
PrometheusЛЙЬсЙЉСЫЯТСаФкжУЕФОлКЯВйзїЗћЃЌетаЉВйзїЗћзїгУгђЫВЪБЯђСПЁЃПЩвдНЋЫВЪББэДяЪНЗЕЛиЕФбљБОЪ§ОнНјааОлКЯЃЌаЮГЩвЛИіаТЕФЪБМфађСаЁЃ
ОлКЯдЫЫуЗћДгБъЧЉЮЌЖШНјааОлКЯЃЌетаЉдЫЫуЗћдквЛИіЪБМфФкЖдЖрИіађСаНјааОлКЯ
sum(ЧѓКЭ)min(зюаЁжЕ)max(зюДѓжЕ)avg(ЦНОљжЕ)stddev(БъзМВю)-
stdvar(БъзМЗНВю) -
count(МЦЪ§) -
count_values(ЖдvalueНјааМЦЪ§) -
bottomk(КѓnЬѕЪБађ) -
topk(ЧАnЬѕЪБађ) -
quantile(ЗжЮЛЪ§)
ЪЙгУОлКЯВйзїЕФгяЗЈШчЯТЃК
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]ЦфжажЛгаcount_values, quantile, topk, bottomkжЇГжВЮЪ§(parameter)ЁЃ
withoutгУгкДгМЦЫуНсЙћжавЦГ§СаОйЕФБъЧЉЃЌЖјБЃСєЦфЫќБъЧЉЁЃbyдђе§КУЯрЗДЃЌНсЙћЯђСПжажЛБЃСєСаГіЕФБъЧЉЃЌЦфгрБъЧЉдђвЦГ§ЁЃЭЈЙ§withoutКЭbyПЩвдАДеебљБОЕФЮЪЬтЖдЪ§ОнНјааОлКЯЁЃ
Р§ШчЃК
sum(http_requests_total) without (instance)ЕШМлгк
sum(http_requests_total) by (code,handler,job,method)ШчЙћжЛашвЊМЦЫуећИігІгУЕФHTTPЧыЧѓзмСПЃЌПЩвджБНгЪЙгУБэДяЪНЃК
