1)SGD
随机梯度下降(Stochastic gradient descent)是在梯度下降法(gradient descent)的基础上发展起来的,梯度下降法也叫最速下降法。SGD在通过负梯度和上一次的权重更新值Vt的线性组合来更新W,迭代公式如下:
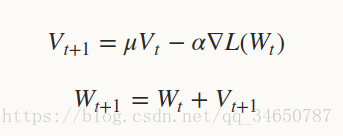
其中, 是负梯度的学习率(base_lr),是上一次梯度值的权重(momentum),用来加权之前梯度方向对现在梯度下降方向的影响。这两个参数需要通过tuning来得到最好的结果,一般是根据经验设定的。如果你不知道如何设定这些参数,可以参考相关的论文。
在深度学习中使用SGD,比较好的初始化参数的策略是把学习率设为0.01左右(base_lr: 0.01),在训练的过程中,如果loss开始出现稳定水平时,对学习率乘以一个常数因子(gamma),这样的过程重复多次。
对于momentum,一般取值在0.5–0.99之间。通常设为0.9,momentum可以让使用SGD的深度学习方法更加稳定以及快速。
关于更多的momentum,请参看Hinton的《A Practical Guide to Training Restricted Boltzmann Machines》。
实例:
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 1000
max_iter: 3500
momentum: 0.9lr_policy设置为step,则学习率的变化规则为 base_lr * gamma ^ (floor(iter / stepsize))
即前1000次迭代,学习率为0.01; 第1001-2000次迭代,学习率为0.001; 第2001-3000次迭代,学习率为0.00001,第3001-3500次迭代,学习率为0.00001
上面的设置只能作为一种指导,它们不能保证在任何情况下都能得到最佳的结果,有时候这种方法甚至不work。如果学习的时候出现diverge(比如,你一开始就发现非常大或者NaN或者inf的loss值或者输出),此时你需要降低base_lr的值(比如,0.001),然后重新训练,这样的过程重复几次直到你找到可以work的base_lr
补充:
如果把梯度下降法想象成一个小球从山坡到山谷的过程,那么前面几篇文章的小球是这样移动的:从A点开始,计算当前A点的坡度,沿着坡度最大的方向走一段路,停下到B。在B点再看一看周围坡度最大的地方,沿着这个坡度方向走一段路,再停下。确切的来说,这并不像一个球,更像是一个正在下山的盲人,每走一步都要停下来,用拐杖来来探探四周的路,再走一步停下来,周而复始,直到走到山谷。而一个真正的小球要比这聪明多了,从A点滚动到B点的时候,小球带有一定的初速度,在当前初速度下继续加速下降,小球会越滚越快,更快的奔向谷底。momentum 动量法就是模拟这一过程来加速神经网络的优化的。



2)RMSprop
例子:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
base_lr: 1.0
lr_policy: "fixed"
momentum: 0.95
weight_decay: 0.0005
display: 100
max_iter: 10000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_adadelta"
solver_mode: GPU
type: "RMSProp"
rms_decay: 0.98
3) Adadelta
sample:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
base_lr: 1.0
lr_policy: "fixed"
momentum: 0.95
weight_decay: 0.0005
display: 100
max_iter: 10000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_adadelta"
solver_mode: GPU
type: "AdaDelta"
delta: 1e-6

4)Adam
Adam是一个组合了动量法和RMSProp的优化算法

4)NAG
sample:
net: "examples/mnist/mnist_autoencoder.prototxt"
test_state: { stage: 'test-on-train' }
test_iter: 500
test_state: { stage: 'test-on-test' }
test_iter: 100
test_interval: 500
test_compute_loss: true
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 10000
display: 100
max_iter: 65000
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "examples/mnist/mnist_autoencoder_nesterov_train"
momentum: 0.95
# solver mode: CPU or GPU
solver_mode: GPU
type: "Nesterov"

下面是从作者的论文中抄的:
作者描述的NAG公式:
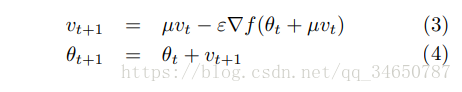
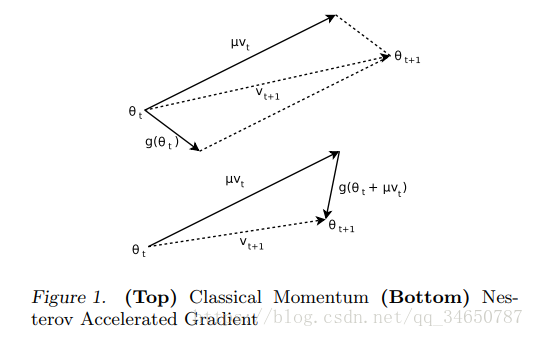
直观的解释如下:
参考:
http://www.cnblogs.com/denny402/p/5074212.html