��ƪ������Ҫ�������ع鱳���һЩ���ʸ������һЩֱ�۸о��������Ĵ��ۺ�����������������Ҳ�����˹��������Ȼ���ƣ�maximum likelihood���ĸ�������ǿ��Ĺ������������ع��cost���������ţ�����scikit-learnѵ���˸�֪��ģ����������Ϥscikit-learn�������scikit-learn��ѵ�����ع飬���������߽߱�ͼ��Ч�����㲻����
������(logistic function)
Ϊ�˸��õؽ������ع飬�����������˽�һ������������������������S�Σ���ʱҲ����Ϊsigmoid������
������Ҫ�����ֵ�ȣ�odds ratio���ĸ�������Ա�д��p(1?p)�����е�p�������¼���positive event���ĸ��ʣ����¼������Ǵ����õķ���ĸ��ʣ����Ǵ���������ҪԤ����¼������磺���˻���ij�ּ����ĸ��ʡ����ǰ����¼������ǩ����Ϊ1����ֵ�ȵĶ�����ΪLogit������������д��������ʽ��
���ĺ���ͼ�����£�
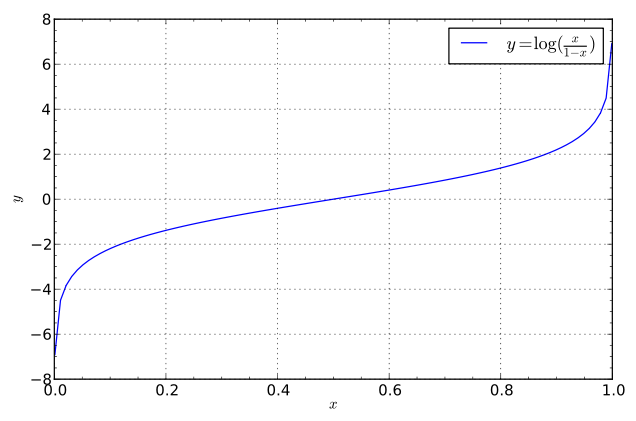
ͼƬ��Դ https://en.wikipedia.org/wiki/Logit#/media/File:Logit.svg
��ͼ�������ǿ��Կ�����logit��������0��1��ֵ��������ת��Ϊ����ʵ����Χ�ڵ�ֵ�������p�������¼��ĸ��ʣ�����ڸ�����������x�������£����y=1�ĸ��ʿ���д��P(y=1|x)����Ҷ�֪�����ʵķ�ΧΪ0��1������Ұ�������ʴ��ݸ�logit������ô���������Χ������ʵ��������������ijЩ���ʵ�Ȩ������w��������������x���������µ�ʽ��
������ʵ��Ӧ���У����Ǹ��������P(y=1|x)����ˣ�������Ҫ�ҵ�logit�����ķ�������ͨ��������Ȩ������w����������x�������������Ҫ֪�������¼��ĸ��ʣ���P(y=1|x)��������������������ǵ�sigmoid������������д��S(h)=11+e?h����ʽ�е�hΪ����������Ȩ�ص�������ϣ�����w0x0+w1x1+?+wnxn�����������������������ͼ������ӣ�
import matplotlib.pyplot as plt
import numpy as npdef sigmoid(h):return 1.0 / (1.0 + np.exp(-h))h = np.arange(-10, 10, 0.1) # ����x�ķ�Χ������Ϊ0.1
s_h = sigmoid(h) # sigmoidΪ���涨��ĺ���
plt.plot(h, s_h)
plt.axvline(0.0, color='k') # ���������ϼ�һ����ֱ���ߣ�0.0Ϊ��ֱ�����������ϵ�λ��
plt.axhspan(0.0, 1.0, facecolor='1.0', alpha=1.0, ls='dotted') # ��ˮƽ���ͨ��������
plt.axhline(y=0.5, ls='dotted', color='k') # ��ˮ��ͨ��������
plt.yticks([0.0, 0.5, 1.0]) # ��y��̶�
plt.ylim(-0.1, 1.1) # ��y�᷶Χ
plt.xlabel('h')
plt.ylabel('$S(h)$')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
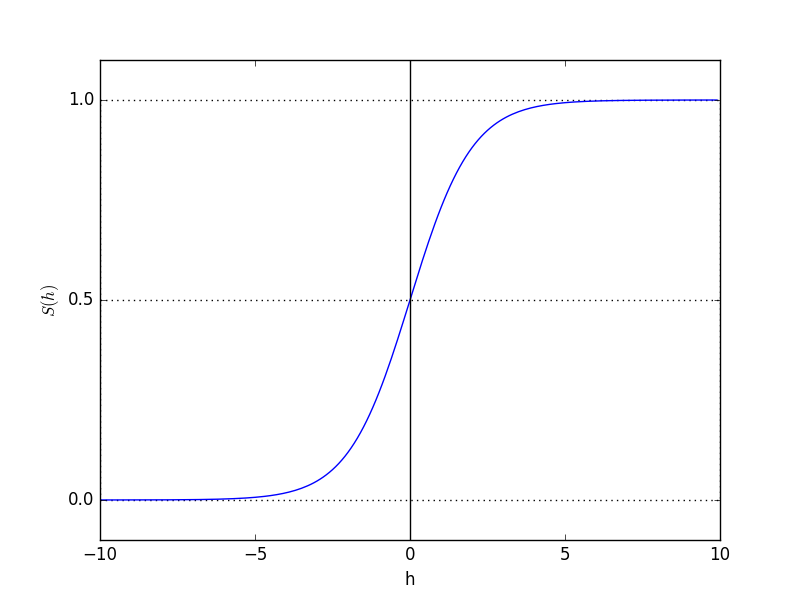
����ͼ���ǿ��Կ�����������������ʵ����Χ�����룬���0��1֮�������
