近几个月刚刚转到这个领域,作为什么都不了解的小白,看到了百度点石上这个比赛报名信息,果断报名。。由于比赛还未结束,在结束之后我们会在github上公开我们最终的代码,博客也会更新最终的比赛思路,现在想把我们初赛所采用的思路和一些进一步的改进猜想写下来,希望各位赛友可以共同讨论进步。
为了方便不了解该比赛的朋友了解背景,附官方链接如下:
百度点石:https://dianshi.baidu.com/competition/30/rank
2019国际大数据竞赛:http://www.ikcest.org/bigdata2019/?lang=zh#ranking-list
第一版思路
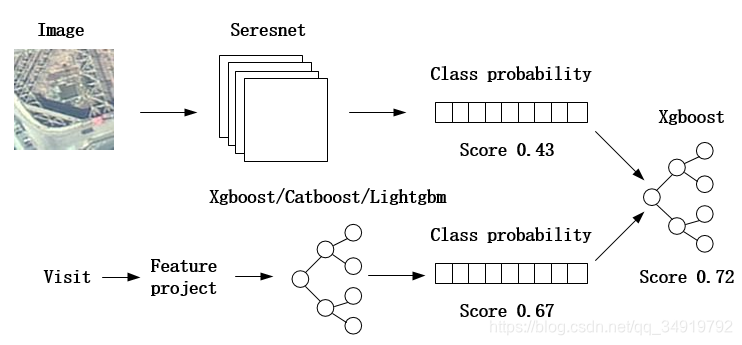
将思路图绘制出来,之前没有绘制经验,图丑勿怪,如果有什么没有表达清楚的可以评论下联系我,我再解释。
由于比赛提供的数据集分为两种数据主要,一种是遥感图像,一种是访问数据。
1、图像处理
我们对图像的处理很简单粗暴,直接将图像送入Seresnet中进行卷积,并构建全连接层输出每个类别的概率(共9种,这里的概率指的是softmax之后的值),通过最大值比较,我们发现单图像的效果是0.41~0.44之间浮动(期间也尝试了一些其他的模型,如DPN、Nasnet,但是效果好像没有特别大的变化,这里指的是单模型)。
2、访问数据处理
对于访问数据,我们先对访问数据提出特征问题,如一些人数,假期等,大概提了60个左右的特征问题,提取特征值,一开始用了Xgboost来做学习,同样也是输出九种概率,单模型的效果为0…67。之后我们也尝试了一些其他的模型,如Catboost,Lgb,但是效果没有显著的提高。
对于访问数据我们还做了一些简单的实验去验证了几个想法。
1)由于尝试了不同模型之后没有明显的提升,我们觉得可能是特征问题不足的原因,为此将特征问题从60个逐步扩大到80个,也尝试过去除相关性高的或者评分贡献低的特征,发现最高还是过不了0.67,而模型已经严重过拟合了但是不影响验证集不理。
2)我们做了另外一个实验,基于假设访问数据量不同不能用同一个模型来训练会使得模型对访问量少的样本的判断能力下降,应该分开进行训练。为此按文件内的用户总人数为100和10为分界线划分数据集进行训练和验证,发现划分后的数据集的准确率都下降了,尤其是数据量小的那一部分数据集。分析原因可能是和访问数据的来源有关,群上官方有这样的一个说法,访问数据来自于百度产品(我的理解是百度地图之类的)的用户信息,这样并不是每个人都会用这些软件,同时也经过消敏,这样给整体数据集带来了很大的不确定性。
3、数据融合
