很多人都知道Anchor-based的目标检测网络按照阶段来分有两类,以RCNN为代表的的二阶段检测和SSD,Yolo为代表的一阶段网络。其中二阶段网络的RPN和一阶段网络的输出,损失函数都有框回归的部分。本篇博客就详细解释框回归的原理,步骤和Smoth L1 loss.
前言
在正式讲解之前,我们需要知道,网络的输出不是框的坐标和宽,高。这些坐标,宽高需要从输出向量解码得到。我们都知道,目标检测网络box分支输出的是离GT的偏置(offset)。所以box分支的label,其实并不是坐标值,而是要把坐标值先按照一定格式要求编码为一个四维向量,四个值分别描述了框中心点xy离GT框中心点的偏置,以及宽和GT宽的尺度变化信息,以及高和GT的高的尺度变化信息。
框回归是啥
anchor-base目标检测方法是有anchor的。为简单描述起见,以下提到的anchor统统都在原图空间下。
如下图所示,绿色框是网络预定义的一个anchor,这个anchor对应的score非常高,所以网络会把这个anchor挑出来作为框的输出,但是anchor这个东西是死的,即预先按照位置比例以及长宽比以及anchor size提前预定的,所以anchor一般来说都是没法准确框到目标的,我们需要在anchor的基础上进行框回归,或者认为是调整。
一个框的信息用四个值能描述,框中心的xy坐标,以及框的宽高,这四个值。对于中心点的坐标的调整,其实就是偏移,数学运算是加和减;而对于宽和高的调整,数学运算是乘和除。因此在后面的部分我们可以看出anchor是如何回归(解码)得到最后的框位置。
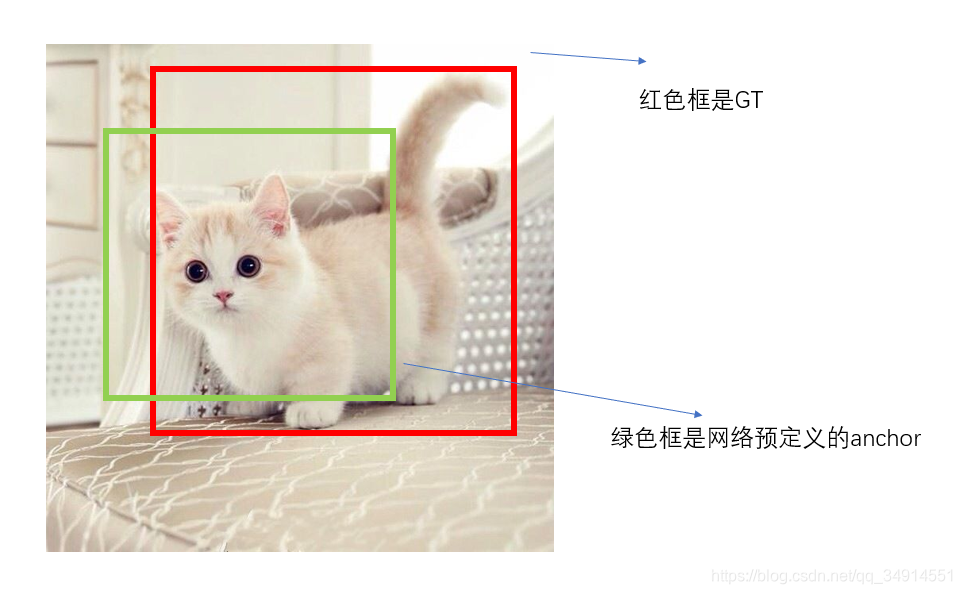
训练过程中,编码GT
假设GT是xc,yc,w,hx_c,y_c,w,hxc?,yc?,w,h,意义分别是GT的中心坐标和宽高。但这四个值是不能直接参与训练的。我们要先把它转化(或称编码)为相对于anchor的偏置量,偏移量参加训练,计算loss。那么具体如何编码GT呢?
