БрКХАДееЖдгІЕФФкШнЃЌ1-1ДњБэЕквЛДѓВПЗжгіЕНЕФЕквЛЬтЃЌRДњБэReviewЃЌCДњБэдЫааЕФДњТыЃЈCodeЃЉЁЃ
1-1.

НтЃКD
ЪЙгУгХЛЏЫуЗЈРДгХЛЏЃЌашвЊЬсЙЉДњМлКЏЪ§JКЭЖдгІЕФЦЋЕМЪ§ЁЃ
1-2.
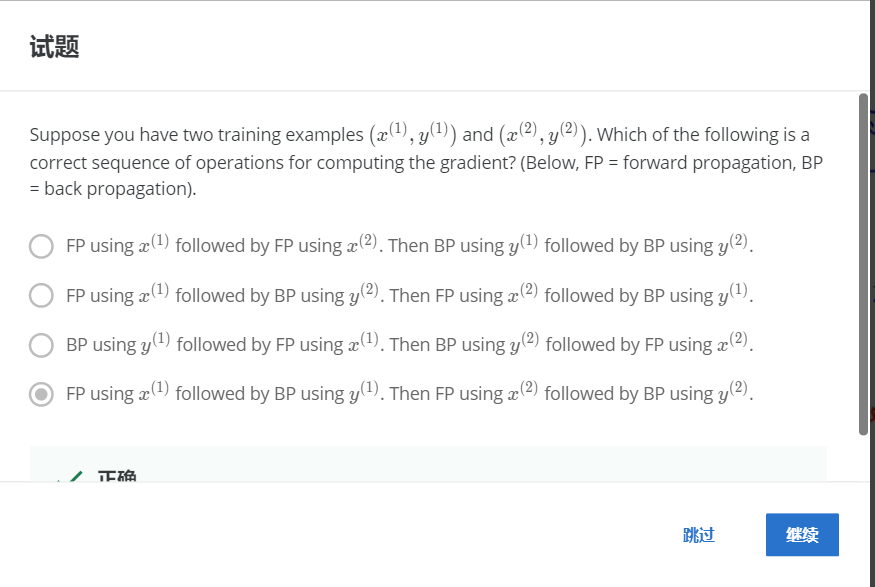
НтЃКD
FPЪЙгУa(1)ЃЌШЛКѓBPЪЙгУy(1)ЁЃFPЪЙгУa(2)ЃЌШЛКѓBPЪЙгУy(2)ЁЃ
