Hadoop入门配置系列博客目录一览
1、Eclipse中使用Hadoop伪分布模式开发配置及简单程序示例(Linux下)
2、使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)
3、Hadoop完全分布式集群安装及配置(基于虚拟机)
4、Eclipse中使用Hadoop集群模式开发配置及简单程序示例(Windows下)
5、Zookeeper3.4.9、Hbase1.3.1、Pig0.16.0安装及配置(基于Hadoop2.7.3集群)
6、mysql5.7.18安装、Hive2.1.1安装和配置(基于Hadoop2.7.3集群)
7、Sqoop-1.4.6安装配置及Mysql->HDFS->Hive数据导入(基于Hadoop2.7.3)
8、Hadoop完全分布式在实际中优化方案
9、Hive:使用beeline连接和在eclispe中连接
10、Scala-2.12.2和Spark-2.1.0安装配置(基于Hadoop2.7.3集群)
11、Win下使用Eclipse开发scala程序配置(基于Hadoop2.7.3集群)
12、win下Eclipse远程连接Hbase的配置及程序示例(create、insert、get、delete)
hadoop入门示例详见本人github:https://github.com/Nana0606/hadoop_example
本篇博客主要介绍“使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)”。
在之前一篇:[Eclipse中使用Hadoop单机模式开发配置及简单程序示例](http://blog.csdn.net/quiet_girl/article/details/74001759),我们讲了如何在eclipse配置文件信息以及如何执行Map/Reduce程序,本篇基于这篇文章的代码总结一下使用hadoop命令行执行jar包的流程,主要包括生成jar、将本地文件上传至dfs文件系统中,执行jar包。
一、Eclipse中生成jar包
使用[Eclipse中使用Hadoop单机模式开发配置及简单程序示例](http://blog.csdn.net/quiet_girl/article/details/74001759) 的MaxTemperature项目的代码,代码写完之后,将其打包成jar,步骤如下:“右击项目名称 --> Export --> JAR file --> Next --> 设置导出路径 --> Next --> Finish”即可,如下图,在这里我们将jar包的输出路径设置为:/home/lina,名称为example.jar :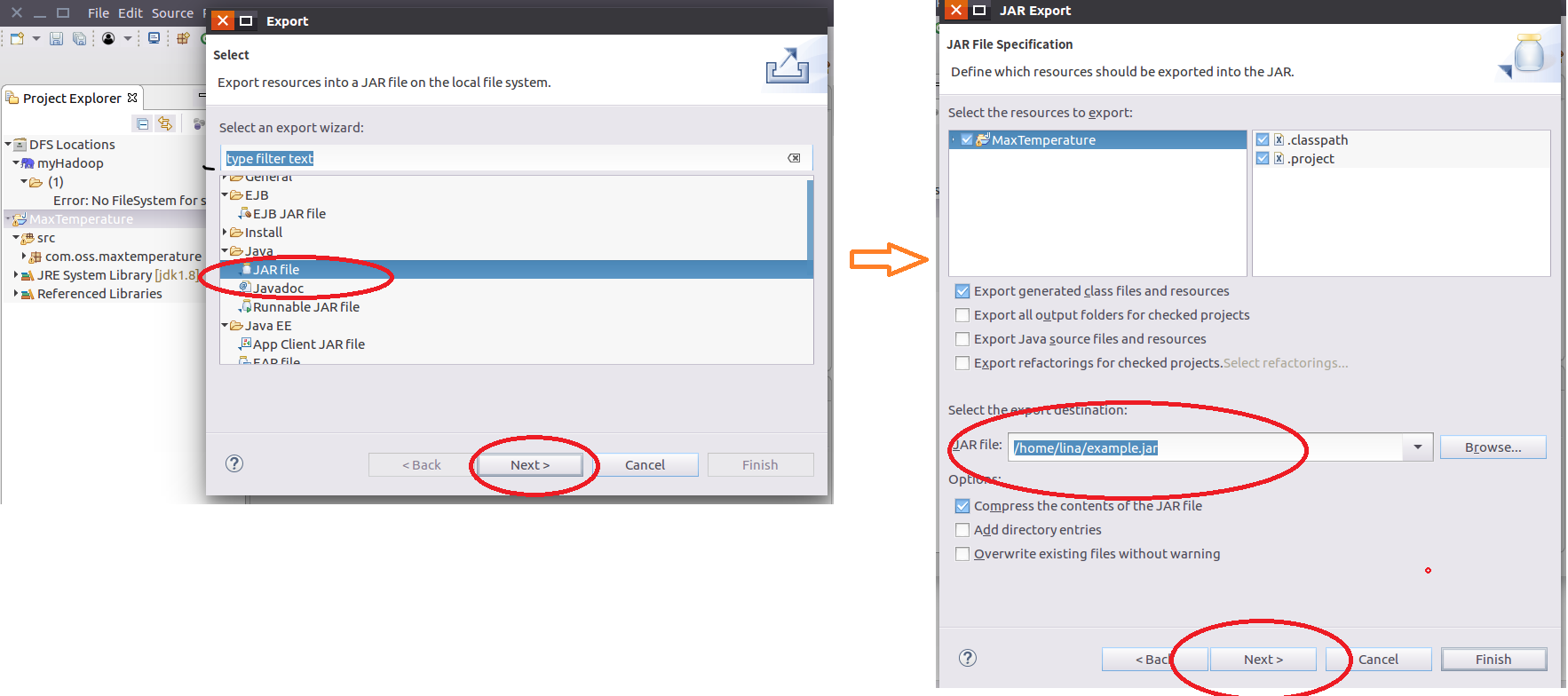
