AI科技评论按:2017 年 4 月 21-23 日,VALSE(视觉与学习青年学者研讨会)在厦门举行,国内 CV 领域顶级专家学者齐聚一堂,参会的青年学者达 2000 多人。在 VALSE 的「年度进展评述」环节,共有 12 名学者依次上台,对 CV 研究和应用分支领域近年发展做了详细系统的梳理,堪称「12 颗重磅炸弹」。针对近年来 CV 领域火热的方向之一:GAN,哈尔滨工业大学计算机学院教授左旺孟从多方面做了详尽的评述报告。
生成对抗网络是过去一年来得到很多关注的一个方向,里面的内容比较庞杂。那么我选择了以下几个角度,来概括过去几年来 GAN 的发展脉络。
图像生成
关于 GAN 的三个问题:度量复杂分布之间差异性、如何设计生成器、建立输入和输出之间的联系。
图像生成
这里尝试给「图像生成」一个大致定义:图像生成的目的是,学习一个生成模型,能够将来自于输入分布的一幅图像或变量转变成为一幅输出图像。这里,我们不仅要求「输入」满足一个输入分布,同样,我们还要求「输出」满足一个预期的期望分布。通过定义不同的输入分布和期望分布,就对应着不同的图像生成问题。

一开始,最标准的 GAN 的假设是,输入要服从随机噪声分布,期望分布是所有的真实图像。这个问题一开始定义得太大,所以虽然 GAN 在2014年就出现了,在2014年到2016年这段时间其实发展得并不快。
后来大家就去思考,输入的分布也可以不是随机分布,于是大家开始根据各种实际问题的需要来定义自己需要的输入分布和期望分布。比如,输入分布可以是来自于所有斑马的一幅图像,输出分布是所有正常马的图像,这样系统要学习的其实是这两种图像之间的映射(mapping)。

同样,如果我们输入的是一个低分辨率图像,输出的是一个高分辨率图像,那么希望系统学习到的是低分辨率和高分辨率之间的映射。去区块(deblocking),输入的是 JPEG 压缩图像,输出的是真实高清图像,我们也是希望学到两者之间的映射。人脸领域也是一样,比如我们做的超分辨和性别转换。输入是男性图像,输出是女性图像,学习二者之间的映射。

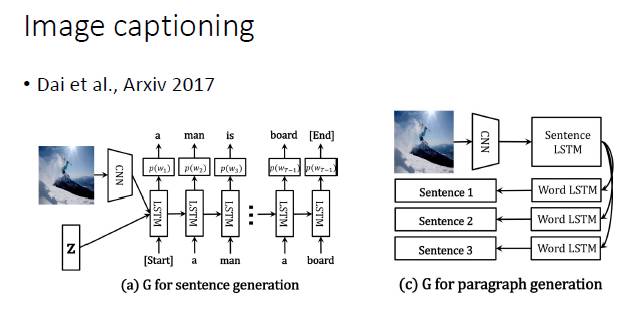
另外一个有意思的是图像文本描述的自动生成(Image captioning),输入的是图像,输出的是句子。大家以前就认为,这是一个一对一的映射,其实不是。它实际上是一对多的映射。不同的人来描述一幅图,就会产生不同的语句。所以如果用 GAN 来做这件事情,应该是很有趣的,今年有几篇投 ICCV 的文章做的就是这方面的工作。

关于GAN的三个问题
第一,度量复杂分布之间差异性。我们希望输出分布达到期望分布,那么我们需要找两个分布之间差异的度量方式,这是我认为在 GAN 里面需要研究的第一个关键性问题。
第二,如何设计生成器。如果我们想要学习映射,就需要一个生成器,那么就要对它的训练、可学习性进行设计。这是 GAN 里面另一个可以研究的角度。
第三,连接输入和输出。如下图右边性别转换的例子,输入是一张男性图像,输出是一张女性图像。显然我们需要的并不是从输入到任意一幅女性人脸图像的映射,二是要求输出的女性图像要跟输入的男性图像尽可能像,这个转换才是有意义的。所以,这就是 GAN 里面另外一个重要的研究方向,就是如何将输入和输出连接起来。