1-3.
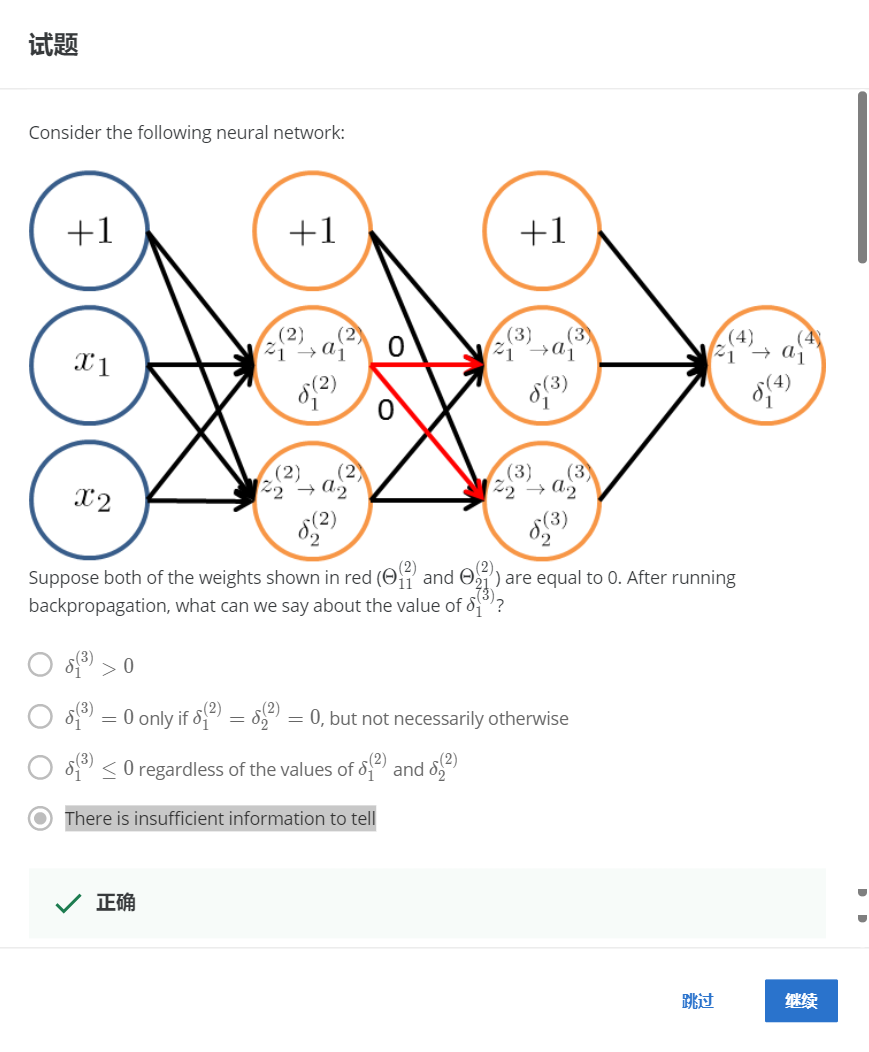
НтЃКD
ШчЙћЫљгаЕФШЈжиЖМЮЊ0ЃЌФЧУДЗДЯђДЋВЅЕФНсЙћгЩІФ12ОіЖЈЃЌЫљвдШБЩйБивЊЕФаХЯЂЁЃ
2-1.
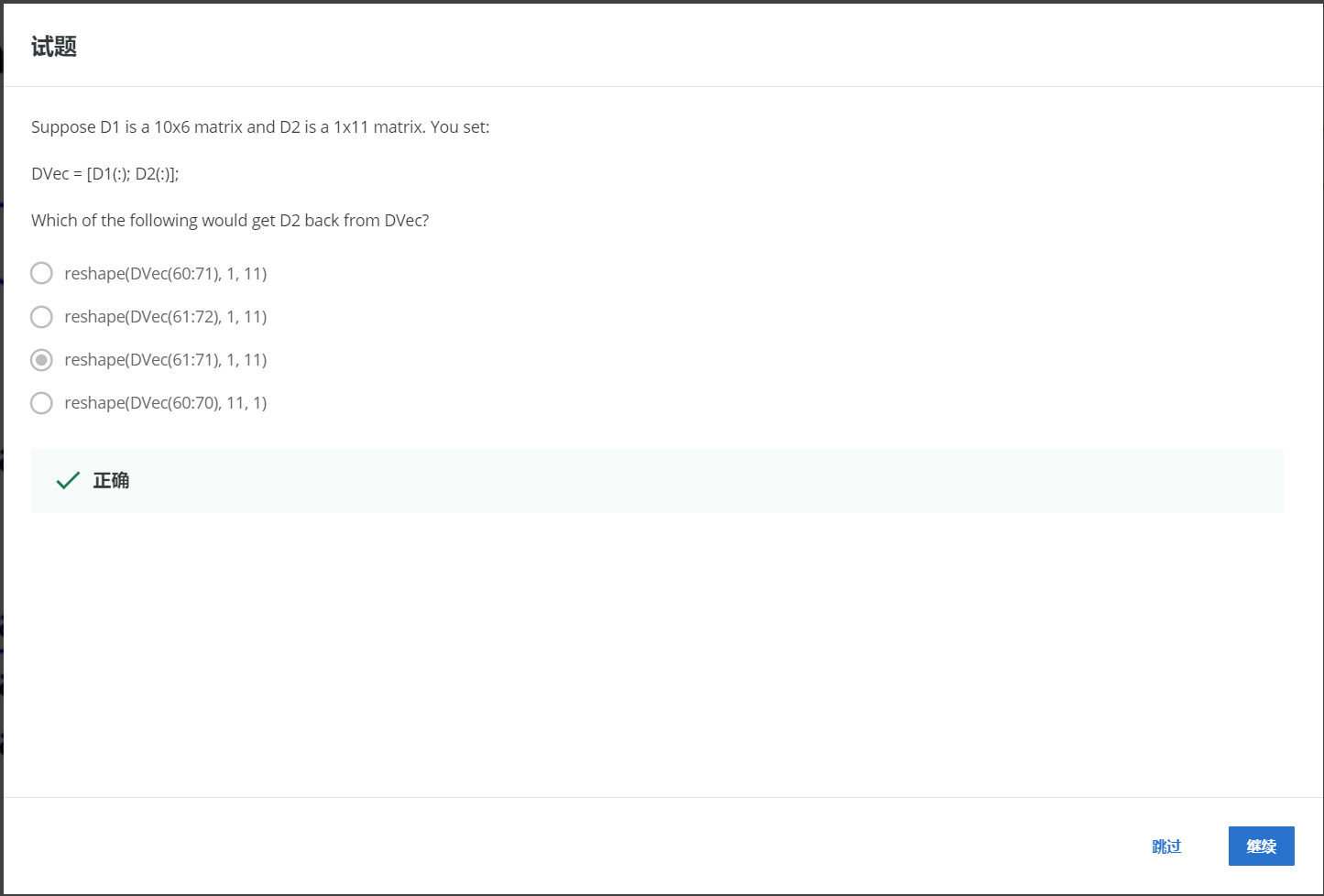
НтЃКC
Дг61ЕН71ЃЌзЊЛЏЮЊ1*11ЕФОиеѓЁЃ
2-2.