数据融合实际上一开始用了权重相加,效果不好,只有0.71左右,后来认为为什么不将不同所求的概率作为输入,用验证集作为最后的一个xgboost的训练集来训练融合模型,最后效果为0.7240,比直接通过加权相加的效果好了很多,可以调节xgboost的参数来提高效果,融合的思路应该挺多的,这里是我们用到的融合思路,至于有没有更好的融合思路我觉得是有的,但是后期我们并没有在这上面花时间,所以只是贴出我们所用的方法。如果有朋友有其他的想法,可以提出来我们一起讨论交流。
4、第一版思路总结
第一版思路的所有实现在6月前就完成了,但是当时发现我们和前排的人之间的差距还是很大,虽然没有什么经验但是还是要加油改进。。
对第一版思路进行了改进总结:
1、访问数据特征工程可能在原来这个数据集上要再进行提高很难,同一时间在讨论区有人提出将访问信息矩阵化的baseline,觉得还是挺有借鉴意义的,有可能能从其他的方面提供不一样的特征提高。后期在下一版实验中会尝试加入看是否有所提高。
2、图像是否要进行预处理,是否进行图像增广可以提高图像处理的准确率。
第二版思路
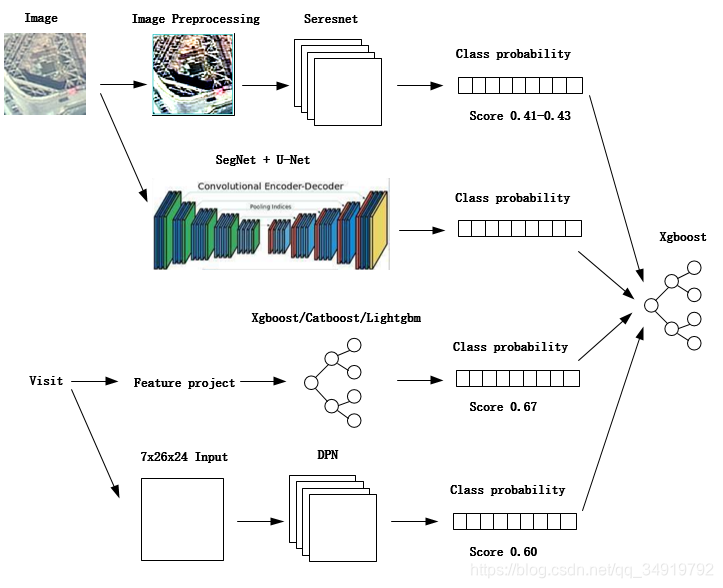
第二版思路在原来的基础对图像和访问数据各增加了一条处理支路,我们的想法是可以通过不同的思路增加不同的特征,但是由于6月学校事情太多了,语义分割的那条支路没有时间去做出来,在后期会找时间去试试,如果效果好的话在复赛之后更新思路中会将实现思路更新出来供大家一起讨论学习。
1、图像处理
由于语义分割没有做出来,所以对图像只是增加了预处理,用了去雾,旋转等,实际上在实验过程中但模型的准确率很浮动,依然是0.43左右浮动。
2、访问数据处理
参考讨论区的baseline,我们将访问数据进行矩阵化后卷积,单模型的准确率为0.60,同样对模型最后进行改进,使其输出为9种概率。
3、数据融合
一开始我们将3种不同来源的9类概率按之前所提的方法进行融合,分值为0.73左右,后来尝试了baseline那样将图像和访问数据在全连接层的通道合并成320,及访问数据单纯64通道过全连接层,得到了4组概率,最后融合的分值在0.7338。
4、第二版思路总结
6月时间比较尴尬,做的实验不是很多,比较大的遗憾是没有把语义分割的路线做出来,之后在复赛还是希望能多做一些实验,把能验证的思路都验证下
1、我们分析觉得主要提高不了的问题还是在图像上,图像的预处理效果不是很好,可能是方式不对,不知道有没有人尝试过超分辨率将图像提高分辨率,觉得这是个可行的图像预处理思路,分辨率过低是可能降低图像的分类效果的。
2、图像更换了很多模型都提高不了,后来提出的0.715的baseline说通过多个模型过采样来emsamble做提高,这是种思路但是感觉会很复杂,在有提高思路的情况下还是想尝试其他方法。
3、个人觉得不同的网络卷积后的feature map虽然有差异,但是全连接之后的效果都差不多,可能说明卷积的效果可能对这个数据集来说就这样了,可能要提高可以从对feature map的处理来做,即用其他方法来替换全连接层,或者对最后输出的feature map再做点处理,如knn,pca等。