʽ����ǿ��ļ��������ṩ���ն��û���
- �ֽΣ��Ƽ��������ײ�֧�ż���Ϊ�����⻯���͡������ݼ�����
- ��HADOOP�����Ƽ����PaaS��Ľ������֮һ��������ͬ��PaaS��������ͬ���Ƽ��㱾����
1.4 ������HADOOPӦ�ð�������
1��HADOOPӦ�������ݷ������ƽ̨����
2/HADOOP�����û�����
3��HADOOP������վ�������־�����ھ�
1.5 ����HADOOP�ľ�ҵ�������
- HADOOP��ҵ�������
- �����ݲ�ҵ����������ʮ����滮
- ������ж��ڽ����ǻ۳�����Ŀ���裬���ǻ۳��еĸ������Ǵ������ۺ�ƽ̨
- ������ʱ�����ݵ����࣬��������������ʽ����������ҵ�����ݵļ�ֵ��������
- ����ڴ�ͳJAVAEE����������˵��������������˲����ϡȱ
- �����ִ����ķ�չ�����ݴ����������ھ����Ҫ��ֻ�������������ˣ������ݼ�����һ���������չ�Ҿ�����Զǰ��������
- HADOOP��ҵְλҪ��
�������Ǹ�����רҵ������Ӧ�ÿ���������ƽ̨���㷨�������ھ�ȣ���ˣ������ݼ�������ľ�ҵѡ���Ƕ�����������HADOOP���ԣ�ͨ������Ҫ�߱����¼��ܻ�֪ʶ��
- HADOOP�ֲ�ʽ��Ⱥ��ƽ̨�
- HADOOP�ֲ�ʽ�ļ�ϵͳHDFS��ԭ�����⼰ʹ��
- HADOOP�ֲ�ʽ������MAPREDUCE��ԭ�����⼰���
- Hive���ݲֿ�ߵ�����Ӧ��
- Flume��sqoop��oozie�ȸ������ߵ�����ʹ��
- Shell/python�Ƚű����ԵĿ�������
- HADOOP���ְλ��н��ˮƽ
�����ݼ�������嵽HADOOP�ľ�ҵ����Ŀǰ��Ҫ�����ڱ��Ϲ���һ�߳��У�н�ʴ����ձ���ڴ�ͳJAVAEE������Ա���Ա���Ϊ����
1.6 HADOOP��̬Ȧ�Լ�����ɲ��ֵļ��
��������[M1]
�ص������
HDFS���ֲ�ʽ�ļ�ϵͳ
MAPREDUCE���ֲ�ʽ����������
HIVE�����ڴ����ݼ������ļ�ϵͳ+�����ܣ���SQL���ݲֿ��
HBASE������HADOOP�ķֲ�ʽ�������ݿ�
ZOOKEEPER���ֲ�ʽЭ������������
Mahout������mapreduce/spark/flink�ȷֲ�ʽ�����ܵĻ���ѧϰ�㷨��
Oozie�����������ȿ��
Sqoop�����ݵ��뵼������
Flume����־���ݲɼ����
2 �ֲ�ʽϵͳ����
ע�����ڴ����ݼ�������ĸ��༼����ܻ����϶��Ƿֲ�ʽϵͳ����ˣ�����hadoop��storm��spark�ȼ�����ܣ�����Ҫ�߱������ķֲ�ʽϵͳ����
2.1 �ֲ�ʽ����ϵͳ(Distributed Software Systems)
- ������ϵͳ�Ữ�ֳɶ����ϵͳ��ģ�飬���������ڲ�ͬ�Ļ����ϣ���ϵͳ��ģ��֮��ͨ������ͨ�Ž���Э����ʵ�����յ����幦��
- ����ֲ�ʽ����ϵͳ���ֲ�ʽ����������Լ������(����)ϵͳ���ֲ�ʽ�ļ�ϵͳ�ͷֲ�ʽ���ݿ�ϵͳ�ȡ�
2.2 �ֲ�ʽ����ϵͳ������solrcloud
- һ��solrcloud��Ⱥͨ���ж�̨solr������
- ÿһ��solr�������ڵ㸺��洢��������������ɸ�shard�����ݷ�Ƭ��
- ÿһ��shard���ж�̨������������ɸ�������Ϊ������
- �����Ľ����Ͳ�ѯ����������Ⱥ�ĸ����ڵ��ϲ���ִ��
- solrcloud��Ⱥ��Ϊ�������������ڲ�ϸ�ڿɶԿͻ�����
�ܽ���ö���ڵ㹲ͬЭ�����һ���������ҵ���ܵ�ϵͳ���Ƿֲ�ʽϵͳ��
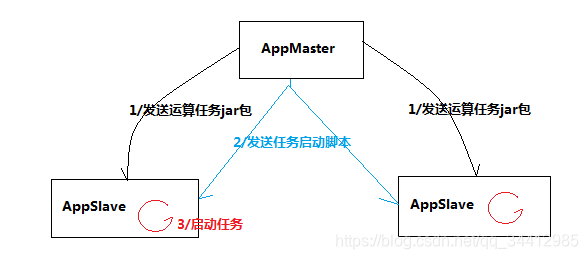
2.3 �ֲ�ʽӦ��ϵͳģ���
��������ʵ�������ڵ㽫�����������ӽڵ㣬�������ӽڵ��ϵ�����������
�����嵥��
AppMaster
AppSlave/APPSlaveThread
Task
�������������̣�
3. �������ݷ������̽���
ע����������Ҫ�������ݷ���ϵͳ�ĺ�۸���������̣���������hadoop�ȿ�������е�Ӧ�û��ڣ����ù��ڹ�ע����ϸ��
һ��Ӧ�ù㷺�����ݷ���ϵͳ����web��־�����ھ�
3.1 �������
3.1.1 ��������
����վ��APP�������־�����ھ�ϵͳ��[M2] ��
3.1.2 ������������
��Web�������־����������վ��Ӫ����Ҫ����Ϣ��ͨ����־���������ǿ���֪����վ�ķ��������ĸ���ҳ����������࣬�ĸ���ҳ���м�ֵ�����ת���ʡ��ÿ͵���Դ��Ϣ���ÿ͵��ն���Ϣ�ȡ�
3.1.3 ������Դ
��������������Ҫ���û��ĵ����Ϊ��¼