二、将本地文件上传至dfs文件系统
输入文件仍然使用[Eclipse中使用Hadoop单机模式开发配置及简单程序示例](http://blog.csdn.net/quiet_girl/article/details/74001759) 的sample.txt,本地目录为/home/lina/input/sample.txt,现在将此文件上传至dfs文件系统中。 1、在dfs系统中新建一个名为local的文件夹,将当前目录切换到hadoop安装目录下,使用下面的命令:cd /opt/Hadoop
hdfs dfs -mkdir /local
执行代码之后,我们在网页上查看下,在浏览器中输入"http://localost:50070",点击“Utilities --> Browse the file system“,在地址栏上输入“/”,则在dfs系统上的所有文件夹及文件都会显示,如下图:
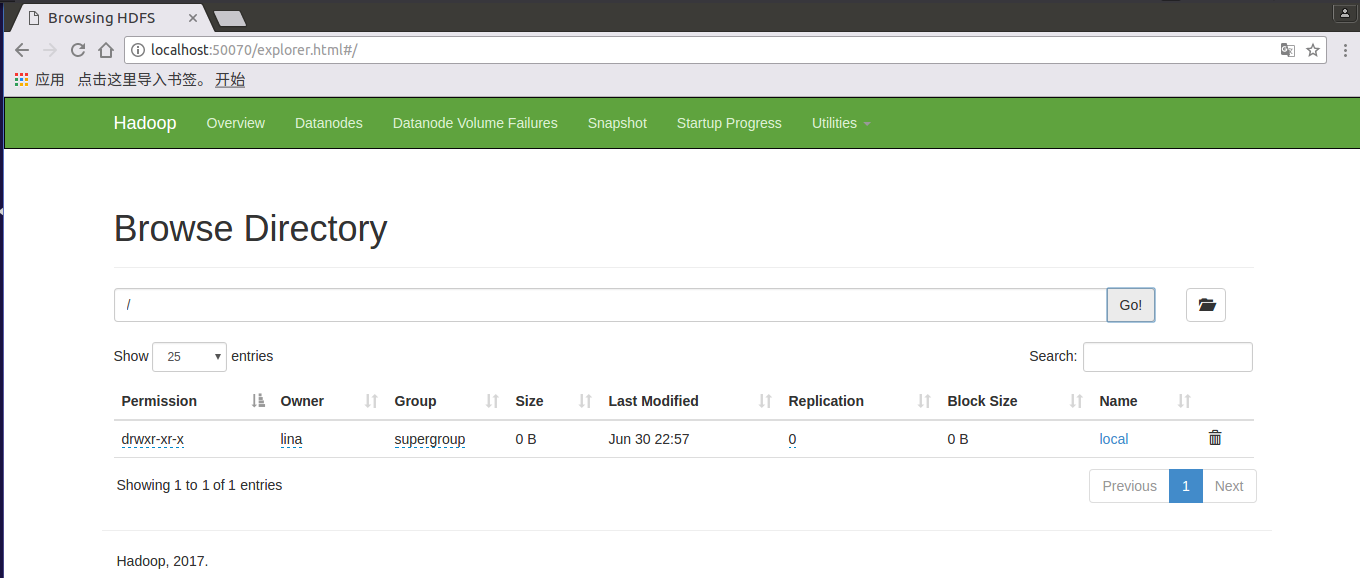
hdfs dfs -put /home/lina/input/sample.txt /local/
上传完毕,在上图中的页面上点击Name下的local链接,打开如下页面,发现sample.txt在列表中,点击sample.txt链接,会弹出sample.txt的详细信息。
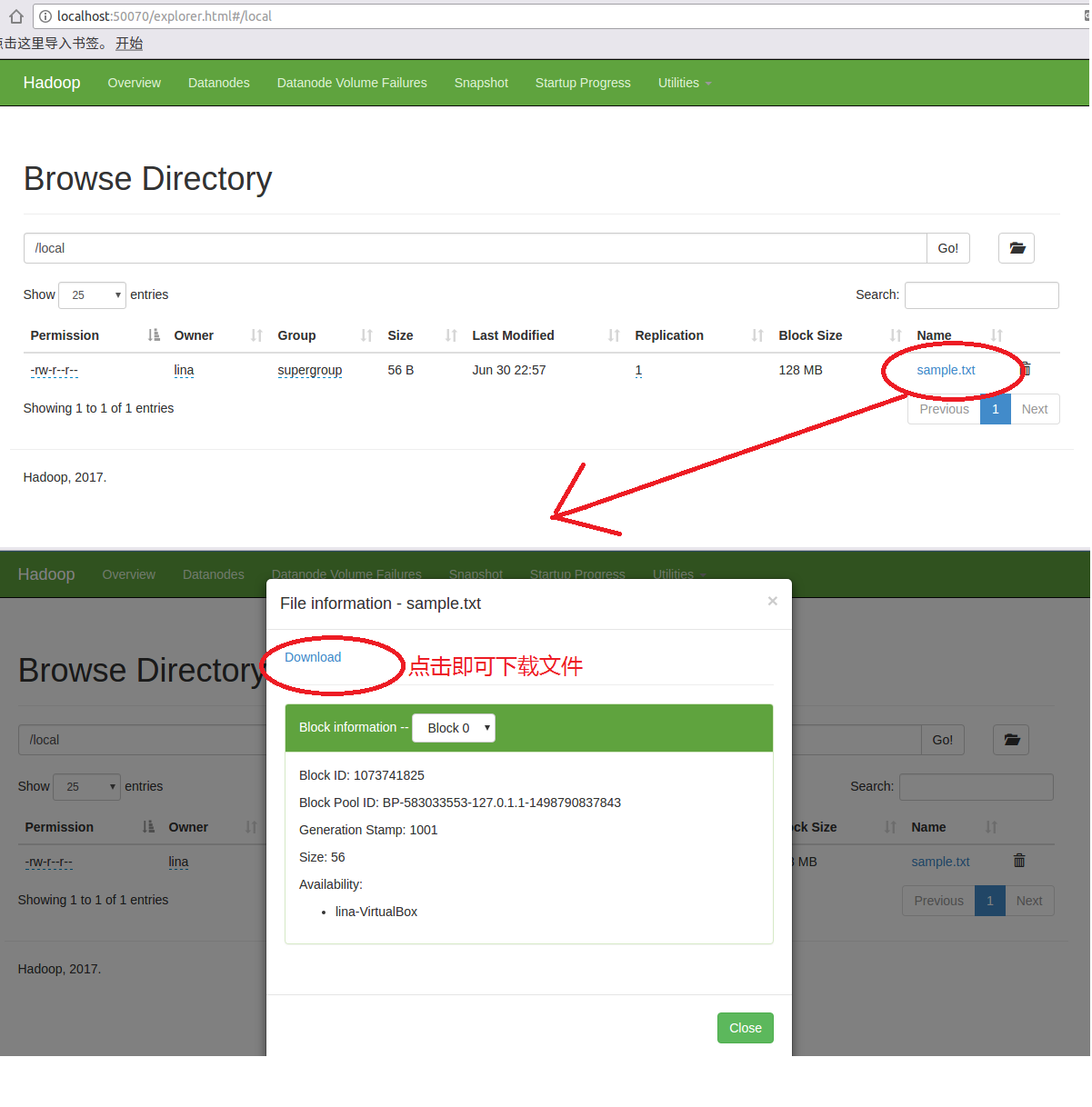