首先对于一个特征图F∈RH×WF \in R^{H \times W}F∈RH×W, 存在H×W×kH \times W \times kH×W×k anchor, k是按照不同长宽比在同一个位置设立k个anchor的意思。
然后从这么多anchor中,计算IOU,选择和GT的交并比大于一个阈值的anchor,这些anchor被认为是正样本,是要参与计算框回归的。另外,这些anchor也要参与分类任务,但本文只涉及框回归这一部分,事实上分类损失也很好理解。
从IOU过滤之后,保留下的anchor中,为了通用性的解释,我下面就以一个anchor为例子,这个anchor是满足上述条件的。这个anchor就看做是上面图例的绿色框吧,简单起见,记作AAA
AAA是四维向量,值记作(axc,ayc,aw,ah)( ax_c, ay_c, aw, ah)(axc?,ayc?,aw,ah),意义分别是anchor的中心xy坐标,anchor的宽和高。这样就可以开始计算针对于这个anchor,对应的计算loss需要使用的真值偏置向量了。
dx=(xc?axc)/awd_x = (x_c - ax_c) / awdx?=(xc??axc?)/aw
dy=(yc?ayc)/ahd_y = (y_c - ay_c) / ahdy?=(yc??ayc?)/ah
dw=log(w/aw)d_w = log(w / aw)dw?=log(w/aw)
dh=log(h/ah)d_h = log(h/ah)dh?=log(h/ah)
gA=(dx,dy,dw,dh)g_A = (d_x, d_y, d_w, d_h)gA?=(dx?,dy?,dw?,dh?)
网络最后的直接输出(我用直接形容,意思是最后的卷积输出,没有其他后处理)就是anchor的偏置项,记作pAp_ApA?,意思是anchor AAA 的预测偏置项。而公式最下面的gAg_AgA?,意思是AAA的真值GT。
然后A的框回归的loss就是:
lossregA=smoothL1(pA,gA)loss^A_{reg} = smooth L1 (p_A, g_A)lossregA?=smoothL1(pA?,gA?)
另外我还没提到的是,所有的值都是被归一化的。比如xc,yc,w,hx_c,y_c,w,hxc?,yc?,w,h 这四个值其实是需要处理一下,横坐标和宽需要除以图像的宽,纵坐标和高,需要除以图像的高,来做归一化。至于(axc,ayc,aw,ah)( ax_c, ay_c, aw, ah)(axc?,ayc?,aw,ah),则对应除以特征图的宽和高
测试过程中,偏置项的解码
训练结束之后,我们要测试,需要输出的不是偏置项,而是实实在在的框的位置。解码方式就是编码的反转。其中(axc,ayc,aw,ah)( ax_c, ay_c, aw, ah)(axc?,ayc?,aw,ah)是已知的,因为是预定义的。dx,dy,dw,dhd_x, d_y, d_w, d_hdx?,dy?,dw?,dh?都换成是网络的直接输出值。这样就可以反过来去求xc,yc,w,hx_c,y_c,w,hxc?,yc?,w,h ,这四个值就是网络的框的位置输出(间接输出,因为由解码得到)。
从代码来看编码解码
先看编码
# matched 是框的GT,顺序是x,y, w,h ,下面一句通过先求框的中心点,然后框的中心点减去anchor的中心点得到差值g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]# 差值除以anchor的宽和高,分别得到上述前两个公式dx, dyg_cxcy /= priors[:, 2:]# 先求GT的宽和高与 anchor的宽和高的比值g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]# 然后求log,也是一一与上述步骤对应。g_wh = torch.log(g_wh)# loc = torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
再看解码
boxes = torch.cat((# anchor 的x y坐标加上 预测的xy的偏置项 乘 anchor的宽和高,就是前两行公式的反推。priors[:, :2] + loc[:, :2] * priors[:, 2:],priors[:, 2:] * torch.exp(loc[:, 2:] )), 1)# 框左上角坐标boxes[:, :2] -= boxes[:, 2:] / 2# 框右下角坐标boxes[:, 2:] += boxes[:, :2]
结束语
到此为止,我的讲解结束了,如果觉得不错的,请点个赞或者留言鼓励哦。优质博客,欢迎转载,转载请注明出处。