摘要
我们提出一个新的框架,通过一个对抗过程来评估生成模型,我们同时训练两个模型:一个生成模型G——用于捕获数据分布,一个判别模型——用于评估一个例子是训练数据而不是生成数据的可能性。G的训练过程是最大化D做出错误决定的可能性。该框架类似于一种最大最小化的两人游戏。在任意G和D的空间中,存在唯一解,G恢复训练数据分布,D恒等于1/2。在这里,G和D都由多层感知机定义,整个网络通过梯度下降训练。在样本的训练或生成过程中,不需要任何马尔可夫链或展开的近似推理网络。通过对生成的样本进行定性和定量评估,实验验证了该框架的潜力。
1. 简介
深度学习是用于发掘丰富且多层次的模型,这些模型表示在人工智能应用中遇到的多种数据的概率分布,比如自然图片,演讲的音频波形和自然语言语料库中的符号。所以,在深度学习上的大部分显著的成功围绕着判别模型,这些模型通常将一个高维的、有丰富感知的输入映射到一个类别标签。这些成功的模型主要基于反向传播和dropout算法,以及使用具有表现很好的梯度的分段线性单元。深度生成模型影响不大,由于在极大似然估计和相关策略中的许多棘手的概率计算上的近似困难,以及难以在生成上下文中利用分段线性单元的优点。我们提出一个新的生成模型估计程序,其回避了这些问题。
在提出的对抗网络结构中,生成模型与一个对手竞争:一个判别模型学习判断一个样本是来自模型分布还是来自于数据分布。这个生成模型可被认为类似于一组伪造者,试图在不被发现的情况下制造假币并使用,判别器类似于警察,试图去检测伪造的货币。这个游戏的竞争促使两队改进他们的方法,直到仿冒品无法从真品中辨别出来。
该框架可以生成针对多种模型的特定训练算法和优化算法。在本文中,我们探讨一特别的例子——生成模型通过将随意的噪声送入多层感知机中生成样本,判别模型依然是MLP。我们将这个特别的例子视作对抗网络。在这个例子中,我们仅用反向传播和dropout算法训练两个模型,且从生成模型中只用前向传播生成样本。不需要近似推理或马尔可夫链。
3. 对抗网络
当模型都是多层感知器时,对抗模型框架最容易应用。为了数据 x 上学习生成器的分布 pg,我们预定义一个输入噪声变量pz(z),用G(z;θg)表示数据空间的映射,其中G是一个由参数为 θg 的MLP表示的微分方程。同时定义一个双层感知机 D(x;θd) 用于输出一个标量。D(x) 表示 x 来自于数据而不是 pg 的可能性。我们训练D来最大化分配正确标签给训练样本和生成样本的可能性,同时训练G来最小化 log(1-D(G(z))):换句话说,D和G用 V(G,D) 来玩最大最小化的游戏,
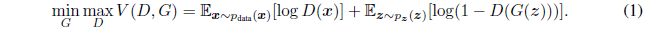
在下一节,我们展示了对抗网络的理论分析,重点展示了训练准则——当G和D由足够的容量时。即在非参数限制时,允许恢复数据生成分布。 Figure 1 展示了不太正式的、更具教育性的解释。实际上,我们必须用迭代的数值方法实现该游戏。在训练的内部循环中对D进行优化在计算上是禁止的,并且在有限的数据集上会导致过度拟合。相反,我们交替对D进行k个步骤优化和对G进行一个步骤优化,这使得G变化足够慢,D就保持在其最优解附近。这种策略类似于SML/PCD中训练维持来自Markov chain的样本,以避免在马尔可夫链中损坏一部分作为学习的内部循环。该过程在 Algorithm 1 中正式给出。
实际上,Eq1. 可能没有提供足够的梯度让G很好地学习。在早期学习中,G的性能很差,D能轻易拒绝样本,因为它们与训练数据间的差别很明显。在这个例子中,log(1-D(G(z))) 饱和,所以我们不通过最小化 log(1-D(G(z))) 来训练G,而是最大化 log(D(G(z)) 。该目标方程使得G和D在动力学上具有相同的不动点,但在学习的早期提供了更强的梯度。

4. 理论结果
生成器G暗中将一个概率分布 pg 定义为当 z~pz 时得到的样本 G(z) 的分布。因此,当容量和训练时间充足时,,我们想让 Algorithm 1收敛为一个好的 pdata 的评估器。本节的结果是在非参数设置下得到的, 比如,我们通过研究概率密度函数空间的收敛性来表示一个具有无限容量的模型。
在4.1节中展示了这个极小极大博弈对于pg = pdata具有全局最优。在4.2节中展示 算法1 对 Eq 1 进行了优化,并得到了预期的结果。

4.1 pg = pdata的全局最优性