sum(http_requests_total)ОлКЯ
ЮвУЧжЊЕР Prometheus ЕФЪБМфађСаЪ§ОнЪЧЖрЮЌЪ§ОнФЃаЭЃЌЮвУЧОГЃОЭгаИљОнИїИіЮЌЖШНјааЛузмЕФашЧѓЁЃ
ЛљгкБъЧЉОлКЯ
- request_duration_seconds_count ОЭЪЧвЛЙВгаЖрЩйИіЧыЧѓ
- request_duration_seconds_sum ЪЧзмЕФбгГйЪБМфЃЌОЭЪЧЫљгаЧыЧѓвЛЙВЛЈСЫЖрГЄЪБМф
Р§ШчЮвУЧЯыжЊЕРЮвУЧЕФ demo ЗўЮёУПУыДІРэЕФЧыЧѓЪ§ЃЌФЧУДПЩвдНЋЕЅИіЕФЫйТЪЯрМгОЭПЩвдЁЃ
sum(rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
ПЩвдЕУЕНШчЯТЫљЪОЕФНсЙћЃК
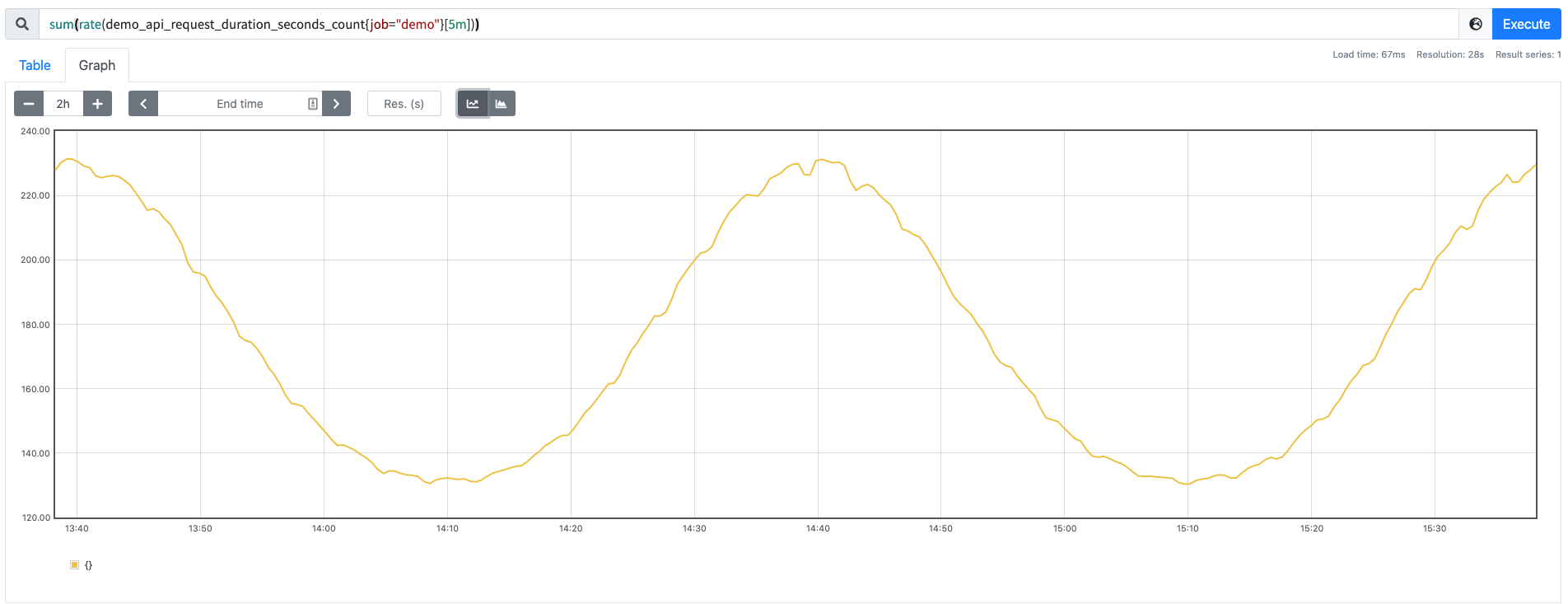
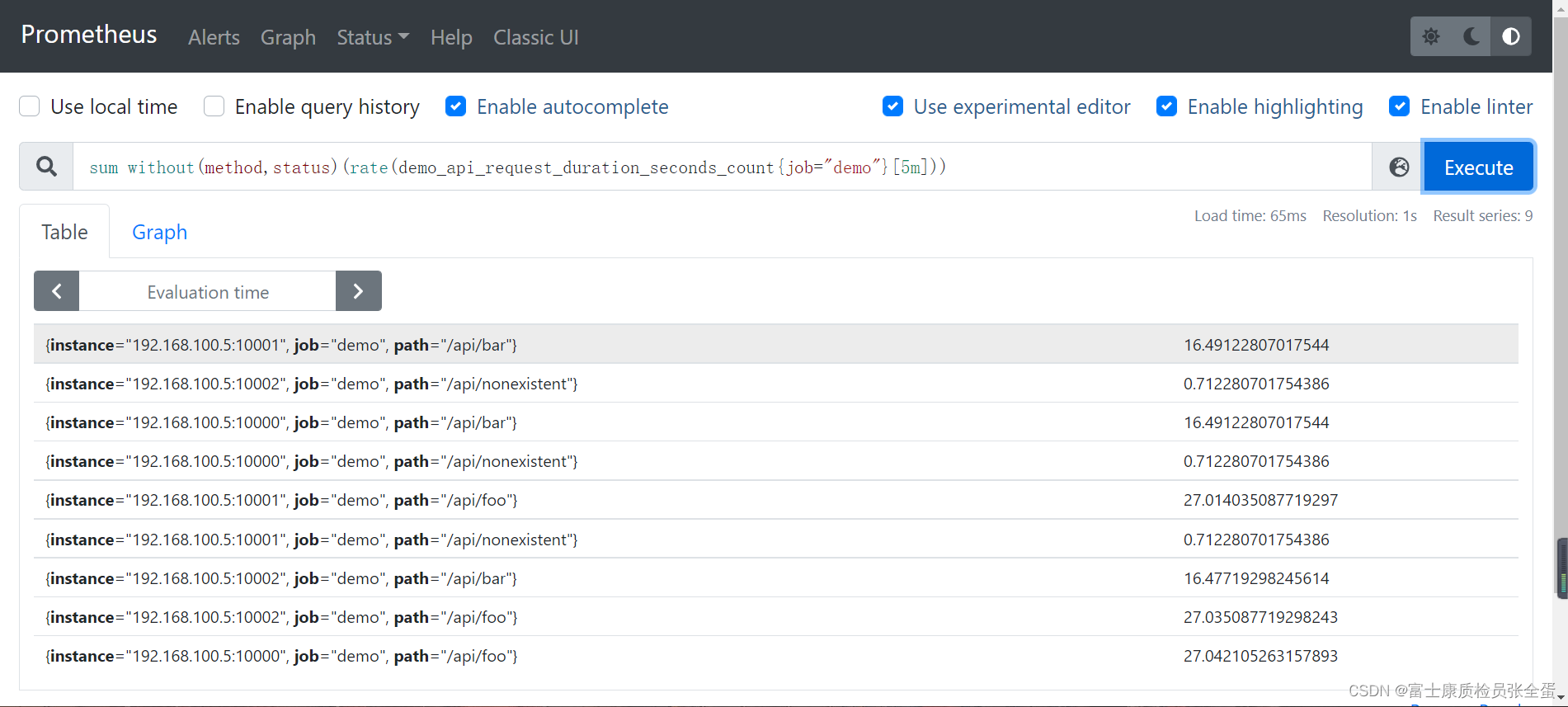
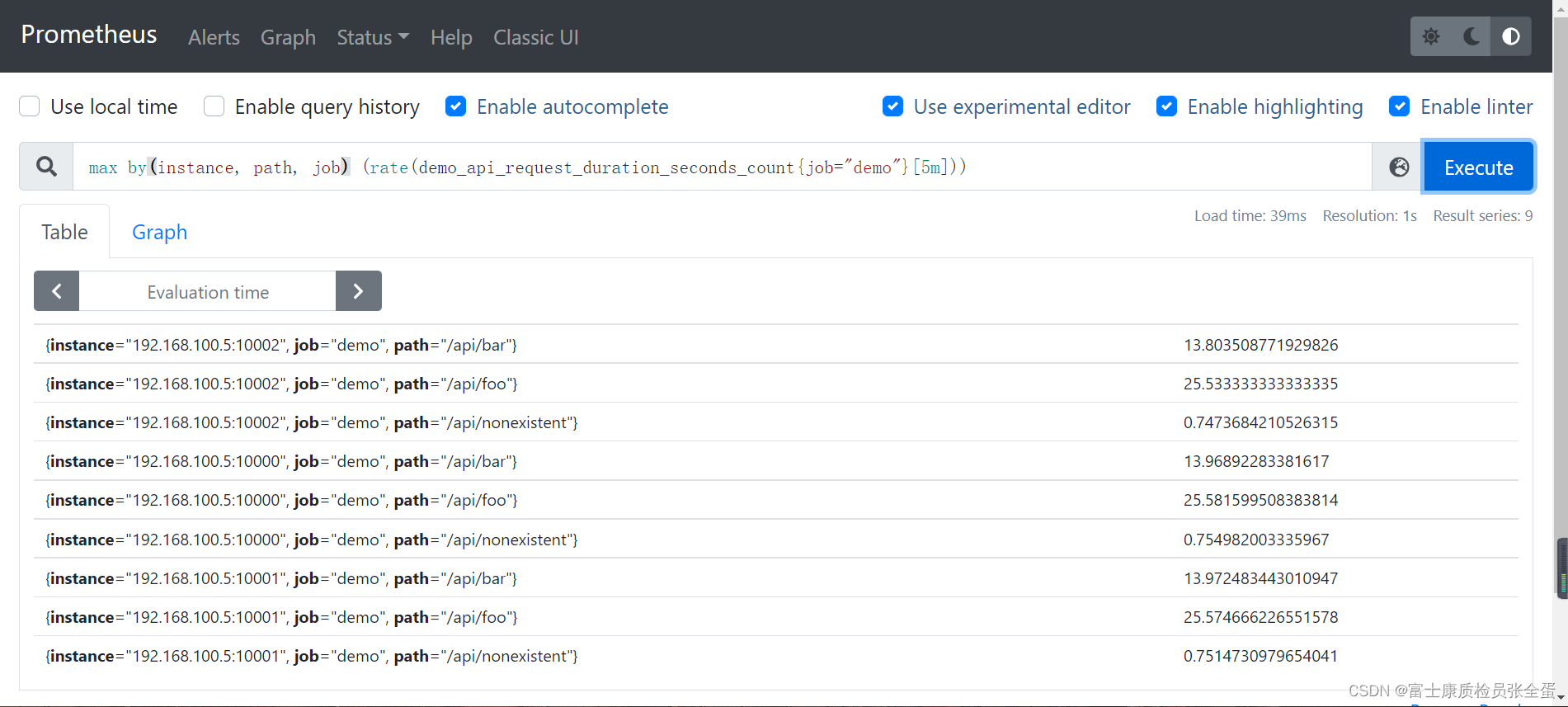
ЕЋЪЧЮвУЧПЩвдПДЕНЛцжЦГіРДЕФЭМаЮУЛгаБЃСєШЮКЮБъЧЉЮЌЖШЃЌвЛАуРДЫЕПЩФмЮвУЧЯЃЭћБЃСєвЛаЉЮЌЖШЃЌР§ШчЃЌЮвУЧПЩФмИќЯЃЭћМЦЫуУПИі instance КЭ path ЕФБфЛЏТЪЃЌЕЋВЂВЛЙиаФЕЅИі method Лђеп status ЕФНсЙћЃЌетИіЪБКђЮвУЧПЩвддк sum() ОлКЯЦїжаЬэМгвЛИі without() ЕФаоЪЮЗћЃК
sum without(method, status) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