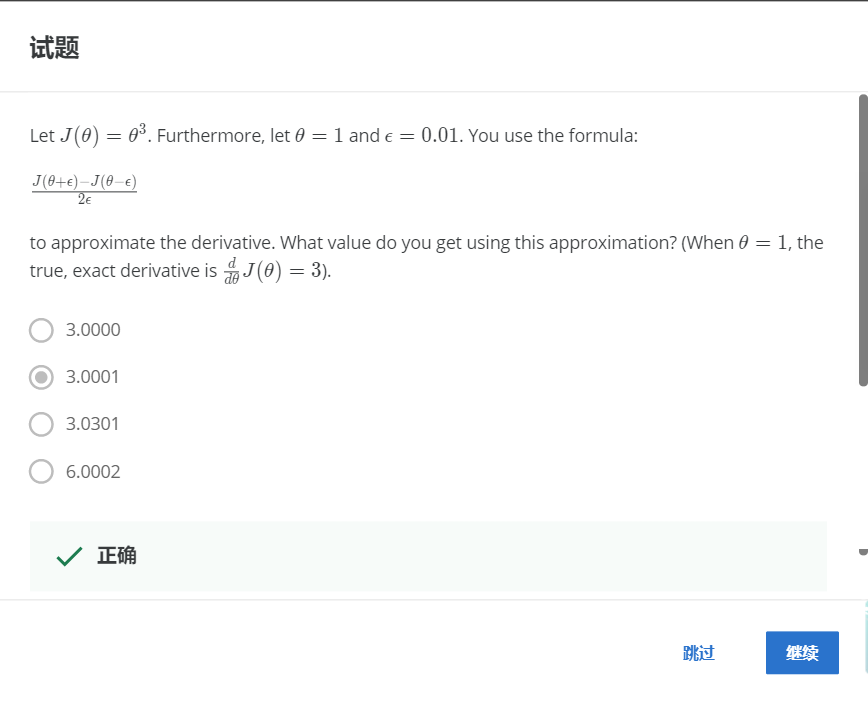
НтЃКB
ЪЙгУЙЋЪНДјШыМЦЫуПЩЕУЮЊ3.0001.
2-3.
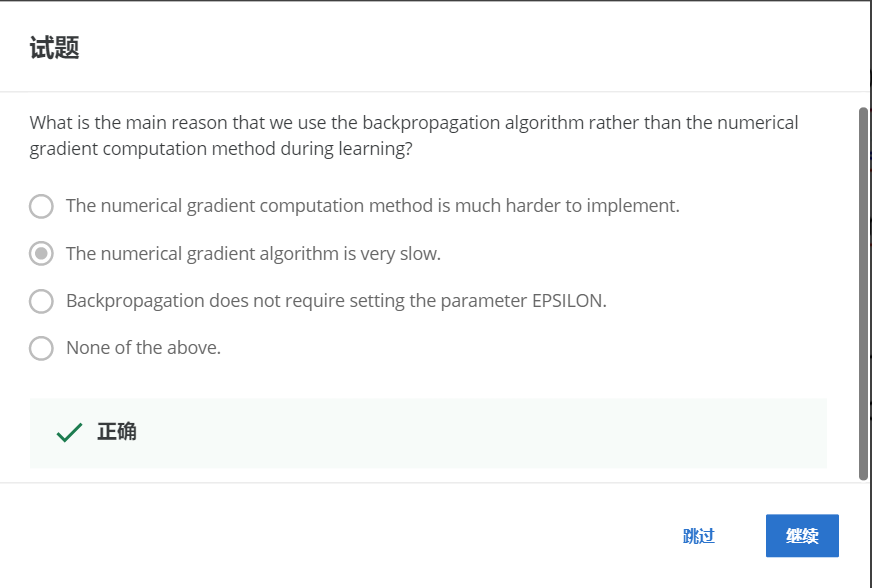
НтЃКB
Ъ§жЕЬнЖШЫуЗЈЗЧГЃЛКТ§ЁЃ
2-4.