下面针对这三个问题,进行详细的讲解。
如何度量两个分布之间的差异性
GAN 使用了一个分类器来度量输出分布和期望分布的差异性。实际上,Torralba和Efros在 2011 年的时候也考虑过用一个分类器来分析两个分布之间差异,这也是当时做 domain adaption 的学者喜欢引用的一篇论文。他们设计了一个实验,给你三张图像,让你猜是来自 12 个数据集(包括 ImageNet、COCO和PASCAL VOC等)中的那一个。如果是随机猜的话,显然猜中的概率是 1/12。但是人猜中的准确度往往能达到 30% 左右,说明不同数据集刻画的分布是不一致的。这里人其实可视为一个分类器,通过判断样本来自于那个数据集来分析两个分布之间差异性。
虽然 NIPS 2014 年的这篇 GAN 论文没有引用 Torralba 的工作,其实它也是采用了一个判别器来度量两个分布的差异化程度。基本的过程是,固定生成器,得到一个最好的判别器,再固定判别器,学到一个最好的生成器。但是其中有一个最令人担心的问题,那就是如果我们学到的是一个很复杂的分布,就会出现模式崩溃(Mode Collapse)的问题,即无法学习复杂分布的全局,只能学习其中的一部分。

对此,最早的解决方案,是调整生成器(G)和判别器(D)的优化次序,但这也不是一个终极方案。从去年开始大家开始关注要去找到一个终极解决方案。
那之前,大家怎么去解决这个问题呢?使用的是原来机器学习里常用的方法:最大化均值差异(Maximum Mean Discrepancy,MMD)。
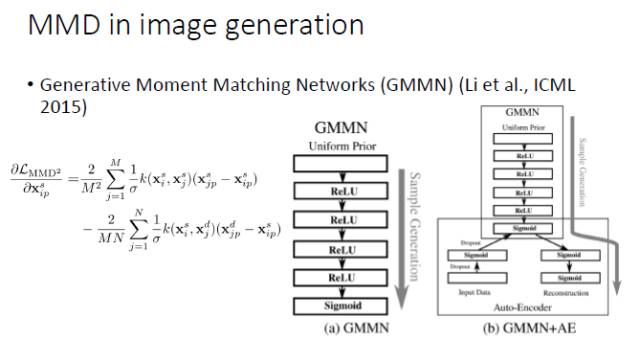
如果两个分布相同的话,那么两个分布的数学期望显然也应该相同;然而,如果两个分布的数学期望相同,并不能保证两个分布相同。因而,我们需要更好地建立「分布相同」和「期望相同」之间的连接关系。幸运的是,我们可以对来自于两个分布的变量施加同样的非线性变换。如果对于所有的非线性变换下两个分布的数学期望均相同(即:两个分布的期望的最大差别为0),在统计学意义上就可以保证两个分布是相同的。不幸的是,这种方法需要我们遍历所有的非线性变换,从实践的角度似乎任由一定难度。一开始,在机器学习领域,大家倾向于用线性 kernel或Gaussian RBF kernel 来进行非线性变换,后来开始采用 multi-kernel。从去年开始,大家开始用 CNN 来近似所有的非线性变换,在 MMD 框架下进行图像生成。首先,固定生成器并最大化 MMD,然后固定判别器里 MMD 的 f,然后通过最小化 MMD 来更新生成器。
最常用的一种方法,就是拿 MMD 来代替判别器,去学习一个 CNN,这是 ICML 2015 的一篇文章中尝试的方法,我们自己也在这个基础上做了一些工作。
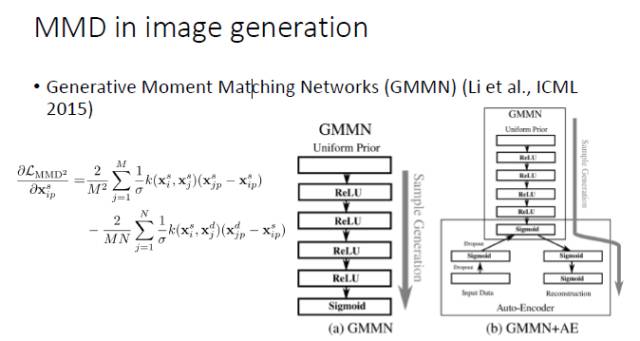
但实际上,如果直接拿 MMD 去替换生成器,虽然有一定效果,但不是特别成功。所以,从 NIPS 2016 开始,就出现了一个 Improved GAN,这个工作虽然没有引用 MMD 的论文,但实际上在更新判别器的同时也最小化了 MMD。等到了 Wasserstein GAN 的时候,它就明确解释了与 MMD 之间的联系,虽然论文里写的是一个「减」的关系,但我们看它的代码,它也是要加上一个范数的,因为只是让两个分布的期望最大化或最小化都不能保证分布的差异化程度最小。
然后,最近 ICLR 2017 的一篇论文也明确指出要用 MMD 来作为 GAN 网络的停止条件和学习效果的评价手段。