��ȡ��ʽ����ҳ��Ԥ��һ��js����Ϊҳ������Ҫ�����ı�ǩ���¼���ֻҪ�û�������ƶ�����ǩ�����ɴ���ajax����̨servlet������log4j��¼���¼���Ϣ���Ӷ���web��������nginx��tomcat�ȣ����γɲ�����������־�ļ���
���磺
| 58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0" |
3.2 ���ݴ�������
3.2.1 ����ͼ����
�����������͵�BIϵͳ�������ƣ������������£�
���ǣ����ڱ�������ǰ���Ǵ����������ݣ�����������и�������ʹ�õļ��������ͳBI��ȫ��ͬ�������γ̶���һһ���⣺
- ���ݲɼ������ƿ����ɼ�����ʹ�ÿ�Դ���FLUME
- ����Ԥ���������ƿ���mapreduce����������hadoop��Ⱥ
- ���ݲֿ⼼��������hadoop֮�ϵ�Hive
- ���ݵ���������hadoop��sqoop���ݵ��뵼������
- ���ݿ��ӻ������ƿ���web�����ʹ��kettle�Ȳ�Ʒ
- �������̵����̵��ȣ�hadoop��̬Ȧ�е�oozie�����������ƿ�Դ��Ʒ
3.2.2 ��Ŀ�����ܹ�ͼ
3.2.3 ��Ŀ��ؽ�ͼ��������ʶ�����ͼ��ɣ�
- Mapreudce��������
- ��Hive�в�ѯ����
- ��ͳ�ƽ������mysql
| ./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03 |
3.3 ��Ŀ����Ч��
�������������ݴ������̺��������������ͳ��ָ��ı�����������ʵ���У�������Ҫ����Щ���������Կ��ӻ�����ʽչ�ֳ���������������web������ʵ�����ݿ��ӻ�
Ч��������ʾ��
4. ��Ⱥ�
4.1 HADOOP��Ⱥ�
4.1.1��Ⱥ���
HADOOP��Ⱥ������˵����������Ⱥ��HDFS��Ⱥ��YARN��Ⱥ���������Ϸ��룬�������ϳ���һ��
HDFS��Ⱥ��
���������ݵĴ洢����Ⱥ�еĽ�ɫ��Ҫ�� NameNode / DataNode
YARN��Ⱥ��
��������������ʱ����Դ���ȣ���Ⱥ�еĽ�ɫ��Ҫ�� ResourceManager /NodeManager
(��mapreduce��ʲô�أ�����ʵ��һ��Ӧ�ó�����)
����Ⱥ���������5�ڵ�Ϊ�����д����ɫ�������£�
| hdp-node-01 NameNode SecondaryNameNode hdp-node-02 ResourceManager hdp-node-03 DataNode NodeManager hdp-node-04 DataNode NodeManager hdp-node-05 DataNode NodeManager |
����ͼ���£�
4.1.2��������
������ʹ����������������HADOOP��Ⱥ�������������汾��
- Vmware 11.0
- Centos 6.5 64bit
4.1.3���绷����
- ����NAT��ʽ����
- ���ص�ַ��192.168.125.2
- 3���������ڵ�IP��ַ��192.168.125.128��192.168.125.129��192.168.125.130��192.168.125.131
- �������룺255.255.255.0
4.1.4������ϵͳ����
- ����HADOOP�û�
- ΪHADOOP�û�����sudoerȨ��
- ͬ��ʱ��
- ����������
- mini1
- mini2
- mini3
- mini4
- ������������ӳ�䣺
- 192.168.125.128 mini1
- 192.168.125.129 mini2
- 192.168.125.130 mini3
- 192.168.125.131 mini4
- ����ssh���ܵ�½
- ���÷���ǽ
4.1.5 Jdk������װ
- �ϴ�jdk��װ��
- �滮��װĿ¼ /home/hadoop/apps/jdk_1.7.65
- ��ѹ��װ��
- ���û������� /etc/profile
4.1.6 HADOOP��װ����
- �ϴ�HADOOP��װ��
- �滮��װĿ¼ /home/hadoop/apps/hadoop-2.6.4
- ��ѹ��װ��
- �������ļ� $HADOOP_HOME/etc/hadoop/
����������£�
vi hadoop-env.sh
| # The java implementation to use. export JAVA_HOME=/home/hadoop/apps/jdk1.7.0_51 |
vi core-site.xml hdfs gfs tfs nfs ����fs������ value��uri=schema
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mini1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hdpdata</value> hadoop��������Ŀ¼��������id����tmpĿ¼������ </property> </configuration> |
vi hdfs-site.xml
