机器学习―编程练习(四):神经网络
文件列表
ex4.m - Octave/MATLAB script that steps you through the exercise
ex4data1.mat - Training set of hand-written digits
ex4weights.mat - Neural network parameters for exercise 4
submit.m - Submission script that sends your solutions to our servers
displayData.m - Function to help visualize the dataset
fmincg.m - Function minimization routine (similar to fminunc)
sigmoid.m - Sigmoid function
computeNumericalGradient.m - Numerically compute gradients
checkNNGradients.m - Function to help check your gradients
debugInitializeWeights.m - Function for initializing weights
predict.m - Neural network prediction function
[*] sigmoidGradient.m - Compute the gradient of the sigmoid function
[*]randInitializeWeights.m - Randomly initialize weights
[*] nnCostFunction.m - Neural network cost function
* 是需要完成的内容
1 神经网络
在之前的练习中,你实现了前向传播神经网络,并且使用它以及我们提供的权重预测了手写体。在这次的练习中,你将会实现反向传播算法学习神经网络中的参数。
第一部分是前向传播神经网络,这部分的第一节和第二节和(练习三)一致,就不过多赘述,从第三节开始。
1.3 前向传播和成本函数
现在你将会为神经网络实现成本函数和梯度,首先完成nnCostFunction.m中的代码返回cost。
神经网络的成本函数

hθ(x(i))计算如下图

另外,我们的原始标签是1-10,为了训练神经网络,我们需要将标签转换成只含1和0的向量

这里我做的时候不知道y是多大的向量,以及怎样去转换。
首先y 是 5000*1的矩阵

矩阵中的每个元素需要转换成
那么转换之后的y是

y中有5000个10*1的矩阵。
之后是y的转换代码
y = repmat([1:num_labels], m, 1) == repmat(y, 1, num_labels);
%我们把它拆分一下,方便我解释
a = repmat([1:num_labels], m, 1);
b = repmat(y, 1, num_labels);
y = a == b;
repmat函数的百度解释。

上面那段代码的意思是
创建一个5000 x 1的矩阵,矩阵中每个元素是[1 2 3 4 5 6 7 8 9 10], a的大小是5000 x 10
再创建一个1 x 10的矩阵,矩阵中每个元素是y,y是5000 x 1的矩阵, 所以b的大小是5000 x 10
(这里用*会变成斜体,用x代替)
再解释 y = a == b;我贴个图,应该就明白了。

这段代码的意思是创建一个a大小的矩阵(a b矩阵大小相等),比较ab当ab相等是值为1,其余为0.
之后比较ab中的元素,我们得到这样的矩阵y 大小 5000*10.

正则成本函数
神经网络的正则成本函数

这部分代码如下:
a_1 = [ones(m, 1) X];z_2 = a_1*Theta1';
a_2 = sigmoid(z_2);a_2 = [ones(m, 1) a_2];
z_3 = a_2*Theta2';a_3 = sigmoid(z_3);
h = a_3;
y_vec = [y(:)];
h_vec = [h(:)];
%对Theta1 Theta2矢量化
regTheta1 = Theta1(:,2:end);
regTheta2 = Theta2(:,2:end);
Theta1_vec = [regTheta1(:)];
Theta2_vec = [regTheta2(:)];
J = 1/m.*(-y_vec' * log(h_vec) - (1 - y_vec)' * log(1 - h_vec))...+ lambda/(2*m).*(Theta1_vec'*Theta1_vec + Theta2_vec'*Theta2_vec);这部分有点绕,我看了程序答案又思考了好久才理解。不知道你们理解了没。如果有没懂的地方可以留言,我看到会回复的。参考答案上就比较简单了,不需要思考这么多东西,没用矩阵乘法求和,两个sum解决。实在看不懂也可以参考答案。
2 反向传播
在这部分的练习中,你将会实现反向传播算法计算神经网络成本函数的梯度。完成梯度的计算后,你就能使用一个像fmincg这样的高级优化器,通过最小化成本函数 J(Θ)训练神经网络。首先你将会求得一个非正则神经网络的梯度,完成以后,再实现正则神经网络的梯度。
2.1 Sigmopid gradient
为了帮助你完成这部分的练习,你将会先实现sigmoid梯度函数


将下列代码输入到 sigmoidGradient(z) 中
g = sigmoid(z).*(1 - sigmoid(z));
2.2 随机初始化
在训练神经网络的时候,随机初始化参数对于对称破坏(symmetry breaking 知网上查的)时非常重要的。一种非常有效的随机初始化方法是在 [??init ,?init ]之间挑选Θ(l) 的值。你应该使用,?init = 0.12.这个范围的值确保参数被保持的很小,并且使学习更有效。
将下列代码输入到 randInitializeWeights.m 中(讲义上有)
% Randomly initialize the weights to small values
epsilon init = 0.12;
W = rand(L out, 1 + L in)*2*epsilon_init ? epsilon_init;
?init 的计算方法
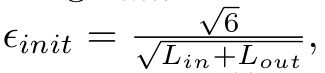
Lin = sl , Lout = sl+1 ,是Θ(l)相邻层中的单元数。
2.3 反向回归