如何设计一个生成器
这个部分相对来说就比较容易一些。早期的时候,GAN 的一个最大的进步就是 DCGAN,用于图像生成时,比较合适的选择就是用全卷积网络加上 batch normalizaiton。

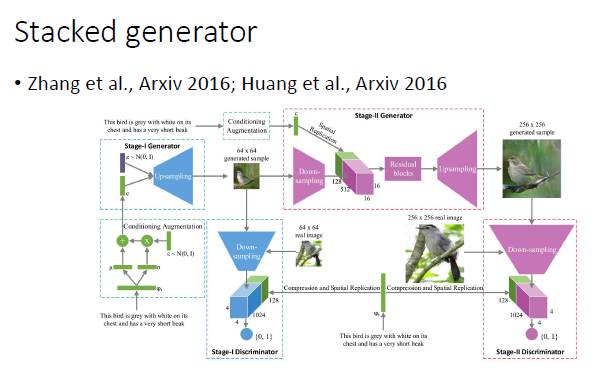
对于复杂的图像生成,可以使用分阶段的方式。比如,第一步可以生成小图,然后由小图生成大图。沿着这个方向,香港中文大学王晓刚老师和康奈尔大学 John Hopcroft 都做了一些工作。
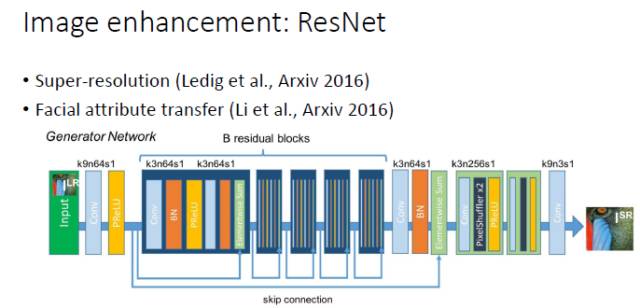
对于图像增强(image enhancement)相关的一些任务,包括超分辨率和人脸属性转换(Face Attribute Transfer),目前在有监督时表现最好网络是 ResNet ,所以我们在这些任务中实用GAN时一般也会采用 ResNet 结构。
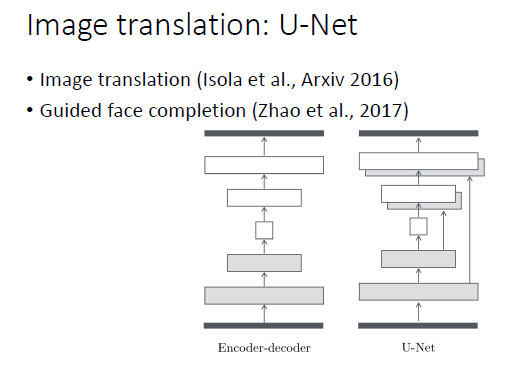
同样,对于图像转换(image translation),基本上用的是 U-Net 结构。我们在做基于引导图像的人脸填充(guided face completion)时也采用了 U-Net 结构。
对于图像文本描述的自动生成,显然应该采用 CNN+RNN 这样的网络结构。总而言之,一个比较好的建议就是根据任务的特点和前任的经验来设计生成器网络。
如何连接输入和输出
如何通过连接输入和输出的方式来改善 GAN 的可学习性,这个问题是从 NIPS 2016 开始得到了较多的关注,同时这也是我自己非常感兴趣的一个方向。比较早的一个工作就是 InfoGAN,其特点就是输入包括两个部分:C(隐变量)和 Z(噪声)。InfoGAN 生成图像之后,不仅要求生成图像和真实图像难以区分,还要求能够从生成图像中预测出 C,这样就为输入和输出建立起了一个联系。

