任务
- 卷积运算的定义、动机(稀疏权重、参数共享、等变表示)。一维卷积运算和二维卷积运算。
- 池化运算的定义、种类(最大池化、平均池化等)、动机。
- Text-CNN的原理。
- 利用Text-CNN模型来进行文本分类。
卷积运算
卷积神经网络CNN(Convolution Neural Network) 在数字图像处理领域取得了巨大的成功,从而掀起了深度学习在自然语言处理领域(Natural Language Processing, NLP)的狂潮。
卷积是一种运算方式,最早用于数字信号处理中,这里就不展开说明,自行百度了解,那在机器学习,卷积的形式化表示是什么呢?
c i = f ( ∑ w x + b ) c_i=f(\sum{wx}+b) ci?=f(∑wx+b)
这个公式如何理解呢?看图:
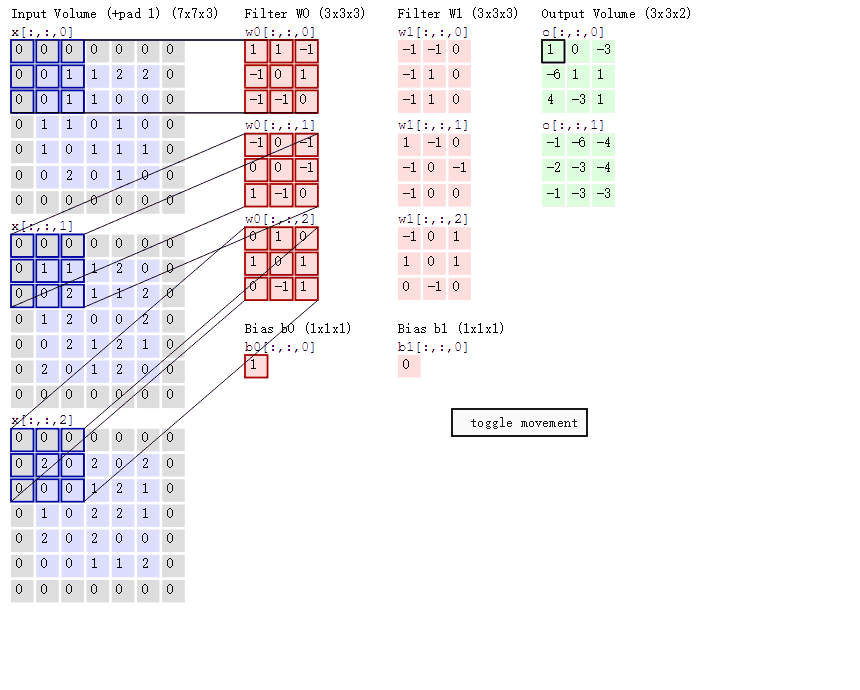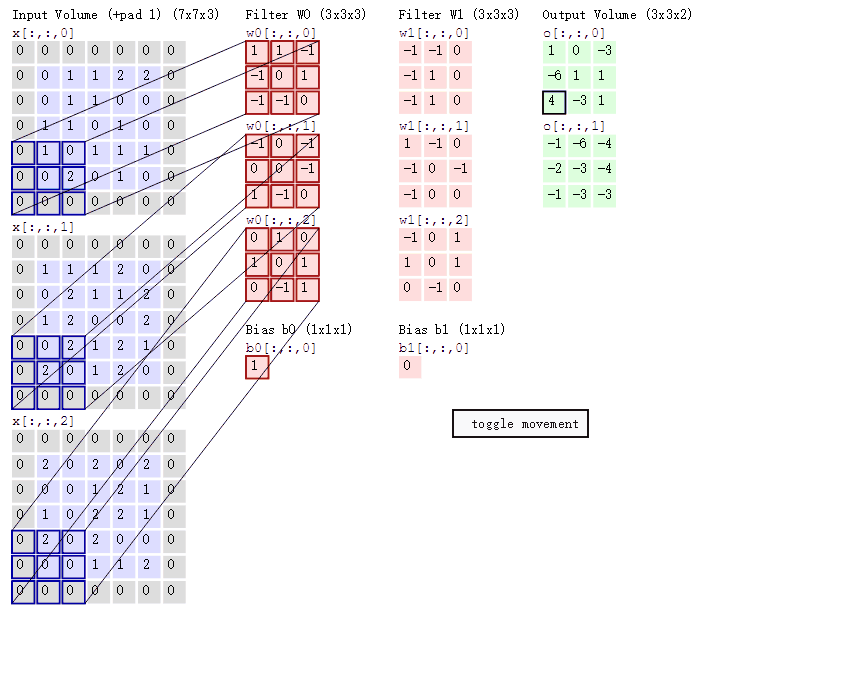