前言
??在进行机器学习的时候,本质上都是在训练模型,而训练模型都离不开对数据集的处理。往往在模型表现不佳或难以再提升的情况下,进行一定的处理,科学的训练会使模型再更进一步。
目录
- 前言
- 1 数据集划分
-
- 1.1 常规理解
- 1.2 自己理解
- 2 打乱(shuffle)
-
- 2.1 numpy里的shuffle
- 2.2 keras里的shuffle
- 2.3 sklearn里的shuffle ★
- 2.4 代码(2.1和2.3两种)
- 3 keras里进行K-折交叉验证
-
- 3.1 K-折交叉验证
- 3.2 keras模型实现K折交叉验证
- 3.3 完整代码
1 数据集划分
1.1 常规理解
??这是老生常谈的问题,但理论和实践还是会有偏差。理论上,数据集可划分为三类,训练集、验证集和测试集。引用cnn网络为什么有时验证集会和训练集一起参与训练?的一个理解,这三者的关系就如同刷题、模拟考和高考。刷题不能刷到模拟考题目,那模拟考直接起飞,高考题目不准看,看了考的分数就是假分数。
??下面开始盗图,参考训练集、验证集、测试集划分,从图中可以看出各部分之间的关系,其中训练集和测试集是大家经常听到的,而验证集在图中归属于训练集,这也是导致验证集和测试集经常混淆的点。
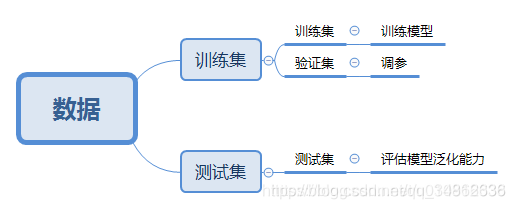

??参考中还给了不同数据集大小的情况下划分比例。
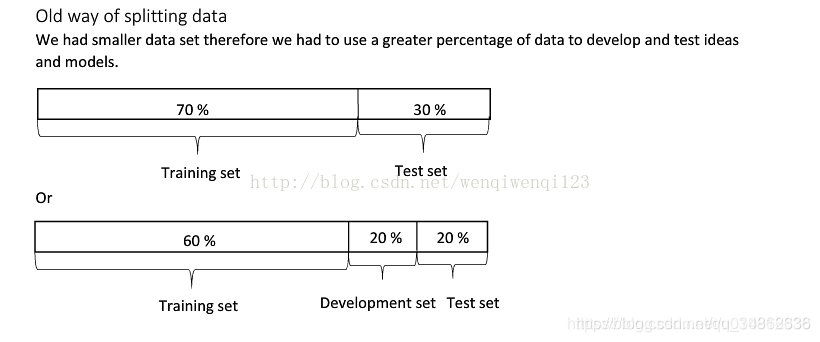
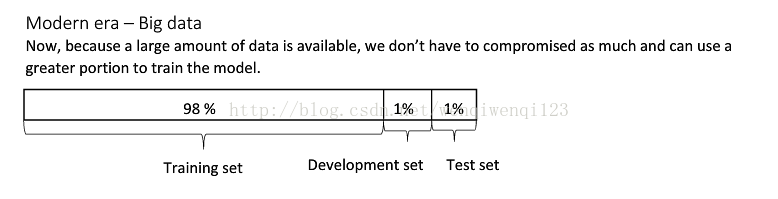
1.2 自己理解
??自己其实在之前的博客中也经常搞混,现在来说下自己的理解,不一定正确。其实我认为,在写论文、打比赛的时候,我们主要划分的还是训练集与验证集,测试集不属于考虑范围,或者认为测试集和验证集是一个东西。以打比赛为例,我们拿到了比赛的数据集,然后自己进行了数据集划分,对于模型训练来说,数据量一般越多越好,所以我们是划分训练集与验证集,在验证集效果较好时,再把验证集也拿去训练。那测试集呢?测试集其实是比赛官方拿出一部分数据集出来,用它来评估你的模型。因此对于比赛选手来说,专门拿出测试集来仅进行测试是不利的,而一旦测试完又拿去训练,那就变成验证集了。所以,我认为只有真正在工业环境下,才需要进行严格的划分。
2 打乱(shuffle)
??既然有数据集的划分,那么就少不了随机打乱。因为原本的数据集有可能是有序的,如果正例集中在前面,负例集中在后面,那么便会导致验证集或测试集会出现大部分是负例的情况。很有可能导致负例训练效果不佳,模型整体性能变差。此外,就算不是有序的,打乱也会显得更为“公平”,也给模型提升多一份机会。(即随机划分出的某个数据集可能更能代表整体数据(包括未收集到的数据))。
??那么接下来介绍shuffle的几种方式:numpy shuffle、keras fit里的shuffle以及sklearn shuffle。
??当你的数据集比较简单的时候,如特征与标签在一个numpy矩阵中,那么可以直接选用numpy里的shuffle。以鸢尾花数据集为例,该数据集本身是有序的,部分数据如下所示。