我把那两页算法思路全都翻译下来,没保存,在那调试代码。电脑死机( fuck )。。。。。。
这部分算法思路我刚理解的时候有些困难,就将他们翻译下来,方便以后察看。不想看的可以跳过。
现在你将会实现反向传播算法。反向传播算法的思路是这样的。
给出一个训练样本(x(t), y(t)),我们首先运行一个“前向传播”计算整个网络的所有激活值
( activations),包括输出值hΘ(x),之后,对于l层中每个节点j,我们想要计算一个“误差值”
σ (l)j ,这个误差值表示节点对于输出错误的“责任度”。
对于一个输出节点,我们可以直接测量网络激活值与真实值的差,并且使用这个定义σ (3)j
(因为输出层是3).对于隐藏单元,你将会基于(l+1)层节点的误差项的加权平均值计算
σ (l)j 。
详细的说,这就是反向传播算法。你应该在一个循环中实现步骤1-4,这个循环一次处理一个样本数据。更具体点,你应该实现一个for循环 for t = 1:m 并且将下面的步骤1-4放到for循环中,t次循环执行t次训练样本(x(t), y(t))的计算。步骤5将累加梯度值除以m得到神经网络成本函数的梯度。
-
设输入层的值(a(1))为t个训练样本x(t) 。运行一个前向传播,计算2,3层的激活值
(z(2), a(2), z(3), a(3))注意你需要添加一个a+1项确保a(1),a(2) 层也包括偏差单元(bias unit)。在Octave/Matlab中,如果a_1是一个列向量,则添加代码为
a_1 = [1 ; a_1].。 -
对于每一个第三层的输出单元k,设

yk∈{0,1}表示现在的训练样本是否属于k类(yk = 1),或者它是否属于一个不同的类
(yk = 0)。你可能发现逻辑数组对这个工作很有帮助。 -
对于隐藏层 l = 2 ,设

-
使用下面的公式从这个样本中累加梯度,注意你应该跳过或者移除σ (2)0 .
在Octave/Matlab中,移除σ (2)0 的代码是 delta_2 = delta_2(2:end)。

-
将累加梯度除以m就得到满足神经网络成本函数的梯度值了

这个没有正则化梯度值,结果会出现错误。我将正则化的那一节提前写一下,最后给出完整代码。
2.4 神经网络正则化
在你已经成功实现反向传播算法后,你应该加上对梯度的正则话。为了计算正则化,这很明显你可以将这里作为一个添加项加到反向传播梯度之后。
正则化公式:

注意不要对Θ(l) 的第一项偏差单元正则化。此外,参数Θ(l) ij i从1开始,j从0开始。因此:

有点令人困惑的是,在Octave/Matlab中,输入从1开始,因此Theta1(2, 1)实际对应Θ(l) 20
这部分完整代码如下:
%在这部分的代码中,调试时我将变量对应的大小添加到了后面。
%以后会养成习惯,每个都在后面加变量大小,方便检察。
a_1 = [ones(m, 1) X]; %5000*401z_2 = a_1*Theta1'; % 5000*401 25*401 5000*25
a_2 = sigmoid(z_2); %5000*25a_2 = [ones(m, 1) a_2]; %5000*26
z_3 = a_2*Theta2'; %5000*26 10*26 5000*10a_3 = sigmoid(z_3);
h = a_3;y = repmat([1:num_labels], m, 1) == repmat(y, 1, num_labels);% 1-10复制5000*1份 == 5000*1 复制1*10份
y_vec = [y(:)];
h_vec = [h(:)];
%对Theta1 Theta2矢量化
regTheta1 = Theta1(:,2:end);
regTheta2 = Theta2(:,2:end);Theta1_vec = [regTheta1(:)];
Theta2_vec = [regTheta2(:)];
J = 1/m.*(-y_vec' * log(h_vec) - (1 - y_vec)' * log(1 - h_vec))...+ lambda/(2*m).*(Theta1_vec'*Theta1_vec + Theta2_vec'*Theta2_vec);Delta_2 = zeros(size(Theta2));
Delta_1 = zeros(size(Theta1));for i = 1:mdelta_3 = a_3(i,:) - y(i,:); %1*10delta_2 = delta_3*Theta2 .* sigmoidGradient([1 z_2(i,:)]); %10*26 1*10 1*26 1*26delta_2 = delta_2(2:end); %1*25Delta_1 = Delta_1 + delta_2'*a_1(i,:); %25*401 1*25 1*401Delta_2 = Delta_2 + delta_3'*a_2(i,:); %10*26 1*10 1*26endfor%+号后面的部分就是正则化,将偏差单元置零,补齐矩阵。
Theta1_grad = 1/m * Delta_1 + (lambda/m)*[zeros(size(Theta1, 1), 1) regTheta1];
Theta2_grad = 1/m * Delta_2 + (lambda/m)*[zeros(size(Theta2, 1), 1) regTheta2];
2.5梯度检测
你有一个函数fi(Θ),它由成本函数J(Θ)对Θ求偏导得到。现在你想检测fi是否输出正确的梯度值

验证公式:

但是假设 ε = 10-4,你经常会发现上式左边和右边会至少有四个有效数字。
原文:
But assuming ε = 10 ?4 , you’ll usually find that the left- and right-hand sides of the above will agree to at least 4 significant digits (没看懂想说什么).