���S(w0x0+w1x1+?+wnxn)=P(y=1|x;w)������������ǿ��Խ��ͳɣ�������Ȩ��w�������������x�������������1�ĸ��ʡ�ͨ����Ծ������step function�������ǿ��Եõ����¹�ʽ��
����һ���ȼ۵Ĺ�ʽ���£�
ʵ���ϣ��ܶ�Ӧ�ò�ֻ��������õ�һ�����ǩ�������������ij�����ĸ��ʡ��������ع���������ģ����������Ǹ������Ƿ��м��������Ǹ������ж����ʻ������������
����������ӵ��У�����һֱ������Ȩ��w�ij��֣���ô�������ѧϰ����ѵ�Ȩ��w�أ��ڸ������֮ǰ���������ȸ�ϰһ�������Ȼ���ƣ�maximum likelihood���ĸ��
�����Ȼ���ƣ�maximum likelihood��
��������ı��ʾ��ǣ�ѡ����ѵIJ���ֵw������������������ݵĿ����ԡ�
�������Ǹ�������X1,X2,X3,��,Xn����ô�ҿ���д��һ�����ڲ���w�Ŀ����Ժ��������£�
ʵ���ϣ������Ժ�����������������Ϊ����w�ĺ����ĸ��ʡ�
���X1,X2,X3,��,Xn�֮���Ƕ����ģ������Ժ������Լ�������ʽ��
���ǣ���������кܶ�����������أ���ʱ����ͻ���Ϻܶ����Щ��ͨ������С�������Ժ����ͻ��ú�С����ˣ���Ӧ�ò���log�����Ժ�������һ������ڿ����Ժ�С��ʱ�������Է�ֹDZ�ڵ���ֵ����;�ڶ������ǰѳ˻�ת��Ϊ��ͣ������ʹ���Ǹ���������ú����ĵ�����������log�����ǵ����ģ�������Ժ�����ֵҲ�������log�����Ժ�����ֵ��log�����Ժ�����ʽ���£�
���棬�Ҿ�2��������Ӧ��һ�����ǿ��Ĺ��ߣ�
1��������ڴ�����2öӲ�ң�1öӲ�ҳ�������ĸ���Ϊp=0.5����1öӲ�ҳ�������ĸ���Ϊp=0.8��������ӿڴ�������ó�һöӲ�ң��㲢��֪���õ�����öӲ�ң���Ȼ�����Ͷ��4�Σ�����3�����棬1�η��档��������ó�������öӲ�ң�������öӲ�ҵ������Ȼ���Ƹ���
��ͨ���������ǿ��Եó���������ڶ���ֲ������ĸ���ΪP(x|n,p)=(nx)px(1?p)n?x.���ڣ�������д��log�����Ժ�����
l(p)=log((43)p3(1?p))
���������Ѿ�������p��ֵֻ��Ϊ0.5��0.8����ˣ����Dz���������� p��ֵ������ԡ���������ֻ��Ҫ������ pֵ��������ˣ��ֱ�ó����½����
l(0.5)=?0.6021
l(0.8)=?0.3876
��˵� pΪ0.8ʱ��ʹ�����Ժ������������Ҹ������ó������������Ϊ p=0.8��Ӳ�ҡ�
2������Xi?N(��,��2)�������֮���Ƕ����ġ������Ѳ�����
��log�����Ժ������£�
l(��,��2)=��i=1nlog[1��2��??��exp(?(Xi?��2)2��2)]=?��i=1nlog(��)?��i=1nlog(2��??��)?��i=1n[(Xi?��)22��2]=?nlog(��)?nlog(2��??��)?12��2��i=1n(Xi?��)2
��Ϊ�������ҵ����� ������ʹ�ÿ����Ժ���������������Ҫ�ҵ����ǵ�ƫ����
?l(��,��2)?��=??��(?nlog(��)?nlog(2��??��)?12��2��i=1n(Xi?��)2)=?1��2��i=1n(Xi?��)
?l(��,��2)?��2=??��2(?n2log(��2)?nlog(2��??��)?12(��2)?1��i=1n(Xi?��)2)=?n2��2+12(��2)?2��i=1n(Xi?��)2
������ƫ��������0,Ȼ�������Ѳ�����
��=1n��i=1nXi=X?