ЩЯУцЕФВщбЏгяОфЯрЕБгкгУ by() аоЪЮЗћРДБЃСєашвЊЕФБъЧЉЕФШЁЗДВйзїЃКby()РрЫЦгкSQLгяОфРяУцЕФgroup byЃЌетРяЪЧИљОнЪВУДШЅзіОлКЯЁЃ
sum by(instance, path, job) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
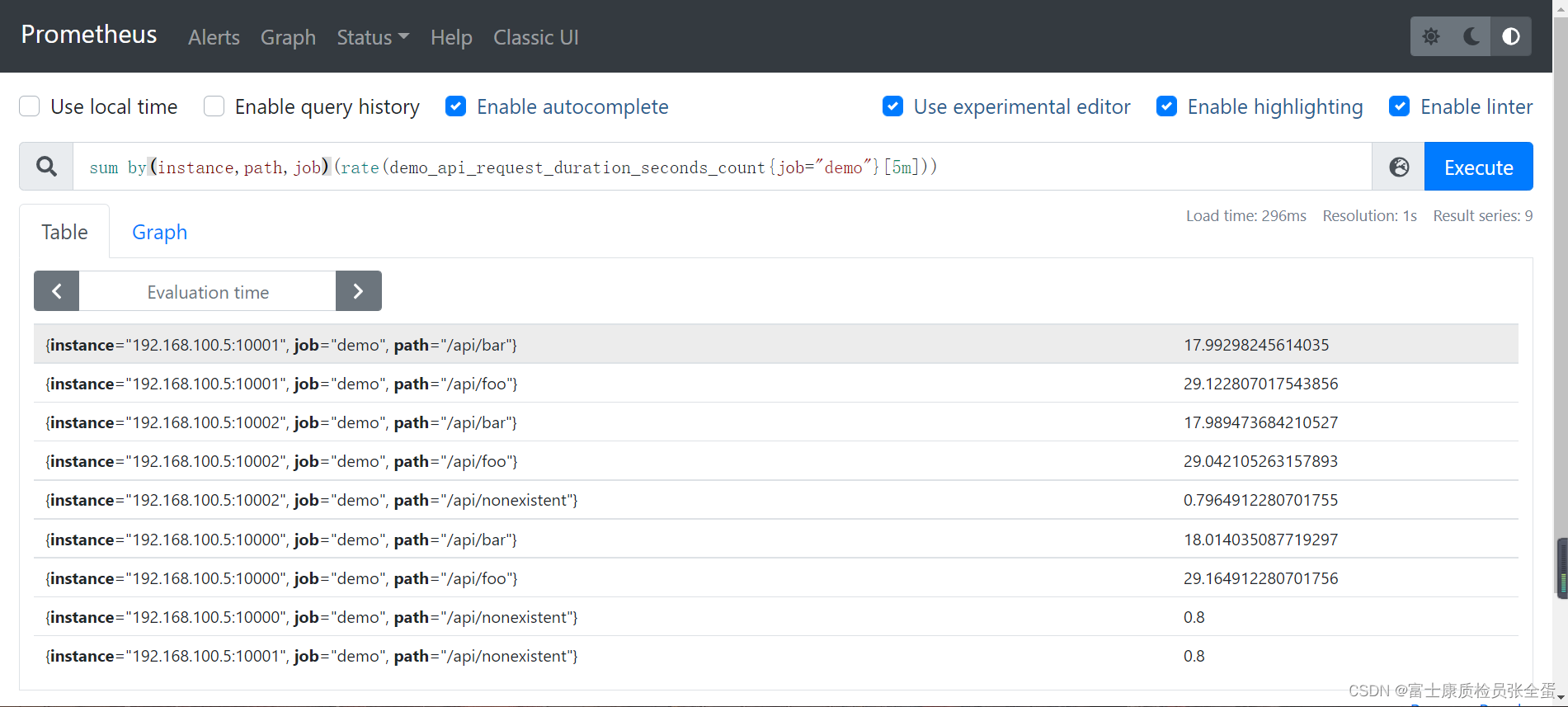 ЯждкЕУЕНЕФ sum НсЙћЪЧОЭЪЧАДее
ЯждкЕУЕНЕФ sum НсЙћЪЧОЭЪЧАДее instanceЁЂpathЁЂjob РДНјааЗжзщШЅОлКЯЕФСЫЃК
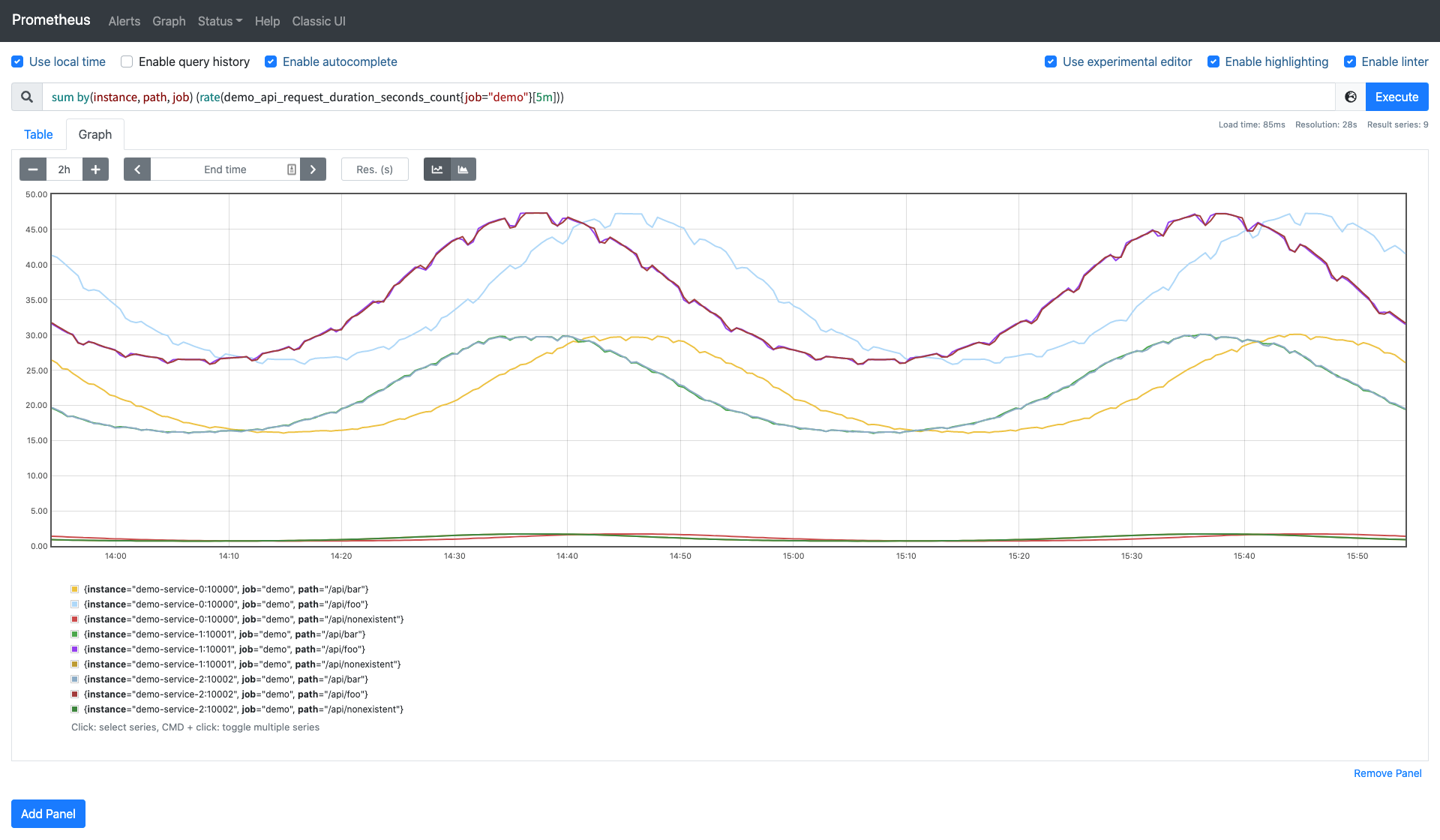
зюКѓЭЌРэapiserverвВЪЧвЛбљЕФ
sum by(verb)(rate(apiserver_request_duration_seconds_count[5m]))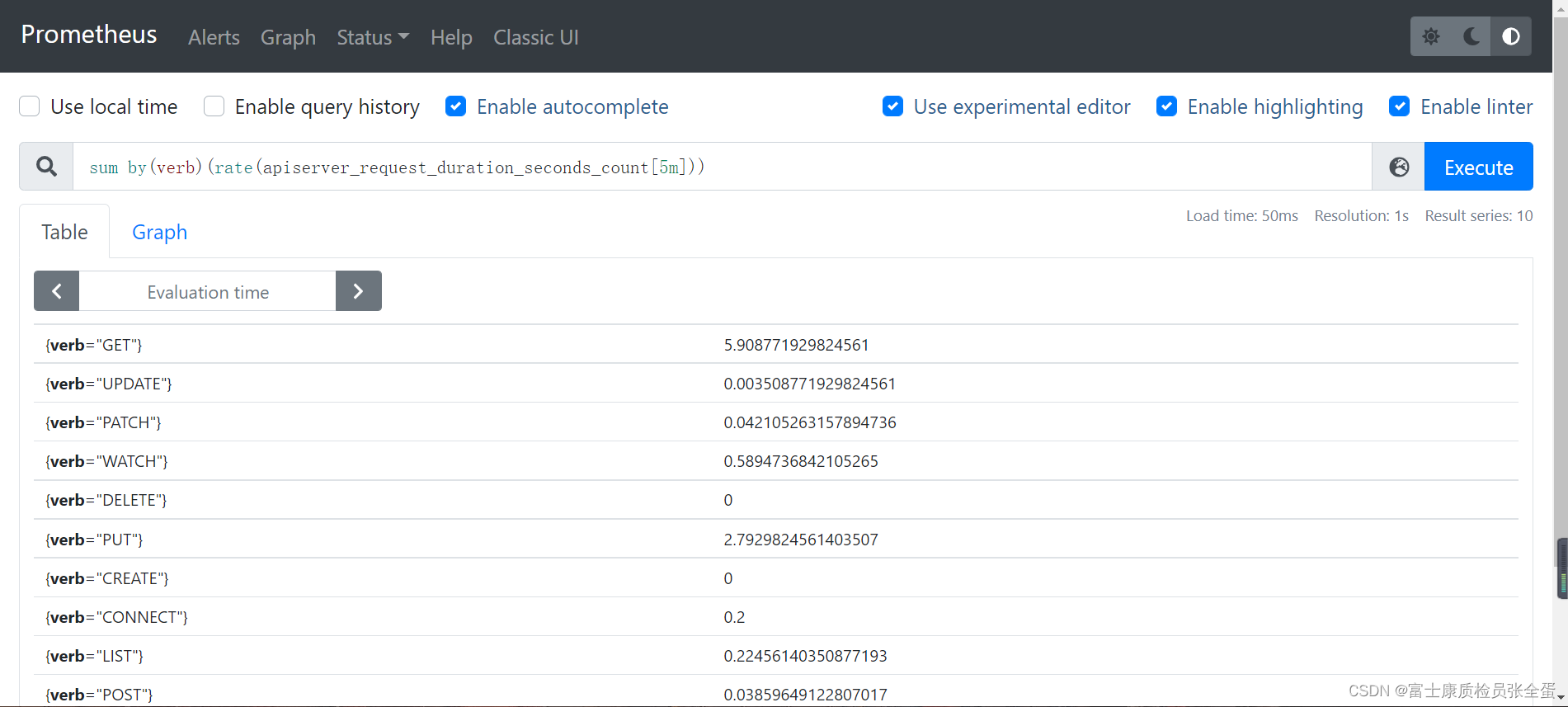
етРяЕФЗжзщИХФюКЭ SQL гяОфжаЕФЗжзщШЅОлКЯОЭЗЧГЃРрЫЦСЫЁЃ
Г§СЫ sum() жЎЭтЃЌPrometheus ЛЙжЇГжЯТУцЕФетаЉОлКЯЦї/ОлКЯКЏЪ§ЃКЃЈШчЙћВЛМгЩЯbyНјааЗжзщЃЌФЧУДМЦЫуЕФЪЧећИіЪБМфађСаЕФжЕЃЌжЛЪЧвЛИіжЕЖјвбЃЌУЛгаБъЧЉЮЌЖШЃЉ
sum()ЃКЖдОлКЯЗжзщжаЕФЫљгажЕНјааЧѓКЭmin()ЃКЛёШЁвЛИіОлКЯЗжзщжазюаЁжЕmax()ЃКЛёШЁвЛИіОлКЯЗжзщжазюДѓжЕavg()ЃКМЦЫуОлКЯЗжзщжаЫљгажЕЕФЦНОљжЕstddev()ЃКМЦЫуОлКЯЗжзщжаЫљгаЪ§жЕЕФБъзМВюstdvar()ЃКМЦЫуОлКЯЗжзщжаЫљгаЪ§жЕЕФБъзМЗНВюcount()ЃКМЦЫуОлКЯЗжзщжаЫљгаађСаЕФзмЪ§ МЦЫуађСаЕФзмЪ§,вЊКЭsumШЁЗжПЊcount_values()ЃКМЦЫуОпгаЯрЭЌбљБОжЕЕФдЊЫиЪ§СПbottomk(k, ...)ЃКМЦЫуАДбљБОжЕМЦЫуЕФзюаЁЕФ k ИідЊЫиtopk(kЃЌ...)ЃКМЦЫузюДѓЕФ k ИідЊЫиЕФбљБОжЕquantile(ІеЃЌ...)ЃКМЦЫуЮЌЖШЩЯЕФ Іе-ЗжЮЛЪ§(0ЁмІеЁм1)group(...)ЃКжЛЪЧАДБъЧЉЗжзщЃЌВЂНЋбљБОжЕЩшЮЊ 1ЁЃ
СЗЯАЃК
1.АД
jobЗжзщОлКЯЃЌМЦЫуЮвУЧе§дкМрПиЕФЫљгаНјГЬЕФзмФкДцЪЙгУСПЃЈprocess_resident_memory_bytesжИБъЃЉЃКsum by(job) (process_resident_memory_bytes)
2.МЦЫу жИБъгаЖрЩйВЛЭЌЕФ CPU ФЃЪНЃК
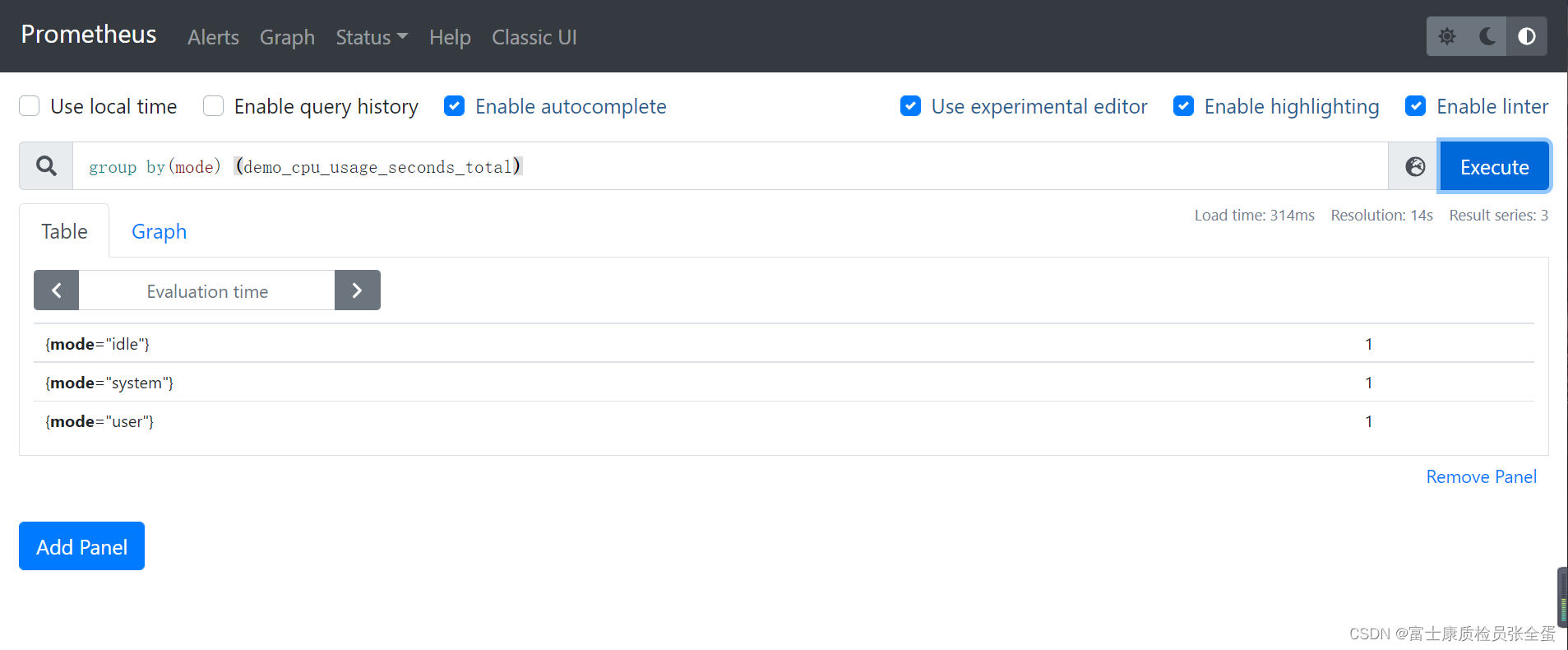
count (group by(mode) (demo_cpu_usage_seconds_total))
3.МЦЫуУПИі job ШЮЮёКЭжИБъУћГЦЕФЪБМфађСаЪ§СПЃК
count by (job, __name__) ({__name__ != ""})УПИіжИБъРяУцЖМга_name_
ЛљгкЪБМфОлКЯ(GaugeРраЭ)