2.1 numpy里的shuffle
??该方法适合简单的矩阵,且特征和标签未分开。如果是分开的,还要先合并再拆开。
# In[*] shuffle in numpy
def shuffle_np(X,Y):Y = Y.reshape(len(Y),1)data = np.concatenate([X,Y],axis=-1)np.random.seed(1337)np.random.shuffle(data)print(data)X = data[:,:-1]Y = data[:,-1]return X,Y
??部分效果。

2.2 keras里的shuffle
??可参考Keras model.fit()参数详解,要注意这里的shuffle的解释是:

??但由于这是封闭的,看不到shuffle后的结果。其次,有很多博客说这个函数是个坑参考[keras中文文档笔记6――使用陷阱],因为fit函数往往先执行了validation_split再执行shuffle,参考[【私人笔记】深度学习框架keras踩坑记],意味着数据先被分割了再打乱,那么这个“打乱”可能并不能达到我们想要的效果,即仍会有负例全被分割在验证集,导致训练效果不佳的出现。
2.3 sklearn里的shuffle ★
??这个是目前我接触到最好用的shuffle,因为它既可以如2.1一样,打乱一个矩阵,也可以同时打乱两个变量组成的特征与标签,而且随机种子也集成了,总之就是省事。
from sklearn.utils import shuffle
X,Y = shuffle(X,Y, random_state=1337)

