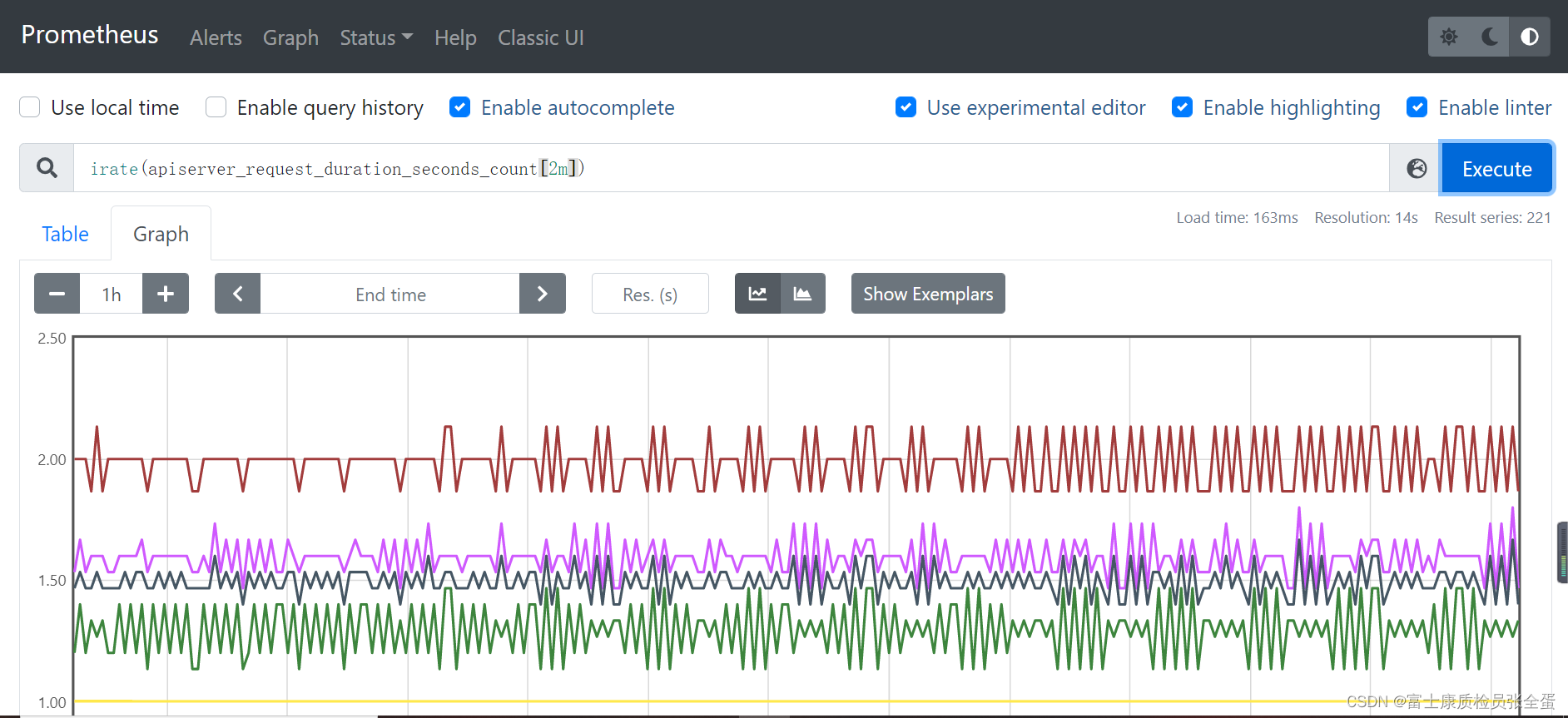
我们知道Counter类型的监控指标其特点是只增不减,在没有发生重置(如服务器重启,应用重启)的情况下其样本值应该是不断增大的。为了能够更直观的表示样本数据的变化剧烈情况,需要计算样本的增长速率。
如下图所示,样本增长率反映出了样本变化的剧烈程度:
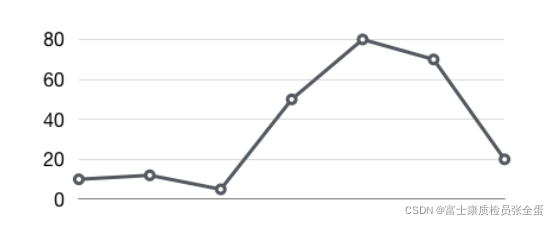
通过增长率表示样本的变化情况
increase(v range-vector)函数是PromQL中提供的众多内置函数之一。其中参数v是一个区间向量,increase函数获取区间向量中的第一个后最后一个样本并返回其增长量。因此,可以通过以下表达式Counter类型指标的增长率:
指标node_cpu所获取到的样本数据却不同,它是一个持续增大的值,因为其反应的是CPU的累积使用时间,从理论上讲只要系统不关机,这个值是会无限变大的。
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。
increase(node_cpu[2m]) / 120这里通过node_cpu[2m]获取时间序列最近两分钟的所有样本,increase计算出最近两分钟的增长量,最后除以时间120秒得到node_cpu样本在最近两分钟的平均增长率。并且这个值也近似于主机节点最近两分钟内的平均CPU使用率。
CPU 监控
对于节点我们首先能想到的就是要先对 CPU 进行监控,因为 CPU 是处理任务的核心,根据 CPU 的状态可以分析出当前系统的健康状态。要对节点进行 CPU 监控,需要用到 node_cpu_seconds_total 这个监控指标,在 metrics 接口中该指标内容如下所示:
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 13172.76
node_cpu_seconds_total{cpu="0",mode="iowait"} 0.25
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.01
node_cpu_seconds_total{cpu="0",mode="softirq"} 87.99
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 309.38
node_cpu_seconds_total{cpu="0",mode="user"} 79.93
node_cpu_seconds_total{cpu="1",mode="idle"} 13168.98
node_cpu_seconds_total{cpu="1",mode="iowait"} 0.27
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 0
node_cpu_seconds_total{cpu="1",mode="softirq"} 74.1
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 314.71
node_cpu_seconds_total{cpu="1",mode="user"} 78.83
node_cpu_seconds_total{cpu="2",mode="idle"} 13182.78
node_cpu_seconds_total{cpu="2",mode="iowait"} 0.69
node_cpu_seconds_total{cpu="2",mode="irq"} 0
node_cpu_seconds_total{cpu="2",mode="nice"} 0
node_cpu_seconds_total{cpu="2",mode="softirq"} 66.01
node_cpu_seconds_total{cpu="2",mode="steal"} 0
node_cpu_seconds_total{cpu="2",mode="system"} 309.09
node_cpu_seconds_total{cpu="2",mode="user"} 79.44
node_cpu_seconds_total{cpu="3",mode="idle"} 13185.13
node_cpu_seconds_total{cpu="3",mode="iowait"} 0.18
node_cpu_seconds_total{cpu="3",mode="irq"} 0
node_cpu_seconds_total{cpu="3",mode="nice"} 0
node_cpu_seconds_total{cpu="3",mode="softirq"} 64.49
node_cpu_seconds_total{cpu="3",mode="steal"} 0
node_cpu_seconds_total{cpu="3",mode="system"} 305.86
node_cpu_seconds_total{cpu="3",mode="user"} 78.17