��2=1n��i=1n(Xi?��)2
�����������Ȼ���ƣ�������Ϳ���֪�����ع�cost�����������ˡ�
���ع��cost����
���ڣ����ǿ����ÿ����Ժ��������������Ȩ��w�ˡ���ʽ���£�
���湫ʽ�е�hΪ���躯��w0x0+w1x1+?+wnxn��������ĺ������϶�������ʽ���£�
���ڣ����ǵ�Ŀ�������log�����Ժ������ҵ�һ����ѵ�Ȩ��w�����ǿ����������log�����Ժ���ǰ���ϸ��ţ����ݶ��½��㷨����С��������������ڣ��ҵõ������ع��cost�������£�
- n��ѵ������������
- S��sigmoid����
- h�����躯��
��������ֻ��һ���������������ǿ��������cost������ֳɷֶκ������£�
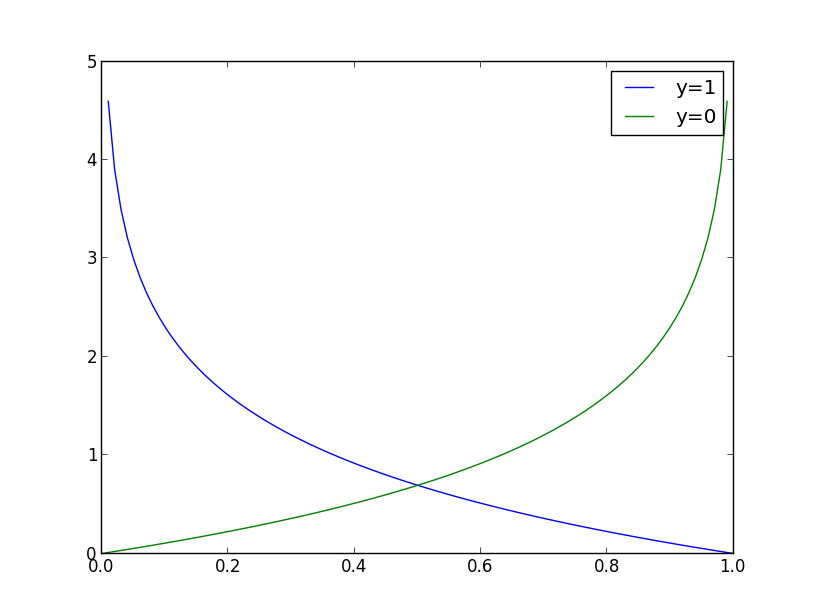
���ǰ����ع��cost����������ͼ�����ϡ���ʵ�����Ϊ1ʱ���������Ԥ��Ϊ1����Ҫ��С��cost���������Ԥ��Ϊ0����Ҫ�ܴ��cost;����������ʵ�����Ϊ0ʱ���������Ԥ��Ϊ0����Ҫ��С��cost���������Ԥ��Ϊ1����Ҫ�ܴ��cost
������һЩ�������ع����ϸ��һЩ����֪ʶ������Ȥ�Ŀ��Կ�����
http://czep.net/stat/mlelr.pdf
������Ҫ��scikit-learn�����ع������Iris���ݼ���
Iris���ݼ�����
���ȣ�����ȡ�����ݣ�������������������ݵ���ϸ���ܣ��������������ݼ���
https://archive.ics.uci.edu/ml/datasets/Iris
�����ݵ�˵���ϣ����ǿ��Կ���Iris��4��������3����𡣵��ǣ�����Ϊ�����ݵĿ��ӻ�������ֻ����2��������sepal length��petal length�����������ȿ������ݼ���ɢ��ͼ�ɣ�
���棬���ǽ���Ipython�����С�
import pandas as pd
import matplotlib.pyplot as plt
import numpy as npdf = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None) # ����Iris���ݼ���ΪDataFrame����
X = df.iloc[:, [0, 2]].values # ȡ��2������������������Numpy�����ʾplt.scatter(X[:50, 0], X[:50, 1],color='red', marker='o', label='setosa') # ǰ50��������ɢ��ͼ
plt.scatter(X[50:100, 0], X[50:100, 1],color='blue', marker='x', label='versicolor') # �м�50��������ɢ��ͼ
plt.scatter(X[100:, 0], X[100:, 1],color='green', marker='+', label='Virginica') # ��50��������ɢ��ͼ