三、执行jar包
将当前目录切换到根目录,使用下面的命令:cd
hadoop jar /home/lina/example.jar com/oss/maxtemperature/MaxTemperatureDriver /local/sample.txt /output/sampleout
其中,/home/lina/example.jar是jar包所在目录,com/oss/maxtemperature/MaxTemperatureDriver是因为main程序是放在com.oss.maxtemperature包下的MaxTemperatureDriver.java下,/local/sample.txt是dfs文件系统下的sample.txt输入文件的目录,/output/sampleout是设定的输出目录。
执行完毕,在浏览器中可以看到多了一个output的文件夹,output下面有sampleout文件夹,sampleout文件夹下是输出内容,包括_SUCCESS和part-r-00000文件(与Eclipse中使用Hadoop单机模式开发配置及简单程序示例 一致),如下图:
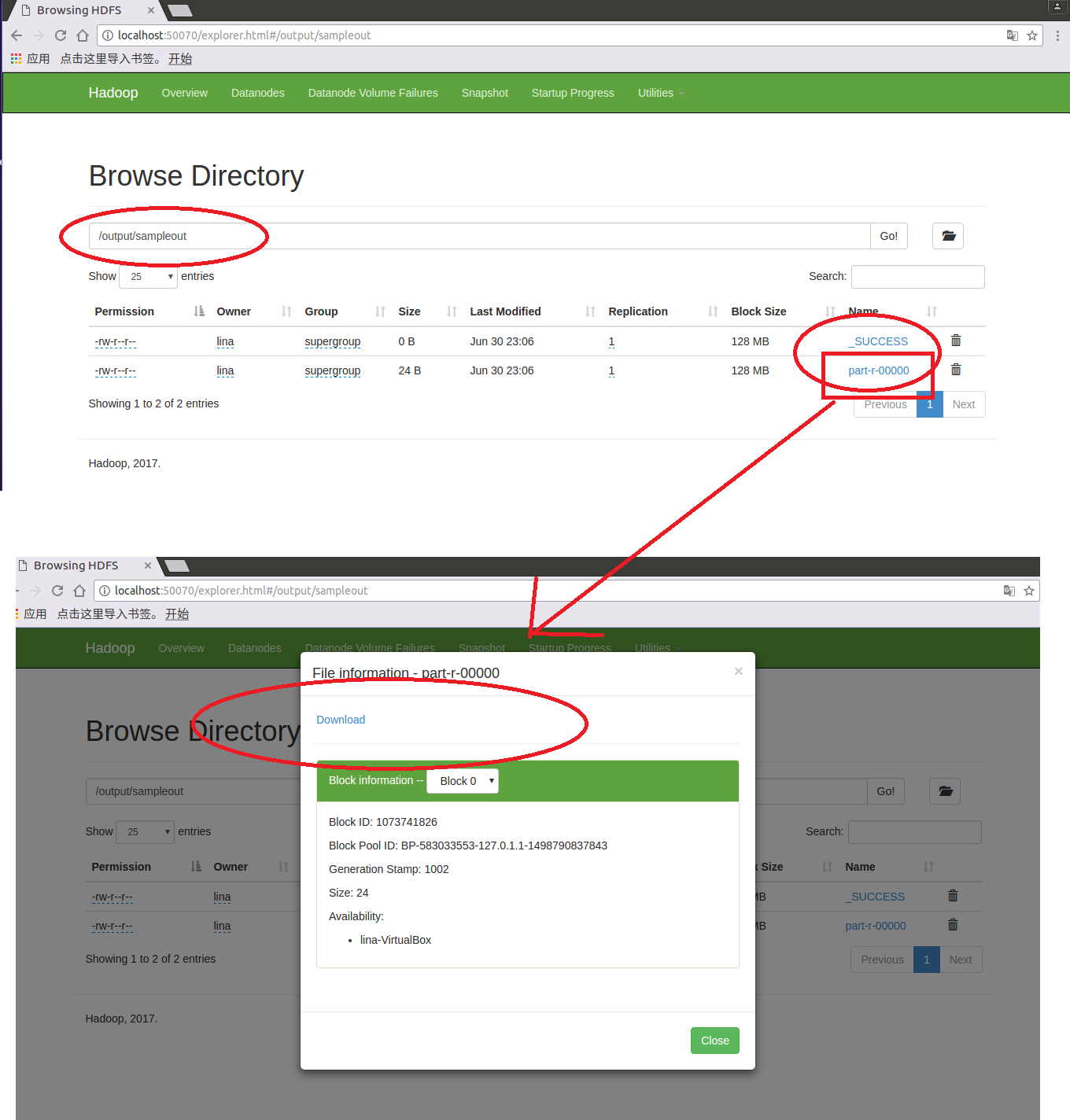
命令行截图如下:
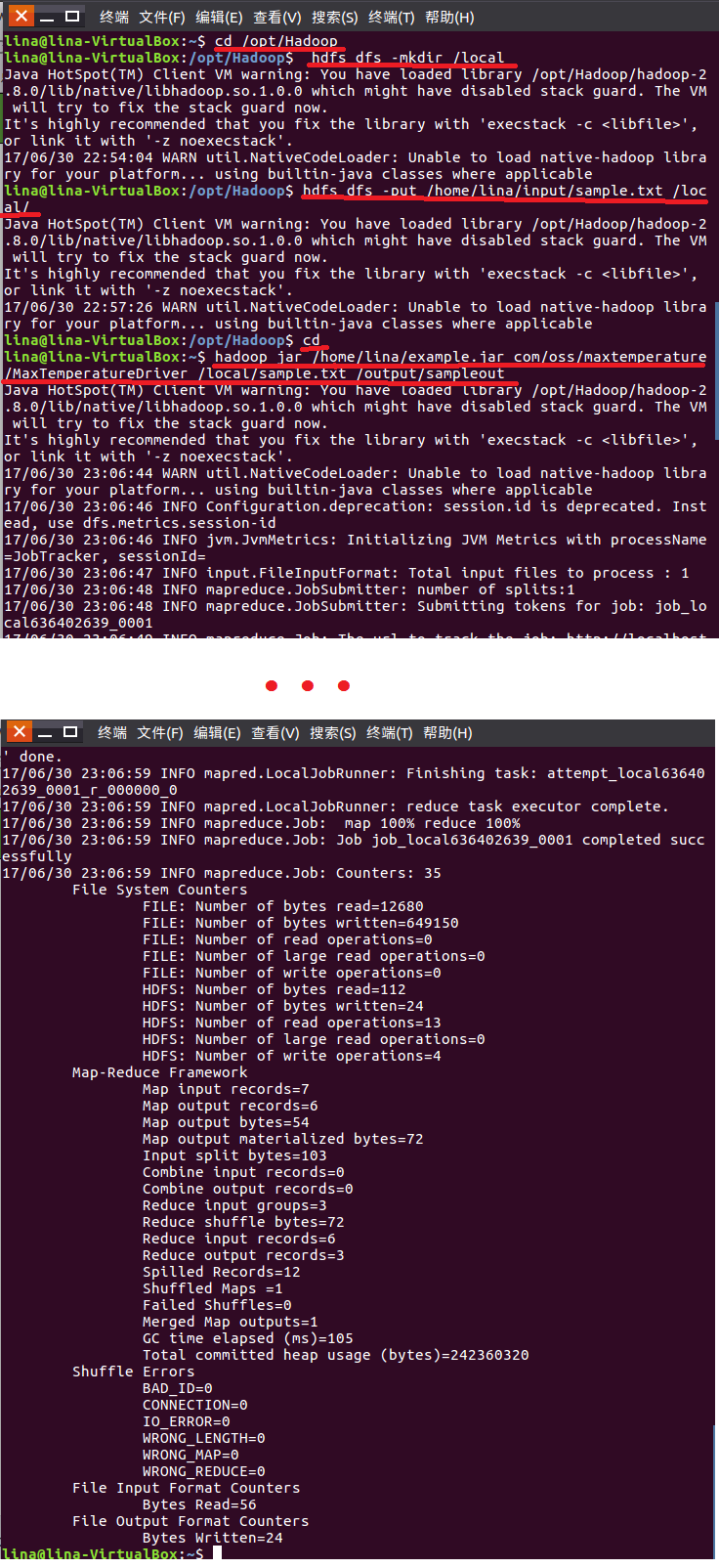
四、本地文件的查看及下载至本地
注意:若使用的是server版本的ubuntu,在其他系统的浏览器中是可以浏览的到文件夹信息的,但是在点击download的时候,会提示远程下载不成功等错误,此时处理办法如下: 1、可以使用命令行查看hdfs文件系统的信息,查看某文件夹下的文件命令和查看某个文件的命令如下:hadoop fs -ls /local //这条命令作用是查看/local文件夹下的所有文件
hadoop fs -cat /local/sample.txt //这条命令作用是查看/local文件夹下sample.txt文件的内容如图:

hadoop fs -get /output/sampleout/part-r-00000 //作用:将HDFS文件系统/output/sampleout文件夹下的part-r-00000文件下载至根目录下
hadoop fs -get /output/sampleout/part-r-00000 /home/lina/temp/ //作用:将HDFS文件系统/output/sampleout文件夹下的part-r-00000文件下载至/home/lina/temp目录下
3、删除文件的命令
hadoop fs -rm /local/sample.txt //作用:将/local文件目录下的sample.txt文件删除
hadoop fs -rm -r /local //将local文件夹及其内部的文件删除