从接口中描述可以看出该指标是用来统计 CPU 每种模式下所花费的时间,是一个 Counter 类型的指标,也就是会一直增长,这个数值其实是 CPU 时间片的一个累积值,意思就是从操作系统启动起来 CPU 开始工作,就开始记录自己总共使用的时间,然后保存下来,而且这里的累积的 CPU 使用时间还会分成几个不同的模式,比如用户态使用时间、空闲时间、中断时间、内核态使用时间等等,也就是平时我们使用 top 命令查看的 CPU 的相关信息,而我们这里的这个指标会分别对这些模式进行记录。
接下来我们来对节点的 CPU 进行监控,我们也知道一个一直增长的 CPU 时间对我们意义不大,一般我们更希望监控的是节点的 CPU 使用率,也就是我们使用 top 命令看到的百分比。
要计算 CPU 的使用率,那么就需要搞清楚这个使用率的含义,CPU 使用率是 CPU 除空闲(idle)状态之外的其他所有 CPU 状态的时间总和除以总的 CPU 时间得到的结果,理解了这个概念后就可以写出正确的 promql 查询语句了。
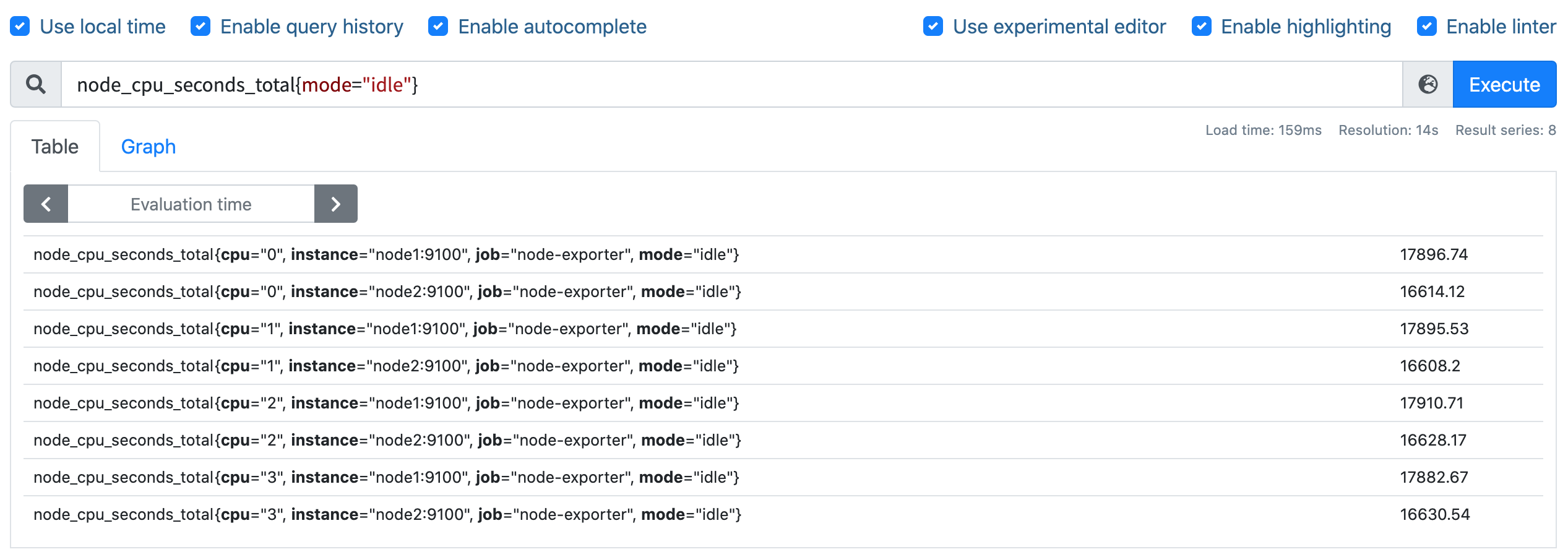
要计算除空闲状态之外的 CPU 时间总和,更好的方式是不是直接计算空闲状态的 CPU 时间使用率,然后用 1 减掉就是我们想要的结果了,所以首先我们先过滤 idle 模式的指标,在 Prometheus 的 WebUI 中输入 node_cpu_seconds_total{mode="idle"} 进行过滤:
要计算使用率,肯定就需要知道 idle 模式的 CPU 用了多长时间,然后和总的进行对比,由于这是 Counter 指标,我们可以用 increase 函数来获取变化,使用查询语句 increase(node_cpu_seconds_total{mode="idle"}[1m]),因为 increase 函数要求输入一个区间向量,所以这里我们取 1 分钟内的数据:
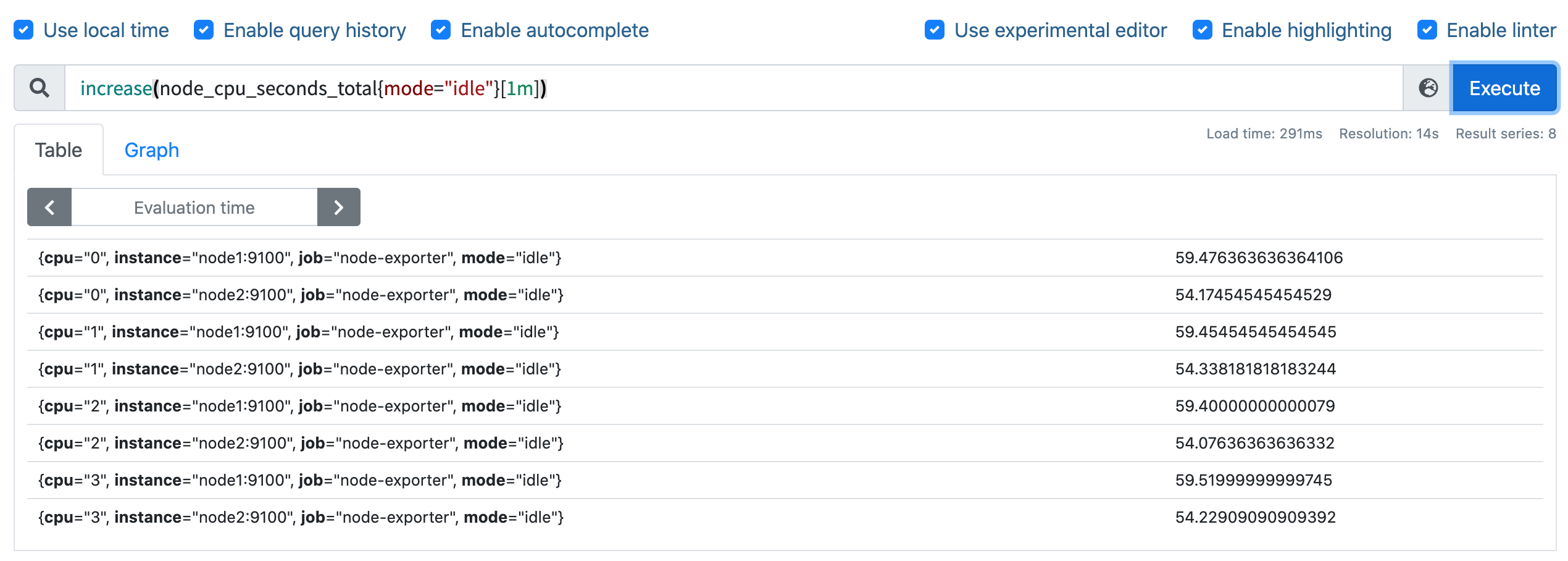
我们可以看到查询结果中有很多不同 cpu 序号的数据,我们当然需要计算所有 CPU 的时间,所以我们将它们聚合起来,我们要查询的是不同节点的 CPU 使用率,所以就需要根据 instance 标签进行聚合,使用查询语句 sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance):
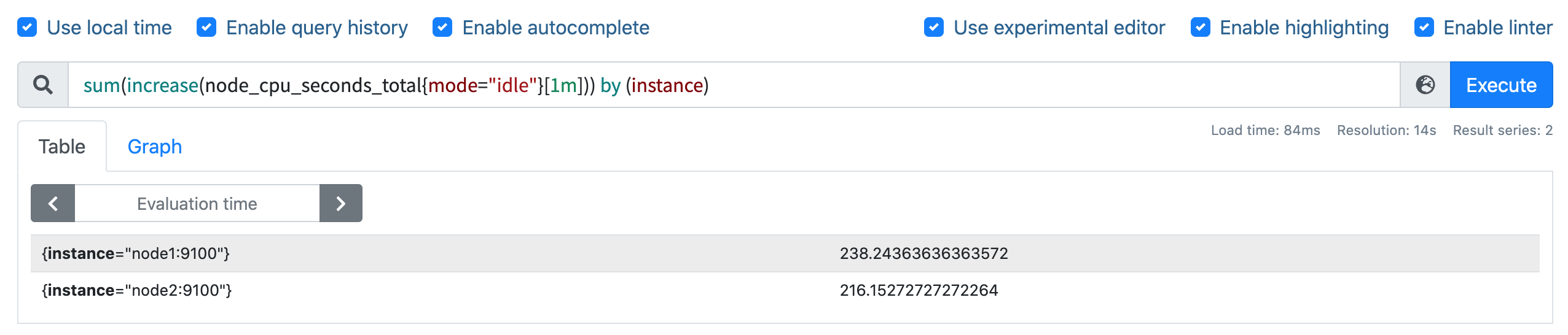
这样我们就分别拿到不同节点 1 分钟内的空闲 CPU 使用时间了,然后和总的 CPU (这个时候不需要过滤状态模式)时间进行比较即可,使用查询语句 sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance):
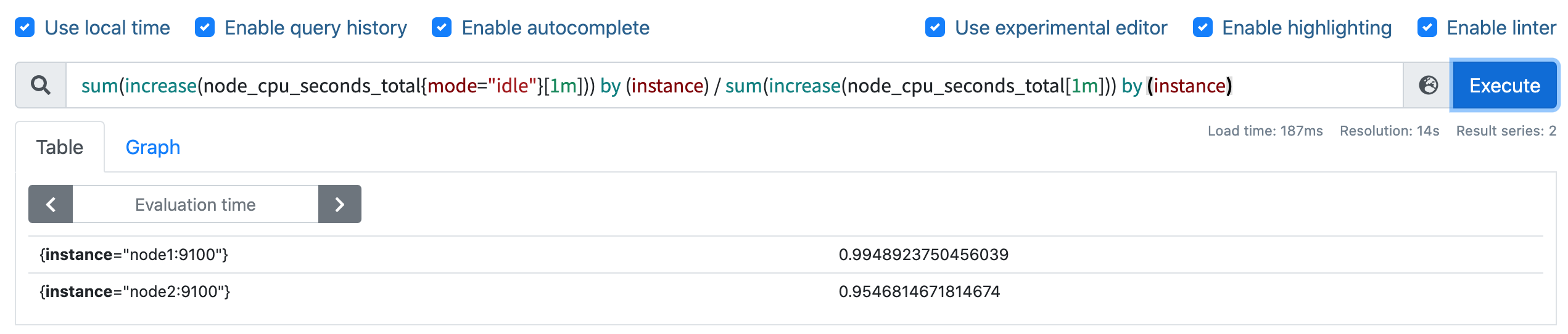
然后计算 CPU 使用率就非常简单了,使用 1 减去乘以 100 即可:(1 - sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) ) * 100。这就是能够想到的最直接的 CPU 使用率查询方式了,当然前面我们学习的 promql 语法中提到过更多的时候我们会去使用 rate 函数,而不是用 increase 函数进行计算,所以最终的 CPU 使用率的查询语句为:(1 - sum(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(rate(node_cpu_seconds_total[1m])) by (instance) ) * 100。