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.legend(loc=2) # ��˵���������Ͻǣ�������ο��ٷ��ĵ�
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
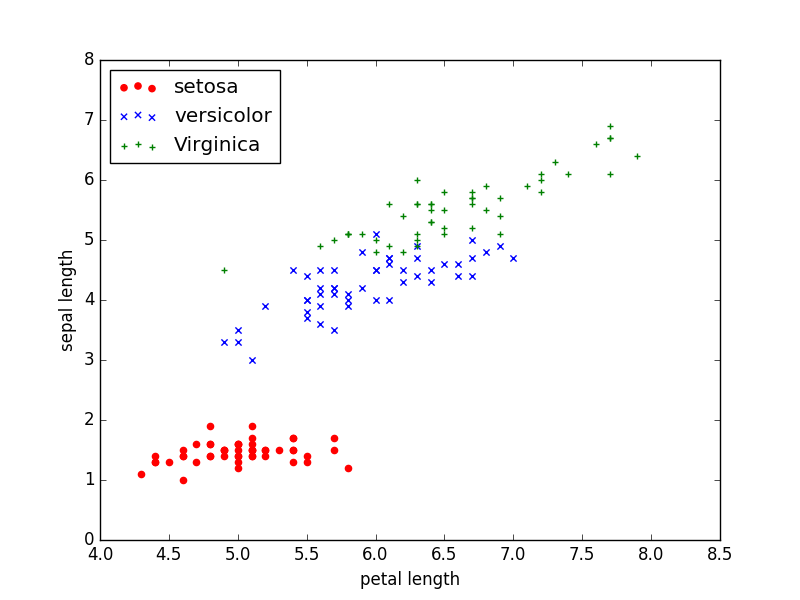
����ͼ���ǿ��Կ��������ݼ������Կɷֵġ�Ϊ�˸��õ���ʾЧ������ֻ��setosa��versicolor���������
������������Ҫ��ǿ���scikit-learn�����ģ�͡�
��ʶscikit-learn
��һЩ��Դ���Ѿ��ѻ���ѧϰ�㷨��װ���\���У������Ѿ����������˴����Ĺ�������ʵ��Ӧ���У�������Ҫ�Ĺ����Ƕ����ݵ�Ԥ��������ѡ���õ������������㷨������һЩ�㷨���Ƚ�����֮������ܡ�ѡ����õ�ģ�͡�����Ҳ����Ὠ�����Լ�ȥʵ����Щ����ѧϰ�㷨����ô����ܻ������ʣ���Ȼ�����Ѿ���ʵ���ˣ����ǻ��˽���Щ�㷨��ʲô�ã��ͺ��Ҹղ�˵��һ�������ǴֵĹ��������ڵ����㷨���ҵ�����õ����ܣ�����㲻�˽����ǵ�ԭ��������֪����ô����������
������Ҫ��scikit-learn��ѵ����֪��ģ�ͣ������˽�һ��scikit-learn��һЩ����������㲢���˽��֪��ģ�ͣ�perceptron���������ȥGoogleһ�£��кܶ�����������£�����㷨����ͳ����ˣ�Ҳ�ܼ�
����scikit-learn֮ǰ������Ҫ��װ����������ο�http://scikit-learn.org/stable/install.html
���棬������������scikit-learn��ǿ��ɣ�
from sklearn import datasets
import numpy as np
from sklearn.cross_validation import train_test_splitiris = datasets.load_iris() # ����Iris�Ǻ����������ݼ���scikit-learn�Ѿ�ԭ���Դ��ˡ�
X = iris.data[:, [2, 3]]
y = iris.target # ��ǩ�Ѿ�ת����0��1��2��
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Ϊ�˿�ģ����û�м������ݼ��ϵı��֣�����ó����ݼ���30%�IJ���������# Ϊ�������ѧϰ�����Ż��㷨��������ܣ����ǽ���������
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train) # ����ÿ��������ƽ��ֵ�ͱ���
sc.mean_ # �鿴������ƽ��ֵ������Iris����ֻ�����������������Խ����array([ 3.82857143, 1.22666667])