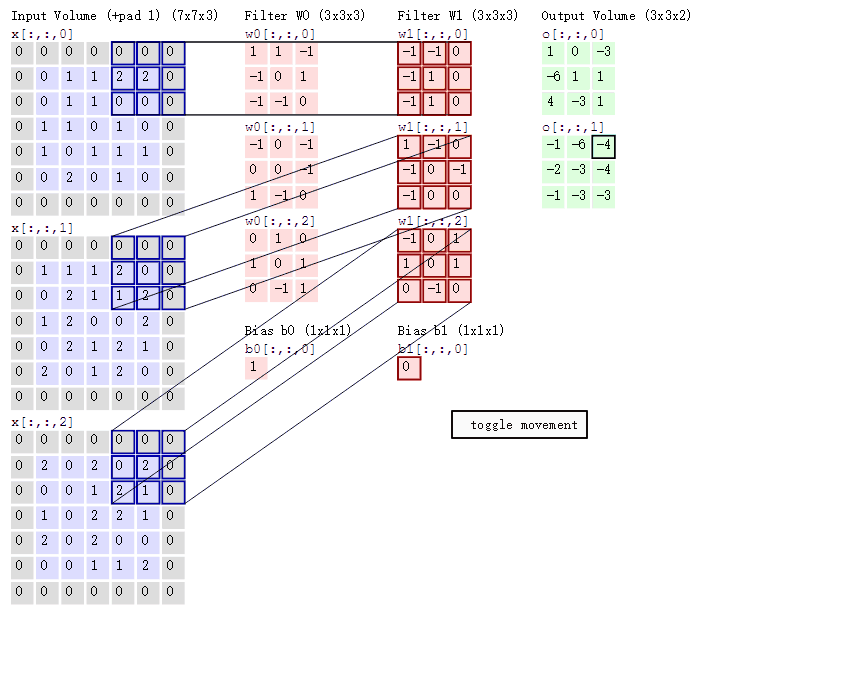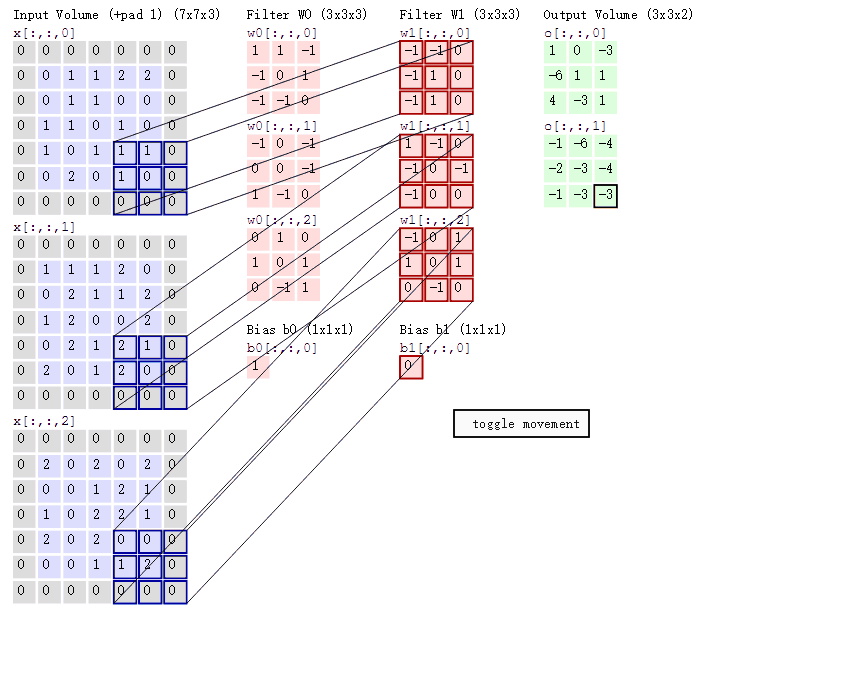
首先我们看到
- Input Vloum:左边灰色7 * 7的表格有3个,也就是773
- Filter W0 :3 * 3 * 3
- Filter W1 :3 * 3 * 3
- Input Vloum :3 * 3 * 2
- Bias b0:1,这个是跟着Filter W0的
- Bias b1:0,这个是跟着Filter W0的
- 还有一个步长的概念,就是你移动Input Vloum的窗口大小,上述的GIF图中的步长是2,每次向右移动2个窗口大小,这个可以自行设置。
这样来理解:某一个时刻,三个Filter的w值同时乘以Input Vloum,得到的值相加,最后加上Bias,从而得到Input Vloum。从这句话里可以得到什么信息呢?