ЧАУцЮвУЧвбОбЇЯАСЫШчКЮЪЙгУ sum()ЁЂavg() КЭЯрЙиЕФОлКЯдЫЫуЗћДгБъЧЉЮЌЖШНјааОлКЯЃЌетаЉдЫЫуЗћдквЛИіЪБМфФкЖдЖрИіађСаНјааОлКЯЃЌЕЋЪЧгаЪБКђЮвУЧПЩФмЯыдкУПИіађСажаАДЪБМфНјааОлКЯЃЌР§ШчЃЌЪЙМтШёЕФЧњЯпИќЦНЛЌЃЌЛђЩюШыСЫНтвЛИіађСадквЛЖЮЪБМфФкЕФзюДѓжЕЁЃ
ЮЊСЫЛљгкЪБМфРДМЦЫуетаЉОлКЯЃЌPromQL ЬсЙЉСЫвЛаЉгыБъЧЉОлКЯдЫЫуЗћРрЫЦЕФКЏЪ§ЃЌЕЋЪЧдкетаЉКЏЪ§УћЧАУцИНМгСЫ _over_time()
<aggregation>_over_time()
ЯТУцЕФКЏЪ§СаБэдЪаэДЋШывЛИіЧјМфЯђСПЃЌЫќУЧЛсОлКЯУПИіЪБМфађСаЕФЗЖЮЇЃЌВЂЗЕЛивЛИіЫВЪБЯђСПЃК
avg_over_time(range-vector)ЃКЧјМфЯђСПФкУПИіжИБъЕФЦНОљжЕЁЃmin_over_time(range-vector)ЃКЧјМфЯђСПФкУПИіжИБъЕФзюаЁжЕЁЃmax_over_time(range-vector)ЃКЧјМфЯђСПФкУПИіжИБъЕФзюДѓжЕЁЃsum_over_time(range-vector)ЃКЧјМфЯђСПФкУПИіжИБъЕФЧѓКЭЁЃcount_over_time(range-vector)ЃКЧјМфЯђСПФкУПИіжИБъЕФбљБОЪ§ОнИіЪ§ЁЃquantile_over_time(scalar, range-vector)ЃКЧјМфЯђСПФкУПИіжИБъЕФбљБОЪ§ОнжЕЗжЮЛЪ§ЁЃstddev_over_time(range-vector)ЃКЧјМфЯђСПФкУПИіжИБъЕФзмЬхБъзМВюЁЃstdvar_over_time(range-vector)ЃКЧјМфЯђСПФкУПИіжИБъЕФзмЬхБъзМЗНВюЁЃ
[info] зЂвт