| <configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/data</value> </property>
<property> <name>dfs.replication</name> <value>3</value> </property>
<property> <name>dfs.secondary.http.address</name> <value>hdp-node-01:50090</value> </property> </configuration> |
vi mapred-site.xml
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
vi yarn-site.xml
| <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property>
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
�ַ�2.3.4�ڵ㣺[hadoop@mini1 ~]$ scp -r apps mini2:/home/hadoop/
���û���������/etc/profile��
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH ��ͨ�������������
vi salves ����ӵĶ���datanode�ڵ�
| mini2 mini3 mini4 |
4.1.7 ������Ⱥ
��ʼ��HDFS
| bin/hadoop namenode -format |
�����Ϣ���沿�ֳ��ֱ�ʾ��ʽ���ɹ���Storage directory /home/hadoop/apps/hdpdata/dfs/name has been successfully formatted.
hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode
��־�ļ�/home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-datanode-mini4.log
����HDFS
| sbin/start-dfs.sh |
����YARN
| sbin/start-yarn.sh |
4.1.8 ����
1���ϴ��ļ���HDFS
�ӱ����ϴ�һ���ı��ļ���hdfs��/wordcount/inputĿ¼��
| [HADOOP@hdp-node-01 ~]$ HADOOP fs -mkdir -p /wordcount/input [HADOOP@hdp-node-01 ~]$ HADOOP fs -put /home/HADOOP/somewords.txt /wordcount/input |
2������һ��mapreduce����
��HADOOP��װĿ¼�£�����һ��ʾ��mr����
| cd $HADOOP_HOME/share/hadoop/mapreduce/ hadoop jar mapredcue-example-2.6.1.jar wordcount /wordcount/input /wordcount/output |
5 ��Ⱥʹ�ó���
5.1 HDFSʹ��
1���鿴��Ⱥ״̬
��� hdfs dfsadmin �Creport
���Կ�������Ⱥ����3��datanode����
Ҳ�ɴ�web����̨�鿴HDFS��Ⱥ��Ϣ�����������http://hdp-node-01:50070/
2���ϴ��ļ���HDFS
- �鿴HDFS�е�Ŀ¼��Ϣ
��� hadoop fs �Cls /
hadoop fs -help
- �ϴ��ļ�
��� hadoop fs -put ./ scala-2.10.6.tgz to /
- ��HDFS�����ļ�
��� hadoop fs -get /yarn-site.xml
5.2 MAPREDUCEʹ��
mapreduce��hadoop�еķֲ�ʽ�����̿�ܣ�ֻҪ�������̹淶��ֻ��Ҫ��д������ҵ�������뼴��ʵ��һ��ǿ��ĺ������ݲ�����������
5.2.1 Demo��������wordcount
1������
�Ӵ���������T�����ı��ļ��У�ͳ�Ƴ�ÿһ�����ʳ��ֵ��ܴ���
2��mapreduceʵ��˼·
Map�Σ�
- ��HDFS��Դ�����ļ������ж�ȡ����
- ��ÿһ�������зֳ�����
- Ϊÿһ�����ʹ���һ����ֵ��(���ʣ�1)
- ����ֵ�Է���reduce
Reduce�Σ�
- ����map������ĵ��ʼ�ֵ��
- ����ͬ���ʵļ�ֵ�Ի�۳�һ��
- ��ÿһ�飬�������е����С�ֵ�����ۼ���ͣ����õ�ÿһ�����ʵ��ܴ���
- ��(���ʣ��ܴ���)�����HDFS���ļ���
- �������ʵ��
(1)����һ��mapper��
| //����Ҫ�����ĸ����͵����� //keyin: LongWritable valuein: Text //keyout: Text valueout:IntWritable