2.4 代码(2.1和2.3两种)
from sklearn import datasets
from keras.layers import *
import keras.backend as K
from keras import Model
from keras.utils import plot_model,to_categorical
import pandas as pd
import numpy as np
from keras.utils import plot_model
from sklearn.utils import shuffle
# In[*] get data
iris = datasets.load_iris()
X = np.array(iris['data'])
Y = np.array(iris['target'])# In[*] shuffle in numpy
def shuffle_np(X,Y):Y = Y.reshape(len(Y),1)data = np.concatenate([X,Y],axis=-1)np.random.seed(1337)np.random.shuffle(data)print(data)X = data[:,:-1]Y = data[:,-1]return X,Y# In[*] shuffle in sklearn
def shuffle_skl(X,Y):X,Y = shuffle(X,Y, random_state=1337) print(X,Y)return X,Y# In[*] build model
def build_model(fea_cnt,numb):K.clear_session() #清除之前的模型,省得压满内存inputs = Input(shape=(fea_cnt,), dtype='float32')embds = Dense(32 ,activation='selu')(inputs)outputs = Dense(numb,activation='softmax')(embds)model = Model(inputs=inputs, outputs=outputs)model.compile(loss='sparse_categorical_crossentropy', optimizer = 'sgd', metrics=['accuracy'])model.summary()return model# In[*] train model
fea_cnt = 4
numb = 3
model = build_model(fea_cnt,numb)
epochs = 12
batch_size = 4#X,Y = shuffle_np(X,Y)
X,Y = shuffle_skl(X,Y)model.fit(X,Y,batch_size = batch_size,epochs = epochs,validation_split= 0.2)
plot_model(model, to_file='./model.png',show_shapes=True,dpi=300) #输出框架图
3 keras里进行K-折交叉验证
3.1 K-折交叉验证
??稍微看一下概念会觉得很好理解,数据集拆成KKK分,K?1K-1K?1训练,111验证,轮换着组合,共有CKK?1=CK1=KC_{K}^{K-1}=C_{K}^1=KCKK?1?=CK1?=K次,KKK一般取5,10。但是更深刻的问题来了,最后得到的是1个模型还是KKK个模型?最终模型与KKK次训练的模型之间是什么关系?是直接选最好的吗?参考求解神经网络做十字交叉验证k=10,这种方法到底是得到十个模型还是一个模型。?
??我的理解是,一方面,K-折交叉验证目的是为了验证模型的性能,即避免实验出现的偶然性,用K次结果的平均值来代表此次模型的整体性能。另一方面,K-折最后K次的指标总会有高有低,那么我们可以选最优的那一个数据集的划分作为最终的划分,与shuffle一样,最优的数据集的划分说不定有更好的泛化效果。
3.2 keras模型实现K折交叉验证
??值得注意的是kfold也有shuffle参数,因此可以直接用。同样,这里仅展示快速实现,因此还是用鸢尾花,尽管这个数据量太少,训练出的模型不稳定。
# In[*] train model
fea_cnt = 4
numb = 3
epochs = 12
batch_size = 4
seed = 1337#X,Y = shuffle_np(X,Y)
#X,Y = shuffle_skl(X,Y)kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
scores = []
for train, test in kfold.split(X, Y):model = build_model(fea_cnt,numb)train_x = X[train]train_y = Y[train]test_x = X[test]test_y = Y[test]h = model.fit(train_x ,train_y,batch_size = 64,epochs = epochs,validation_data=(test_x,test_y))scores.append([h.history["loss"],h.history["acc"],h.history["val_loss"],h.history["val_acc"]])scores = np.array(scores)
scores = np.mean(scores,axis= 0)
#print(scores)
labs = ["loss","acc","val_loss","val_acc"]
result = zip([l+'_mean' for l in labs],[s[-1] for s in scores])
[print(res) for res in result]
[plt.plot(scores[i],label=labs[i]) for i in range(len(scores))]
plt.legend()
plt.savefig('eval'+'.png', dpi=300,bbox_inches = 'tight') #bbox_inches可完整显示
plt.show()
??结果:
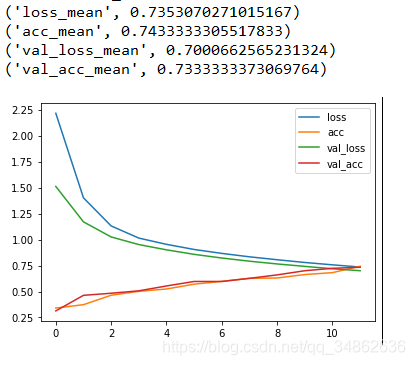
3.3 完整代码
from sklearn import datasets
from keras.layers import *
import keras.backend as K
from keras import Model
import pandas as pd
import numpy as np
from sklearn.utils import shuffle
from sklearn.model_selection import StratifiedKFold
from matplotlib import pyplot as plt
# In[*] get data
iris = datasets.load_iris()
X = np.array(iris['data'])
Y = np.array(iris['target'])# In[*] shuffle in numpy
def shuffle_np(X,Y):Y = Y.reshape(len(Y),1)data = np.concatenate([X,Y],axis=-1)np.random.seed(1337)np.random.shuffle(data)
# print(data)X = data[:,:-1]Y = data[:,-1]return X,Y# In[*] shuffle in sklearn
def shuffle_skl(X,Y):X,Y = shuffle(X,Y, random_state=1337)
# print(X,Y)return X,Y# In[*] build model
def build_model(fea_cnt,numb):K.clear_session() #清除之前的模型,省得压满内存inputs = Input(shape=(fea_cnt,), dtype='float32')embds = Dense(32 ,activation='selu')(inputs)outputs = Dense(numb,activation='softmax')(embds)model = Model(inputs=inputs, outputs=outputs)model.compile(loss='sparse_categorical_crossentropy', optimizer = 'sgd', metrics=['accuracy'])
# model.summary()return model# In[*] train model
fea_cnt = 4
numb = 3
epochs = 12
batch_size = 4
seed = 1337#X,Y = shuffle_np(X,Y)
#X,Y = shuffle_skl(X,Y)kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
scores = []
for train, test in kfold.split(X, Y):model = build_model(fea_cnt,numb)train_x = X[train]train_y = Y[train]test_x = X[test]test_y = Y[test]h = model.fit(train_x ,train_y,batch_size = 64,epochs = epochs,validation_data=(test_x,test_y))scores.append([h.history["loss"],h.history["acc"],h.history["val_loss"],h.history["val_acc"]])scores = np.array(scores)
scores = np.mean(scores,axis= 0)
#print(scores)
labs = ["loss","acc","val_loss","val_acc"]
result = zip([l+'_mean' for l in labs],[s[-1] for s in scores])
[print(res) for res in result]
[plt.plot(scores[i],label=labs[i]) for i in range(len(scores))]
plt.legend()
plt.savefig('eval'+'.png', dpi=300,bbox_inches = 'tight') #bbox_inches可完整显示
plt.show()