- 公式中 ∑ \sum ∑就是不同Filter的作用后相加的意思。
- 通过设置Filter个数可以影响最终的下一层的数据,原本属于是3层数据,经过Filter只有就只有2层
- 同时,Filter的大小,也会影响下一层的数据
这些还是比较简单可以清晰了解到的内容,这就是卷积操作,也可以叫做加权求和运算,每个Filter就是一个权重,对于数据中的不同特征进行加权。
卷积运算有几个特性:
-
参数共享
就是利用Filter不断的在原图像上移动,所有框框内部的数据计算方式一样,这就是 “参数共享”,这样就大大减少了参数值,毕竟权重都是一样的嘛。当然在使用中,有时候参数还是太多,收敛还是太慢,这时候还有其他的方式,比如dropout等等,随机 “杀死”一些神经元,计算就更快了。 -
局部连接(稀疏权重)
卷积层的节点仅仅和其前一层的部分节点相连接,只用来学习局部特征。每次在原图像上学习一部分特征。 -
等边表示
参数共享的特殊形式使得卷积层具有平移等变的性质。平移不变性是指卷积产生了一个二维的映射来表明某些特征在输入中的位置,如果我们移动输入的图像,它的表示也会在输出中移动同样的量。卷积对图像缩放和旋转并没有不变性,通常需要加入一些特殊的机制进行处理。
池化运算
池化层(Pooling Layer)虽然名字怪怪的,实际上相比之前的卷积层更好计算,它作用在 Feature Map 上,相当于对输入矩阵的尺寸进一步浓缩,也就是进一步提取特征。计算类似卷积,通过一个类似Filter的结构进行不断地移动(Stride就等于Filter地长度)只是过程简单多了。对于这个区域地计算,不再是使用加权和地形式,而是采用简单的最大值、平均值的方式,使用最大值的称为最大池化层(max pooling), 使用平均值的称为平均池化层(mean pooling),这是一个最大池化计算的例子 卷积神经网络:
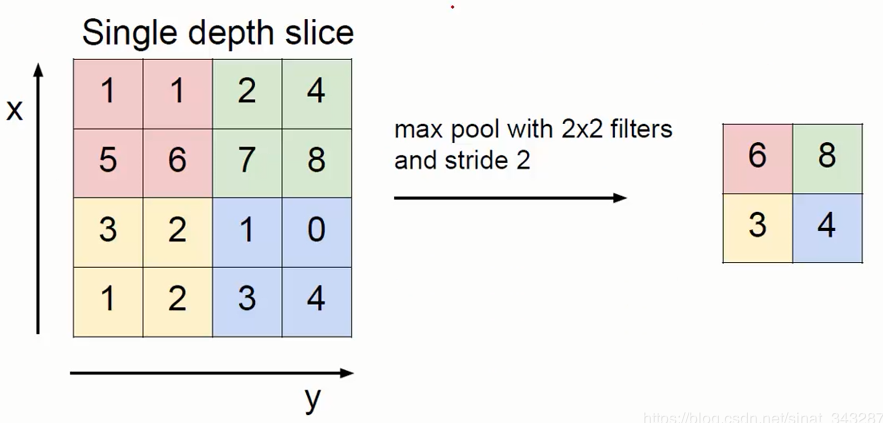
上图是一个最大值池化的例子,取区域内格子里的最大值,还有一些其他池化的方法。
卷积网络
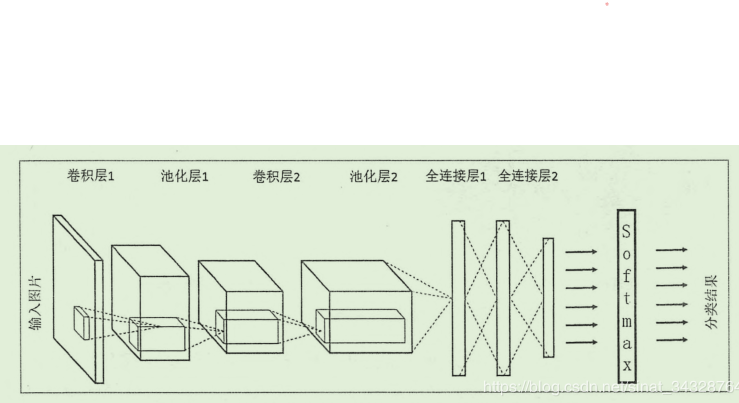
- 数据输入层/ Input layer
- 卷积计算层/ CONV layer
- 激励层 / ReLU layer
- 池化层 / Pooling layer
- 全连接层 / FC layer
上述图中中间层的卷积层、池化层等等顺序是不一定的,这主要看你如何设计这个网络,但大致是先卷积后池化,最后是全连接,然后经过激励层,当然也可以在卷积层之后接入激励层,这里主要讲解几个层:
-
激励层
激励函数层主要是把卷积层输出结果做非线性映射。最近几年卷积神经网络中,激活函数往往不选择sigmoid或tanh函数,而是选择relu函数。主要是收敛快,求梯度简单,但较脆弱,激励层的实践经验:
①不要用sigmoid!不要用sigmoid!不要用sigmoid!
