关注这个问题很久了,但一直没有看到太满意的答案,今天终于在知乎中找到了一种非常清晰的解释。
知乎连接:https://www.zhi
首先,需要明确的是,建模位置信息(无论是绝对位置还是相对位置)并不是必须用到三角函数,否则fairseq和BERT中使用的positional embedding也不会奏效了。我想,作者在这里使用正余弦函数,只是根据归纳偏置和一些经验作出的选择罢了。
不妨从零构想一个位置编码的方法。首先,给定一个长为T的文本,最简单的位置编码就是计数,即使用PE = pos = 0,1,2,...,T-1作为文本中每个字的位置编码。当然这样的瑕疵非常明显,这个序列是没有上界的。设想一段很长的(比如含有500个字的)文本,最后一个字的位置编码非常大,这是很不合适的:1. 它比第一个字的编码大太多,和字嵌入合并以后难免会出现特征在数值上的倾斜;2. 它比一般的字嵌入的数值要大,难免会抢了字嵌入的「风头」,对模型可能有一定的干扰。
从这里,我们知道位置编码最好具有一定的值域范围,这样就有了第二个版本:使用文本长度对每个位置作归一化,得到PE = pos/(T-1) 。这样固然使得所有位置编码都落入 区间,但是问题也是显著的:不同长度文本的位置编码步长是不同的,在较短的文本中紧紧相邻的两个字的位置编码差异,会和长文本中相邻数个字的两个字的位置编码差异一致。这显然是不合适的,我们关注的位置信息,最核心的就是相对次序关系,尤其是上下文中的次序关系,如果使用这种方法,那么在长文本中相对次序关系会被「稀释」。
再重新审视一下位置编码的需求:1. 需要体现同一个单词在不同位置的区别;2. 需要体现一定的先后次序关系,并且在一定范围内的编码差异不应该依赖于文本长度,具有一定不变性。我们又需要值域落入一定数值区间内的编码,又需要保证编码与文本长度无关,那么怎么做呢?一种思路是使用有界的周期性函数。在前面的两种做法里面,我们为了体现某个字在句子中的绝对位置,使用了一个单调的函数,使得任意后续的字符的位置编码都大于前面的字,如果我们放弃对绝对位置的追求,转而要求位置编码仅仅关注一定范围内的相对次序关系,那么使用一个sin/cos函数就是很好的选择,因为sin/cos函数的周期变化规律非常稳定,所以编码具有一定的不变性。简单的构造可以使用下面的形式:
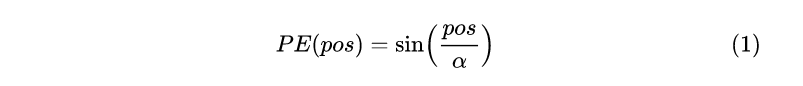
这样的做法还是有一些简陋,周期函数的引入是为了复用位置编码函数的值域,但是这种Z->[-1,1]的映射,还是太单调:如果 α比较大,相邻字符之间的位置差异体现得不明显;如果α比较小,在长文本中还是可能会有一些不同位置的字符的编码一样,这是因为[-1, 1]空间的表现范围有限。既然字嵌入的维度是 dmodel ,自然也可以使用一个 dmodel维向量来表示某个位置编码――[-1,1]^( dmodel)的表示范围要远大于[-1, 1]。
显然,在不同维度上应该用不同的函数操纵位置编码,这样高维的表示空间才有意义。可以为位置编码的每一维赋予不同的α;甚至在一些维度将sin替换为cos,一种构造方法就是论文中的方法了

这里不同维度上sin/cos的波长从2pi到10000*2pi都有;区分了奇偶数维度的函数形式。这使得每一维度上都包含了一定的位置信息,而各个位置字符的位置编码又各不相同。这里可以顺便为一个疑问作一个可能的解释:为什么官方代码tensor2tensor的最初版本只是简单地分了两段,却没有什么性能差异呢?因为sin/cos的交替使用只是为了使编码更「丰富」,在哪些维度上使用 sin哪些使用cos 不是很重要,都是模型可以调整适应的。
当然,我觉得深究这里的三角函数形式的位置编码没有太大意义。因为至少现在看来:1. 这个函数形式很可能是基于经验得到的,并且应该有不少可以替代的方法;2. 谷歌后期的作品BERT已经换用位置嵌入(positional embedding)了,这可能说明编码的方案有一定的问题(猜测)。