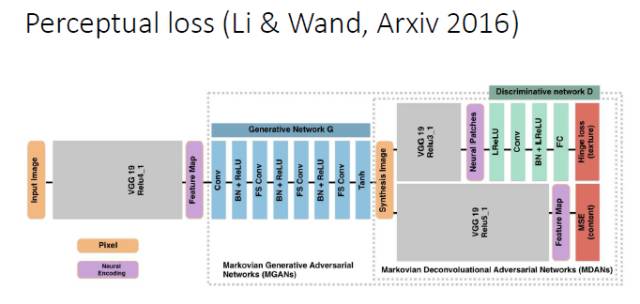
另外针对一些任务,比如超分辨,可以用 Perceptual loss 的方式来建立输入和输出的联系。
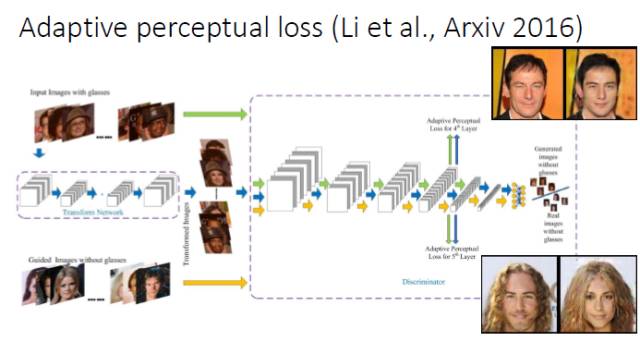
我们在做人脸属性转换时发现,现有的 Perceptual loss 往往是定义在一个现有的网络基础上的,我们就想能不能把 Perceptual loss 网络和判别器结合起来,所以就提出了一个 Adaptive perceptual loss。结果表明Adaptive perceptual loss能够具有更好的自适应性,能够更好地建立输入和输出的联系和显著改善生成图片的视觉效果。
当输入和输出都是已知时(比如图像超分辨和图像转换),要用什么方式来连接输入和输出呢?以前是用 Perceptual loss 来连,现在更好的方式是用 Conditional GAN。假设有一个 Positive Pair(输入和groundtruth图像)和 Negative Pair(输入和生成图像),那么判别器就不是在两幅图像之间做判别,而是在两个「Pair」之间做判别。这样的话,输入就很自然地引入到了判别器中。

在此基础上,我们还考虑了当有一些额外的 Guidance 时,如何来更好地建立输入和输出的联系。
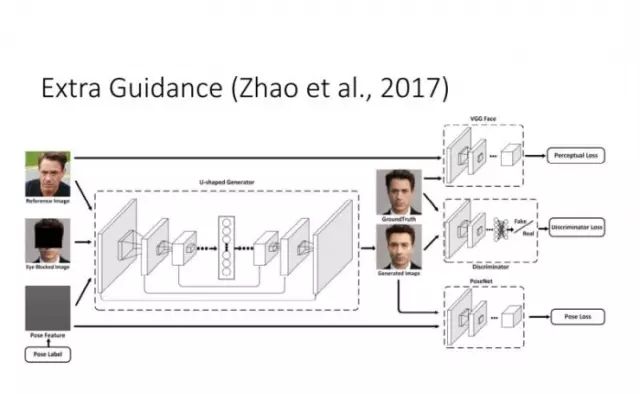
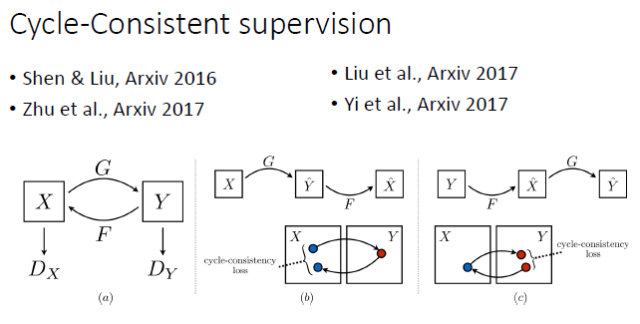
上面提到,在有监督的情况下 Conditional GAN 是一个比较好的选择。但如果在 unpair 的情况下做图像转换,要如何建立输入和输出的联系?谭平老师他们组和Efros组今年就做了这方面的工作,其实去年投 CVPR2017 的一篇论文也做了类似的工作。我们知道,由于是unpair的,原则上训练阶段输入和输出不能直接建立联系。这时他们采用的是一种 Cycle-Consistent 的方式。从 X 可以预测和生成 Y,再从 Y 重新生成 X',那么由 Y 生成的 X' 就能跟输入的 X 建立联系。这样的话,我们实际上相当于隐式地建立了从 X 到 Y 的联系。
总结
如果大家对于 GAN 的理论和模型比较感兴趣,可以从输出分布和期望分布之间的差异化程度度量入手。如果你比较在乎GAN的应用,可以从后两个方面着手,通过设计生成器和建立输入和输出之间的联系,来解决自己感兴趣的问题。我的报告基本上就是这些,谢谢大家。