② 首先试RELU,因为快,但要小心点
③ 如果2失效,请用Leaky ReLU或者Maxout
④ 某些情况下tanh倒是有不错的结果,但是很少 -
全链接层
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的,全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。那问题来了?为什么卷积网络需要全连接层?
有一些人就分享说:
- 卷积取的是局部特征,全连接就是把以前的局部特征重新通过权值矩阵组装成完整的图。减少特征位置对分类带来的影响。
Text-CNN
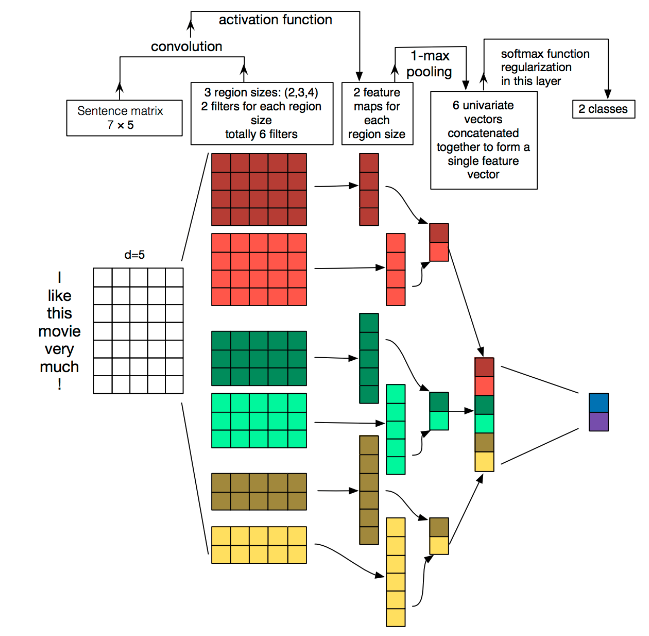
利用CNN来做文本分类,主要思想是首先将单词弄成词向量,这样每一行数据就是一个词向量,一共有 s ? n s*n s?n,s表示的是文本的数量,n表示的是词向量的大小。剩下的就是自己设计卷积神经网络结构了,这里参考Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能够更好地捕捉局部相关性。论文没看,主要参考网上资料,接口图如下:
-
第一层
第一层是输入的7*5的词向量矩阵,词向量的维度为5,共7个单词。 -
第二层
第二层是卷积层,共有6个卷积核,尺寸为2×5、3*5、4×5,每个尺寸各2个,输入层分别与6个卷积核进行卷积操作,再使用激活函数激活,每个卷积核都得到了对应的feature maps。 -
第三层
第三层是池化层,使用1-max pooling提取出每个feature map的最大值,然后进行级联,得到6维的特征表示。 -
第四层
第四层是输出层,输出层使用softmax激活函数进行分类,在这层可以进行正则化操作(l2-regulariation)。再进行softmax输出2个类别
一些疑惑:
- 为什么采用不同大小的卷积核,这样可以输出不同的感受视野,卷积核的宽取词汇表的纬度,有利于语义的提取。
- 词维度,这里的词向量不是字向量,主要是词的语义更强,字某种意义上来说不具有意义,
词向量模型:一般开始为高纬度,高稀疏向量,利用嵌入层对其进行降维,增加稠密性。使用词向量进行文本分类的步骤为:①.先使用分词工具提取词汇表。②.将要分类的内容转换为词向量。a.分词b.将每个词转换为word2vec向量。c.按顺序组合word2vec,那么就组合成了一个词向量。d.卷积、池化和连接,然后进行分类。
图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。fine-tunning词向量是表示在训练的过程中,词向量是可以进行微调的。不是一成不变的,这种很有意思。
Text-CNN分类
# coding: utf-8
import pickle
import logging
import tensorflow as tf
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s',level=logging.INFO)class TextCNN(object):"""A CNN for text classification.Uses an embedding layer, followed by a convolution, max-pooling and soft-max layer."""def __init__(self, config):self.lr = config['lr']self.batch_size = config['batch_size']# 词典的大小self.vocab_size = config['vocab_size']self.num_classes = config['num_classes']self.keep_prob = config['keep_prob']# length of word embeddingself.embedding_size = config['embedding_size']# seting filter sizes, type of listself.filter_sizes = config['filter_sizes']# max length of sentenceself.sentence_length = config['sentence_length']# number of filtersself.num_filters = config['num_filters']def add_placeholders(self):self.X = tf.placeholder('int32', [None, self.sentence_length])self.y = tf.placeholder('int32', [None, ])def inference(self):with tf.variable_scope('embedding_layer'):# loading embedding weightswith open('Text_cnn/embedding_matrix.pkl','rb') as f:embedding_weights = pickle.load(f)# non-static self.W = tf.Variable(embedding_weights, trainable=True, name='embedding_weights',dtype='float32')# shape of embedding chars is (None, sentence_length, embedding_size)self.embedding_chars = tf.nn.embedding_lookup(self.W, self.X)# shape of embedding char expanded is (None, sentence_length, embedding_size, 1)self.embedding_chars_expanded = tf.expand_dims(self.embedding_chars, -1)with tf.variable_scope('convolution_pooling_layer'):pooled_outputs = []for i, filter_size in enumerate(self.filter_sizes):filter_shape = [filter_size, self.embedding_size, 1, self.num_filters]W = tf.get_variable('W'+str(i), shape=filter_shape,initializer=tf.truncated_normal_initializer(stddev=0.1))b = tf.get_variable('b'+str(i), shape=[self.num_filters],initializer=tf.zeros_initializer())conv = tf.nn.conv2d(self.embedding_chars_expanded, W, strides=[1,1,1,1],padding='VALID', name='conv'+str(i))# apply nonlinearityh = tf.nn.relu(tf.add(conv, b))# max poolingpooled = tf.nn.max_pool(h, ksize=[1, self.sentence_length - filter_size + 1, 1, 1],strides=[1, 1, 1, 1], padding='VALID', name="pool")# shape of pooled is (?,1,1,300)pooled_outputs.append(pooled)# combine all the pooled featuresself.feature_length = self.num_filters * len(self.filter_sizes)self.h_pool = tf.concat(pooled_outputs,3)# shape of (?, 900)self.h_pool_flat = tf.reshape(self.h_pool, [-1, self.feature_length])# add dropout before softmax layerwith tf.variable_scope('dropout_layer'):# shape of [None, feature_length]self.features = tf.nn.dropout(self.h_pool_flat, self.keep_prob)# fully-connection layerwith tf.variable_scope('fully_connection_layer'):W = tf.get_variable('W', shape=[self.feature_length, self.num_classes],initializer=tf.contrib.layers.xavier_initializer())b = tf.get_variable('b', shape=[self.num_classes],initializer=tf.constant_initializer(0.1))# shape of [None, 2]self.y_out = tf.matmul(self.features, W) + bself.y_prob = tf.nn.softmax(self.y_out)def add_loss(self):loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=self.y, logits=self.y_out)self.loss = tf.reduce_mean(loss)tf.summary.scalar('loss',self.loss)def add_metric(self):self.y_pred = self.y_prob[:,1] > 0.5self.precision, self.precision_op = tf.metrics.precision(self.y, self.y_pred)self.recall, self.recall_op = tf.metrics.recall(self.y, self.y_pred)# add precision and recall to summarytf.summary.scalar('precision', self.precision)tf.summary.scalar('recall', self.recall)def train(self):# Applies exponential decay to learning rateself.global_step = tf.Variable(0, trainable=False)# define optimizeroptimizer = tf.train.AdamOptimizer(self.lr)extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)with tf.control_dependencies(extra_update_ops):self.train_op = optimizer.minimize(self.loss, global_step=self.global_step)def build_graph(self):"""build graph for model"""self.add_placeholders()self.inference()self.add_loss()self.add_metric()self.train()
参考博客
深入理解卷积层,全连接层的作用意义
卷积神经网络各层分析
理解TextCNN
Text-cnn详解