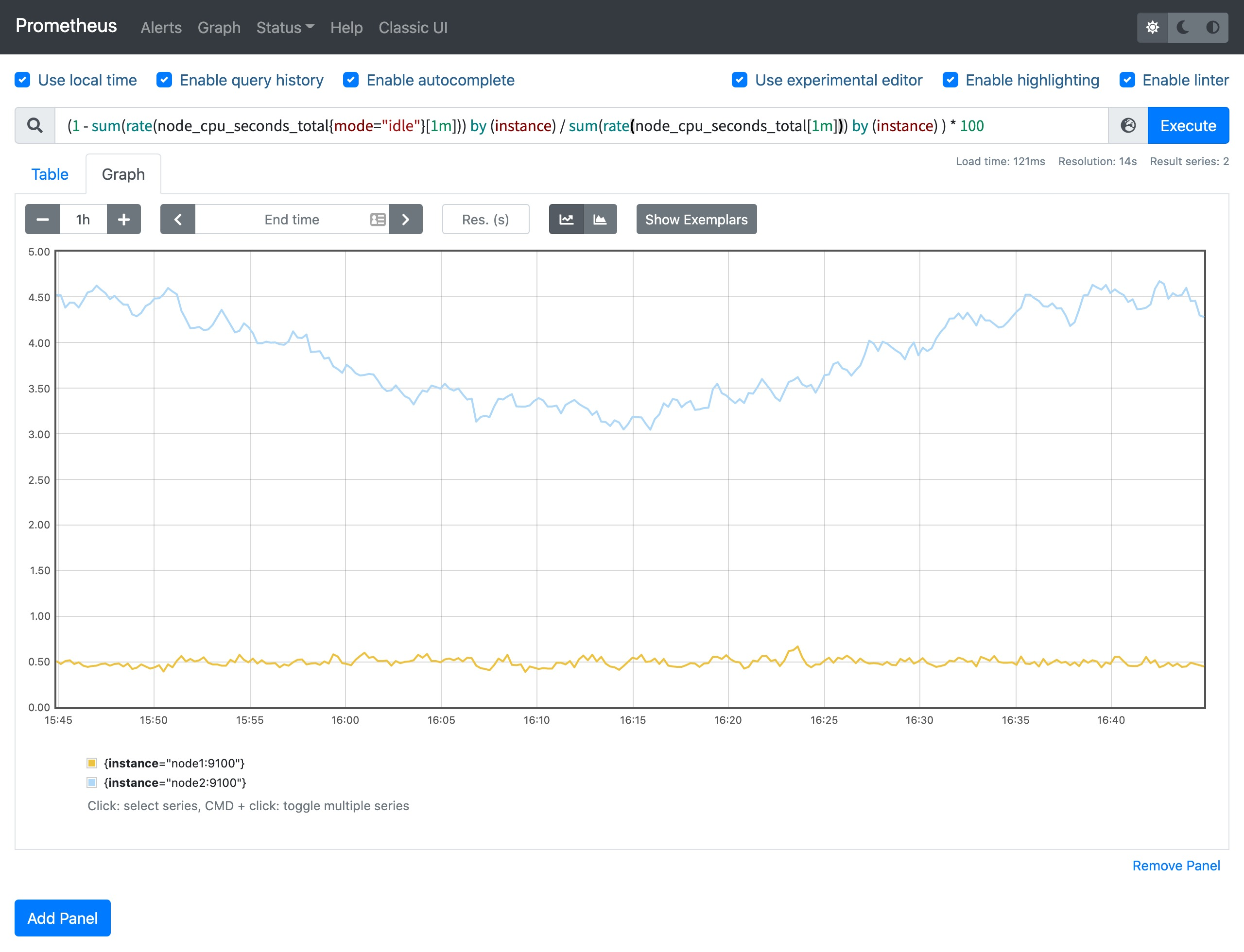
可以和 top 命令的结果进行对比(下图为 node2 节点),基本上是保持一致的,这就是监控节点 CPU 使用率的方式。

除了使用increase函数以外,PromQL中还直接内置了rate(v range-vector)函数,rate函数可以直接计算区间向量v在时间窗口内平均增长速率。因此,通过以下表达式可以得到与increase函数相同的结果:
rate(node_cpu[2m])需要注意的是使用rate或者increase函数去计算样本的平均增长速率,容易陷入“长尾问题”当中,其无法反应在时间窗口内样本数据的突发变化。 例如,对于主机而言在2分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致CPU占用100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
为了解决该问题,PromQL提供了另外一个灵敏度更高的函数irate(v range-vector)。irate同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。irate函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
irate(node_cpu[2m])irate函数相比于rate函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate的这种灵敏度反而容易造成干扰。因此在长期趋势分析或者告警中更推荐使用rate函数。