МДЪЙЧјМфЯђСПФкЕФжЕЗжВМВЛОљдШЃЌЫќУЧдкОлКЯЪБЕФШЈживВЪЧЯрЭЌЕФЁЃ
Р§ШчЃЌЮвУЧВщбЏ demo ЪЕР§жаЪЙгУЕФ goroutine ЕФдЪМЪ§СПЃЌПЩвдЪЙгУВщбЏгяОф go_goroutines{job="demo"}ЃЌетЛсВњЩњвЛаЉМтШёЕФЗхжЕЭМЃК
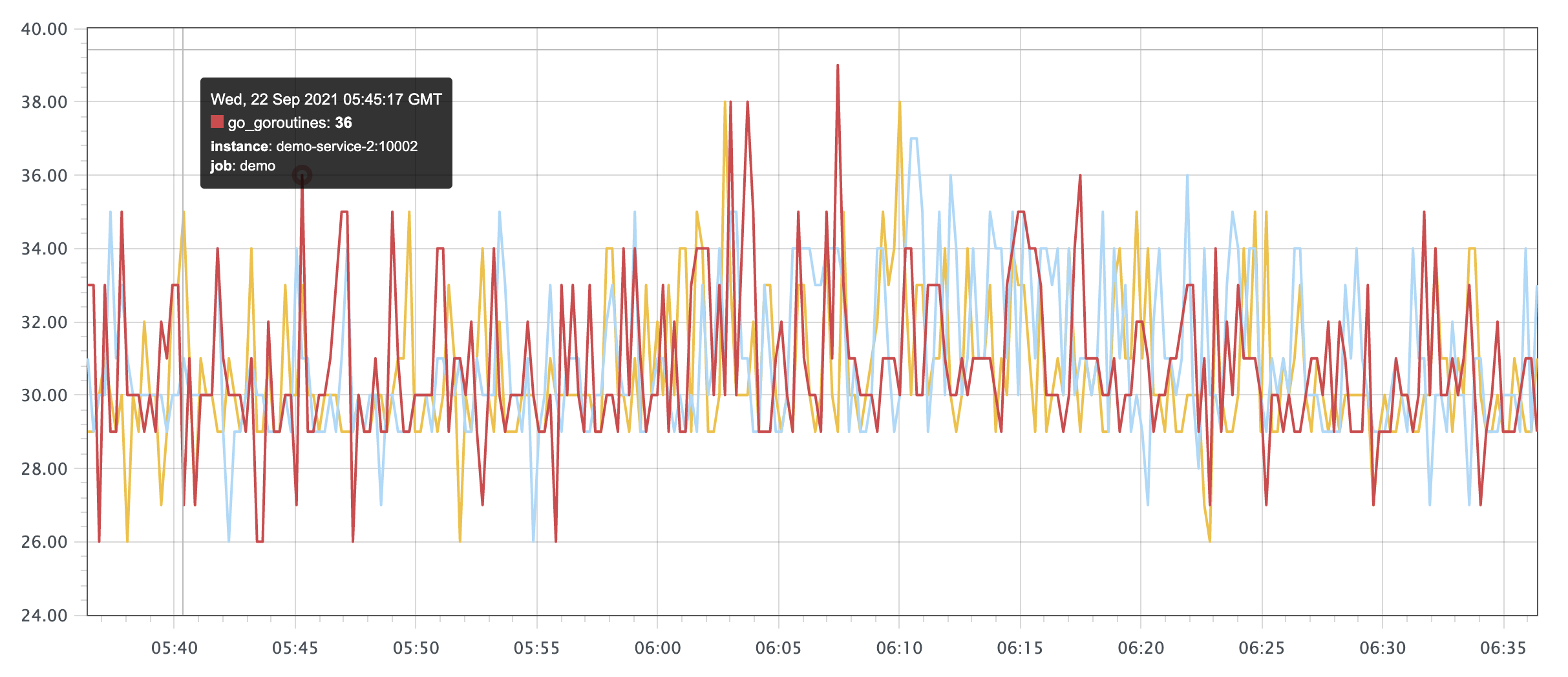
ЮвУЧПЩвдЭЈЙ§ЖдЭМжаЕФУПвЛИіЕуРДМЦЫу 10 ЗжжгФкЕФ goroutines Ъ§СПНјааЦНОљРДЪЙЭМаЮИќМгЦНЛЌЃК
ЫћвЊЫуЪЎЗжжгжЎФкЕФЦНОљжЕЃЌЦфЪЕОЭЪЧНЋетаЉжЕШЋВПМгЦ№РДЧѓЦНОљЁЃ
 ПЩвдПДЕНМЦЫуЕФЦНОљжЕ
ПЩвдПДЕНМЦЫуЕФЦНОљжЕ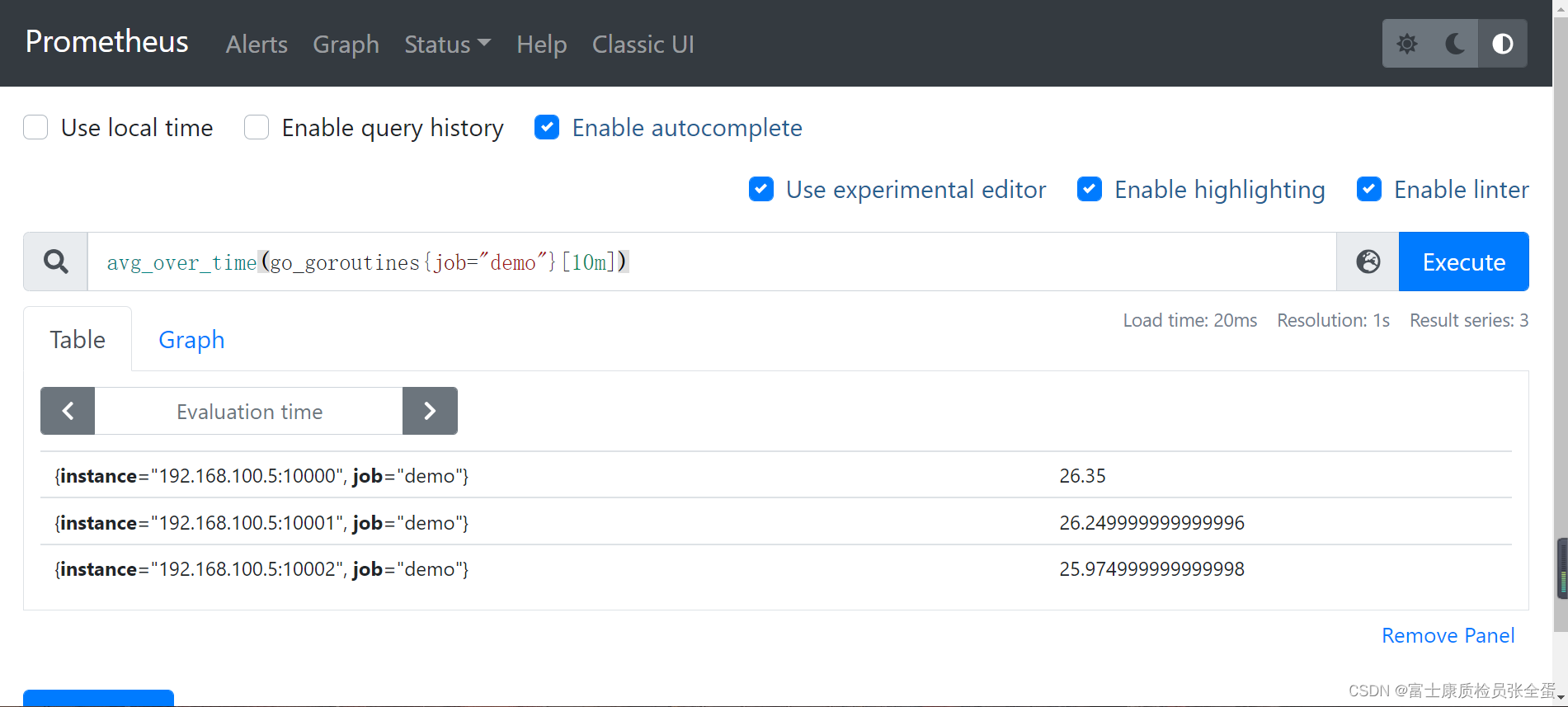
avg_over_time(go_goroutines{job="demo"}[10m])
етИіВщбЏНсЙћЩњГЩЕФЭМБэПДЦ№РДОЭЦНЛЌКмЖрСЫЃК
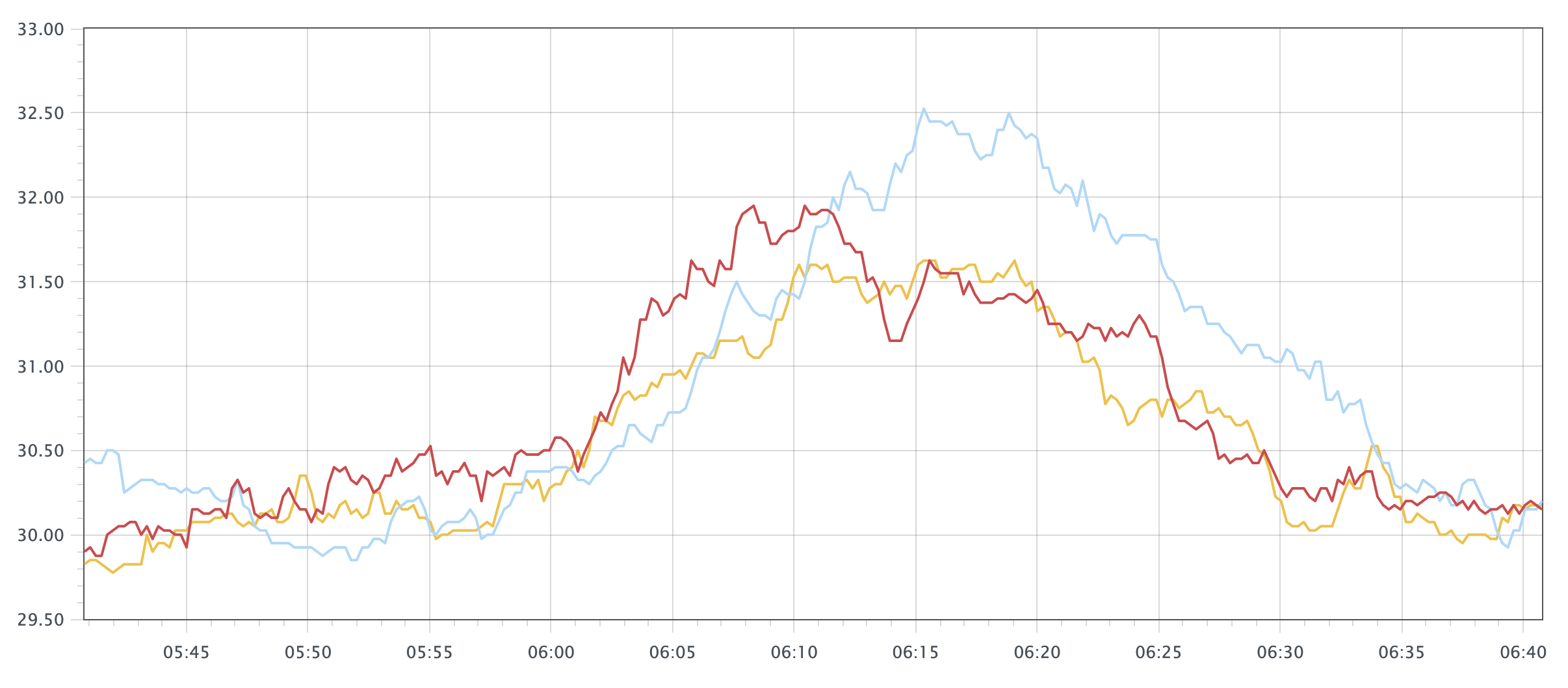
БШШчвЊВщбЏ 1 аЁЪБФкФкДцЕФЪЙгУТЪдђПЩвдгУЯТУцЕФВщбЏгяОфЃК
100 * (1 - ((avg_over_time(node_memory_MemFree_bytes[1h]) + avg_over_time(node_memory_Cached_bytes[1h]) + avg_over_time(node_memory_Buffers_bytes[1h])) / avg_over_time(node_memory_MemTotal_bytes[1h])))
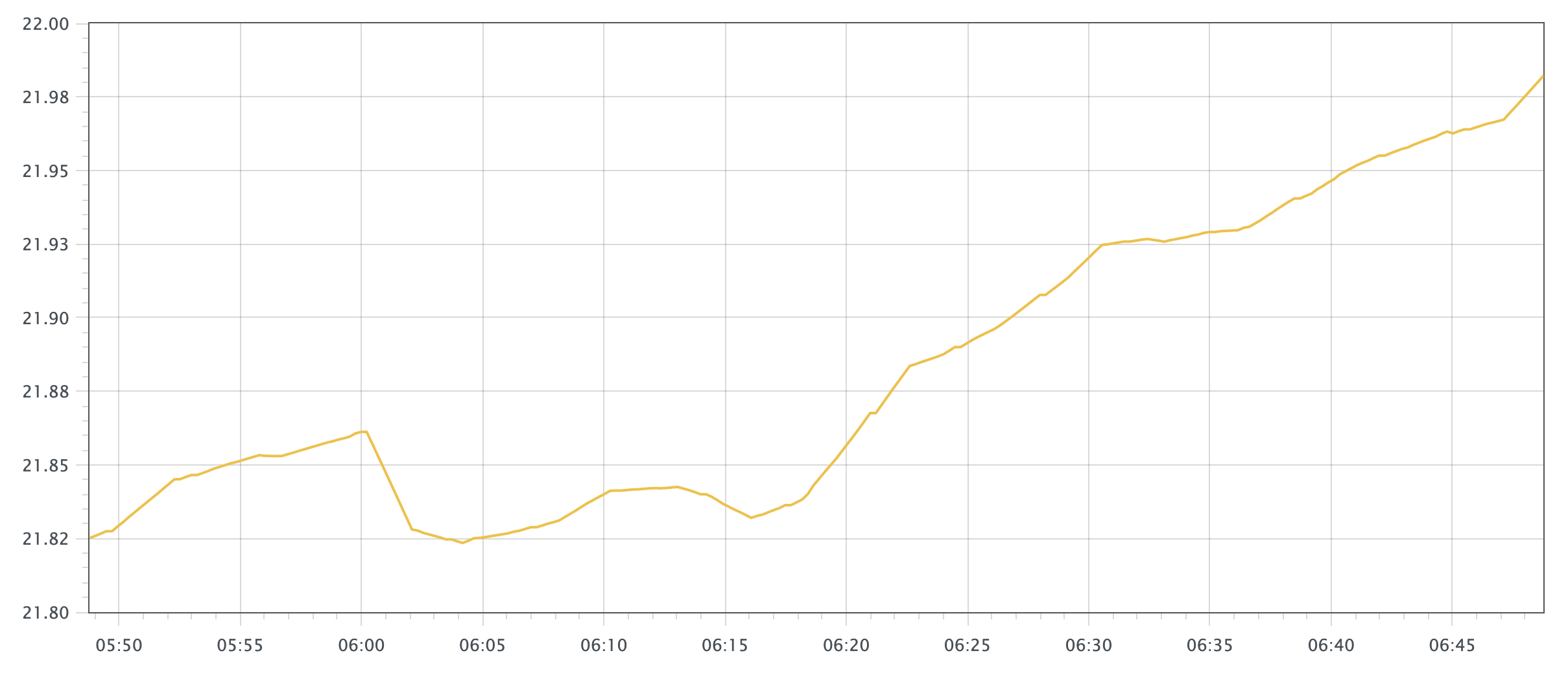