我们首先考虑任意给定的生成器G的最优判别器D。
命题1. G固定时,最优判别器D是
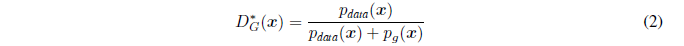
证明. 给定任一生成器G,判别器D的训练准则是最大化V(G,D)
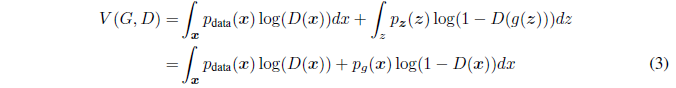
对任一 (a,b) ∈ R2{0,0} ,方程 y→a log(y) + b log(1-y) 在 [0,1] 的 a(a+b) 处达到最大值。判别器不需要被定义在Supp(pdata)∪Supp(pg)Supp(p_{data})\cup Supp(p_{g})Supp(pdata?)∪Supp(pg?)之外,得出结论。
注意D的训练目标可被解释为最大化估计条件概率 P(Y=y|x)的log-likelihood,其中Y表示 x 是来自 pdata(y=1)还是来自 pg(y=0)。Eq.1 的最大最小化博弈可被重新写为:
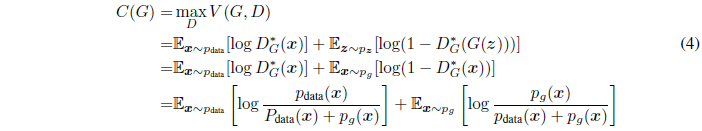
定理1. 当且仅当pg = pdata时,虚拟训练准则C(G)的全局最小化成立。此时,C(G) = -log4。
证明. 当pg = pdata,DG = 1/2。因此,将DG = 1/2代入Eq.4 ,发现C(G)=log12+log12=?log4C(G)=log\frac{1}{2}+log\frac{1}{2}=-log4C(G)=log21?+log21?=?log4。这是C(G)的最佳值,且仅当pg = pdata时得到,观察Ex?pdata[?log2]+Ex?pg[?log2]=?log4E_{x\sim p_{data}}[-log2]+E_{x\sim p_{g}}[-log2]=-log4Ex?pdata??[?log2]+Ex?pg??[?log2]=?log4
且从C(G)=V(DG,G)中减去该表达式,得:
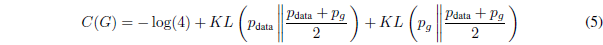
KL是KL散度。在前面的表达式中,我们认识到模型的分布和数据生成过程之间的Jensen-Shannon散度:
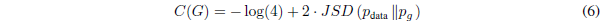
由于两分布之间的JS散度总是非负的,而且仅在两分布相等时为0,我们已经证明了C=-log4 是C(G)的全局最小值,唯一的解是pg = pdata,即,生成模型完美地复制了数据生成过程。
4.2 算法1的收敛
命题2. 如果G和D由足够的容量,允许判别器达到给定G时的最优值,并对pg进行更新,以改进判据Ex?pdata[?logDG?(x)]+Ex?pg[log(1?DG?(x))]E_{x\sim p_{data}}[-logD^{*}_{G}(x)]+E_{x\sim p_{g}}[log(1-D^{*}_{G}(x))]Ex?pdata??[?logDG??(x)]+Ex?pg??[log(1?DG??(x))],然后pg收敛到pdata。
证明. 将V(G,D) = U(pg,D)视作在上述准则中的pg的函数。U(pg,D)在pg中是凸状的。凸函数最小上界的次导数包括函数在达到最大值时的导数。换句话说,如果f(x)=supα?Afα(x)f(x)=sup_{\alpha \epsilon A}f_{\alpha }(x)f(x)=supα?A?fα?(x),且对每个 α ,fα(x)f_{\alpha }(x)fα?(x)是关于x的凸函数,如果β=argsupα?Afα(x)\beta =arg sup_{\alpha \epsilon A}f_{\alpha }(x)β=argsupα?A?fα?(x),则?fβ(x)??f\partial f_{\beta }(x) \epsilon \partial f?fβ?(x)??f。这等价于在D最优且给定相应的G时,计算pg的梯度下降更新。如定理1所证,supDU(pg,D)sup_{D}U(p_{g},D)supD?U(pg?,D) 是关于 pg 的凸函数,且有唯一的全局最优解。
实际上,对抗网络通过函数G(z;θg)表示 pg 分布的有限簇,并且我们优化θg而不是pg本身。使用一个多层感知机来定义G,在参数空间引入了多个临界点。然而,尽管缺乏理论证明,但在实际中多层感知机的优良性能表明了这是一个合理的模型。