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ //map�������������ڣ� ���ÿ��һ�����ݾͱ�����һ�� //key : ��һ�е���ʼ�����ļ��е�ƫ���� //value: ��һ�е����� @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //�õ�һ������ת��Ϊstring String line = value.toString(); //����һ���зֳ��������� String[] words = line.split(" "); //�������飬���<���ʣ�1> for(String word:words){ context.write(new Text(word), new IntWritable(1)); } } } |
(2)����һ��reducer��
| //�������ڣ����ÿ���ݽ���һ��kv �飬reduce����������һ�� @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //����һ�������� int count = 0; //������һ��kv������v���ۼӵ�count�� for(IntWritable value:values){ count += value.get(); } context.write(key, new IntWritable(count)); } } |
(3)����һ�����࣬��������job���ύjob
| public class WordCountRunner { //��ҵ������ص���Ϣ���ĸ���mapper���ĸ���reducer��Ҫ�������������������Ľ�������������������������һ��job���� //����������õ�job�ύ����Ⱥȥ���� public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //ָ�������job���ڵ�jar�� // wcjob.setJar("/home/hadoop/wordcount.jar"); wcjob.setJarByClass(WordCountRunner.class);
wcjob.setMapperClass(WordCountMapper.class); wcjob.setReducerClass(WordCountReducer.class); //�������ǵ�ҵ����Mapper������key��value���������� wcjob.setMapOutputKeyClass(Text.class); wcjob.setMapOutputValueClass(IntWritable.class); //�������ǵ�ҵ����Reducer������key��value���������� wcjob.setOutputKeyClass(Text.class); wcjob.setOutputValueClass(IntWritable.class);
//ָ��Ҫ�������������ڵ�λ�� FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt"); //ָ���������֮��Ľ���������λ�� FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/"));
//��yarn��Ⱥ�ύ���job boolean res = wcjob.waitForCompletion(true); System.exit(res?0:1); } |
5.2.2 ����������
- ��������
- ����������
vi /home/hadoop/test.txt
| Hello tom Hello jim Hello ketty Hello world Ketty tom |
��hdfs�ϴ������������ļ��У�
hadoop fs mkdir -p /wordcount/input
��words.txt�ϴ���hdfs��
hadoop fs �Cput /home/hadoop/words.txt /wordcount/input
- ������jar���ϴ�����Ⱥ������һ̨��������
- ʹ����������ִ��wordcount����jar��
$ hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver /wordcount/input /wordcount/out
- �鿴ִ�н��
$ hadoop fs �Ccat /wordcount/out/part-r-00000
HADOOP��hdfs��MAPREDUCE��yarn�� Ԫ�ϼ������ݴ���������ܣ��ó��������ݷ���
Zookeeper �ֲ�ʽЭ������������
Hbase �ֲ�ʽ�������ݿ������߷���������ҵ��ͨ��
Hive sql ���ݲֿ�ߣ�ʹ�÷��㣬���ܷḻ������MR�ӳٴ�
Sqoop���ݵ��뵼������
Flume���ݲɼ����
һ�����͵���վ(10W��PV����)��ÿ������1G����Web��־�ļ������ͻ��͵���վ������ÿСʱ�ͻ����10G����������
������˵������ij����������վ�������Ź�ҵ��ÿ��PV��100w������IP��5w���û�ͨ���ڹ���������10:00-12:00������15:00-18:00����������ռ���Ҫ��ͨ��PC����������ʣ���Ϣ�ռ�ҹ��ͨ���ƶ��豸���ʽ϶ࡣ��վ�������ռ������վ��80%��PC�û�����1%���û������ѣ��ƶ��û���5%�����ѡ�
������־�����ֹ�ģ�����ݣ���HADOOP������־�����������ʺϲ������ˡ