згВщбЏ
ЩЯУцЫљгаЕФ _over_time() КЏЪ§ЖМашвЊвЛИіЗЖЮЇЯђСПзїЮЊЪфШы(БШШч[5m])ЃЌЭЈГЃЧщПіЯТжЛФмгЩвЛИіЧјМфЯђСПбЁдёЦїРДВњЩњЃЌБШШч my_metric[5m]ЁЃЕЋЪЧШчЙћЯждкЮвУЧЯыЪЙгУР§Шч max_over_time() КЏЪ§РДевГіЙ§ШЅвЛЬьжа demo ЗўЮёЕФзюДѓЧыЧѓТЪгІИУдѕУДАьФиЃП
ЧыЧѓТЪ rate ВЂВЛЪЧвЛИіЮвУЧПЩвджБНгбЁдёЪБМфЕФдЪМжЕЃЌЖјЪЧвЛИіМЦЫуКѓЕУЕНЕФжЕЃЌБШШчЃК
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
ШчЙћЮвУЧжБНгНЋБэДяЪНДЋШы max_over_time() ВЂИНМгвЛЬьЕФГжајЪБМфВщбЏЕФЛАОЭЛсВњЩњДэЮѓЃК
# ERROR!
max_over_time(rate(demo_api_request_duration_seconds_count{job="demo"}[5m])[1d]
)
ЪЕМЪЩЯ Prometheus ЪЧжЇГжзгВщбЏЕФЃЌЫќдЪаэЮвУЧЪзЯШвджИЖЈЕФВНГЄдквЛЖЮЪБМфФкжДааФкВПВщбЏЃЌШЛКѓИљОнзгВщбЏЕФНсЙћМЦЫуЭтВПВщбЏЁЃзгВщбЏЕФБэЪОЗНЪНРрЫЦгкЧјМфЯђСПЕФГжајЪБМфЃЌЕЋашвЊУАКХКѓЬэМгСЫвЛИіЖюЭтЕФВНГЄВЮЪ§ЃК[<duration>:<resolution>]ЁЃ
етбљЮвУЧПЩвджиаДЩЯУцЕФВщбЏгяОфЃЌИцЫп Prometheus дквЛЬьЕФЗЖЮЇФкЦРЙРФкВПБэДяЪНЃЌВНГЄЗжБцТЪЮЊ 15sЃК