sc.scale_ # �鿴�����ı����������array([ 1.79595918, 0.77769705])
X_train_std = sc.transform(X_train)
# ע�⣺��������Ҫ��ͬ���IJ������������Լ���ʹ�ò��Լ���ѵ����֮���пɱ���
X_test_std = sc.transform(X_test)# ѵ����֪��ģ��
from sklearn.linear_model import Perceptron
# n_iter������������ݶ��½��е����Ĵ���
# eta0������������ݶ��½��е�ѧϰ��
# random_state������������ӵģ�Ϊ��ÿ�ε���������ͬ��ѵ����˳��
ppn = Perceptron(n_iter=40, eta0=0.1, random_state=0)
ppn.fit(X_train_std, y_train)# ������Լ����⽫����һ�����Խ��������
y_pred = ppn.predict(X_test_std)
# ����ģ���ڲ��Լ��ϵ�ȷ�ԣ��ҵĽ��Ϊ0.9��������
accuracy_score(y_test, y_pred)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
ע�⣺��������ѧϰ�ʹ����㷨���ܻ�Խ��ȫ����Сֵ�������غ����������п��ܷ�ɢ�����ѧϰ�ʹ�С���㷨��Ҫ�ܶ�ε����������������ʹѧϰ���̺�������
���ڹ������Ѿ�����˽�scikit-learn�ˣ���������������ʵ�����ع顣
scikit-learnʵ�����ع�
scikit-learn�����ع����кܶ���ڵIJ���������㲻̫��Ϥ����ο�������ĵ���
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
���棬�ҽ���scikit-learn��ѵ��һ�����ع�ģ�ͣ�
from sklearn import datasets
import numpy as np
from sklearn.cross_validation import train_test_splitiris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=1000.0, random_state=0)
lr.fit(X_train_std, y_train)
lr.predict_proba(X_test_std[0,:]) # �鿴��һ�������������ڸ������ĸ���
plot_decision_regions(X_combined_std, y_combined, classifier=lr, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
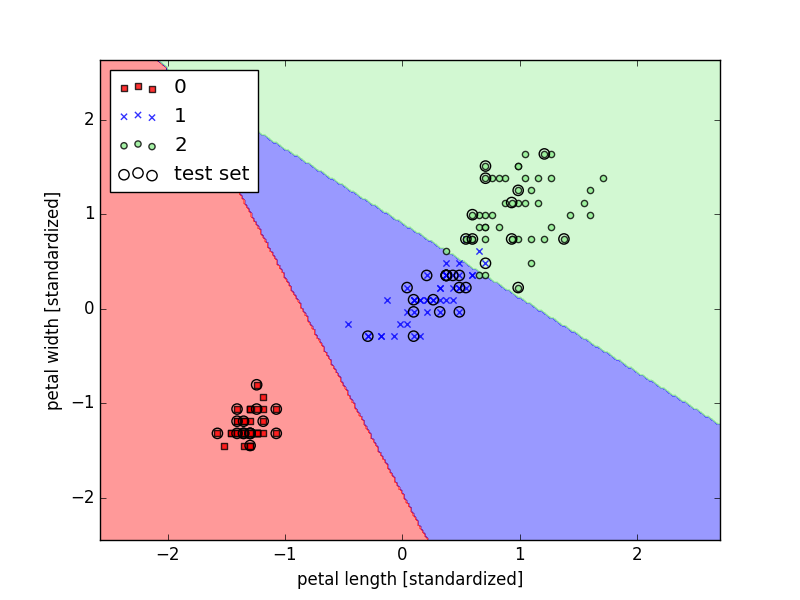
����ͼ���ǿ������ع�ģ�Ͱ����ܺõطֿ��ˡ�����һ������Ҫע����ǣ���������е�plot_decision_regions���������Լ�д�ģ�scikit-learn�в�û��������������Ѿ�����������ϴ���Github.
plot_decision_regions����