max_over_time(rate(demo_api_request_duration_seconds_count{job="demo"}[5m])[1d:15s] # дк1ЬьФкУїШЗЕиЦРЙРФкВПВщбЏЃЌВНГЄЮЊ15Уы
)
вВПЩвдЪЁТдУАКХКѓЕФВНГЄЃЌдкетжжЧщПіЯТЃЌPrometheus ЛсЪЙгУХфжУЕФШЋОж evaluation_interval ВЮЪ§НјааЦРЙРФкВПБэДяЪНЃК
max_over_time(rate(demo_api_request_duration_seconds_count{job="demo"}[5m])[1d:]
)
етбљОЭПЩвдЕУЕНЙ§ШЅвЛЬьжа demo ЗўЮёзюДѓЕФ 5 ЗжжгЧыЧѓТЪЃЌВЛЙ§УАКХШдШЛЪЧашвЊЕФЃЌвдУїШЗБэЪОдЫаазгВщбЏЁЃзгВщбЏЛЙдЪаэЬэМгвЛИіЦЋвЦаоЪЮЗћ offset РДЖдФкВПВщбЏНјааЪБМфЦЋвЦЃЌРрЫЦгкЫВЪБКЭЧјМфЯђСПбЁдёЦїЁЃ
ЕЋЪЧвВашвЊзЂвтГЄЪБМфМЦЫузгВщбЏДњМлвВЪЧЗЧГЃАКЙѓЕФЃЌЮвУЧПЩвдЪЙгУМЧТМЙцдђЃЈКѓајЛсНВНтЃЉдЄЯШМЧТМжаМфЕФБэДяЪНЃЌЖјВЛЪЧУПДЮдЫааЭтВПВщбЏЪБЖМЪЕЪБМЦЫуЫќЁЃ
СЗЯАЃК
- ЪфГіЙ§ШЅвЛаЁЪБФк demo ЗўЮёЕФзюДѓ 95 ЗжЮЛЪ§бгГйжЕЃЈ1 ЗжжгФкЦНОљЃЉЃЌАД path ЛЎЗжЃК
max_over_time(histogram_quantile(0.95, sum by(le, path) (rate(demo_api_request_duration_seconds_bucket[1m])))[1h:] )