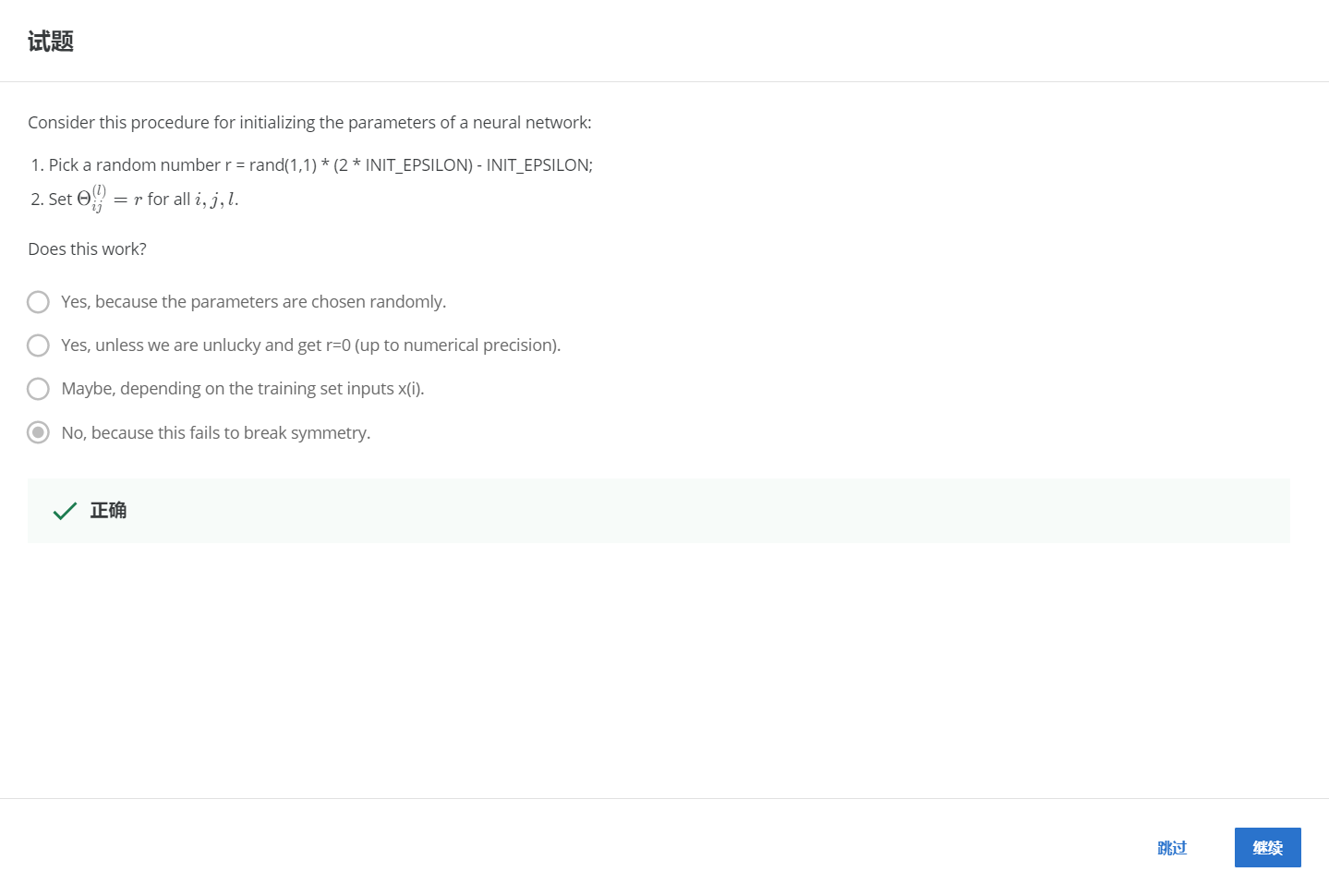
НтЃКD
ВЛЃЌвђЮЊетВЛФмДђЦЦЖдГЦадЁЃ
2-5.
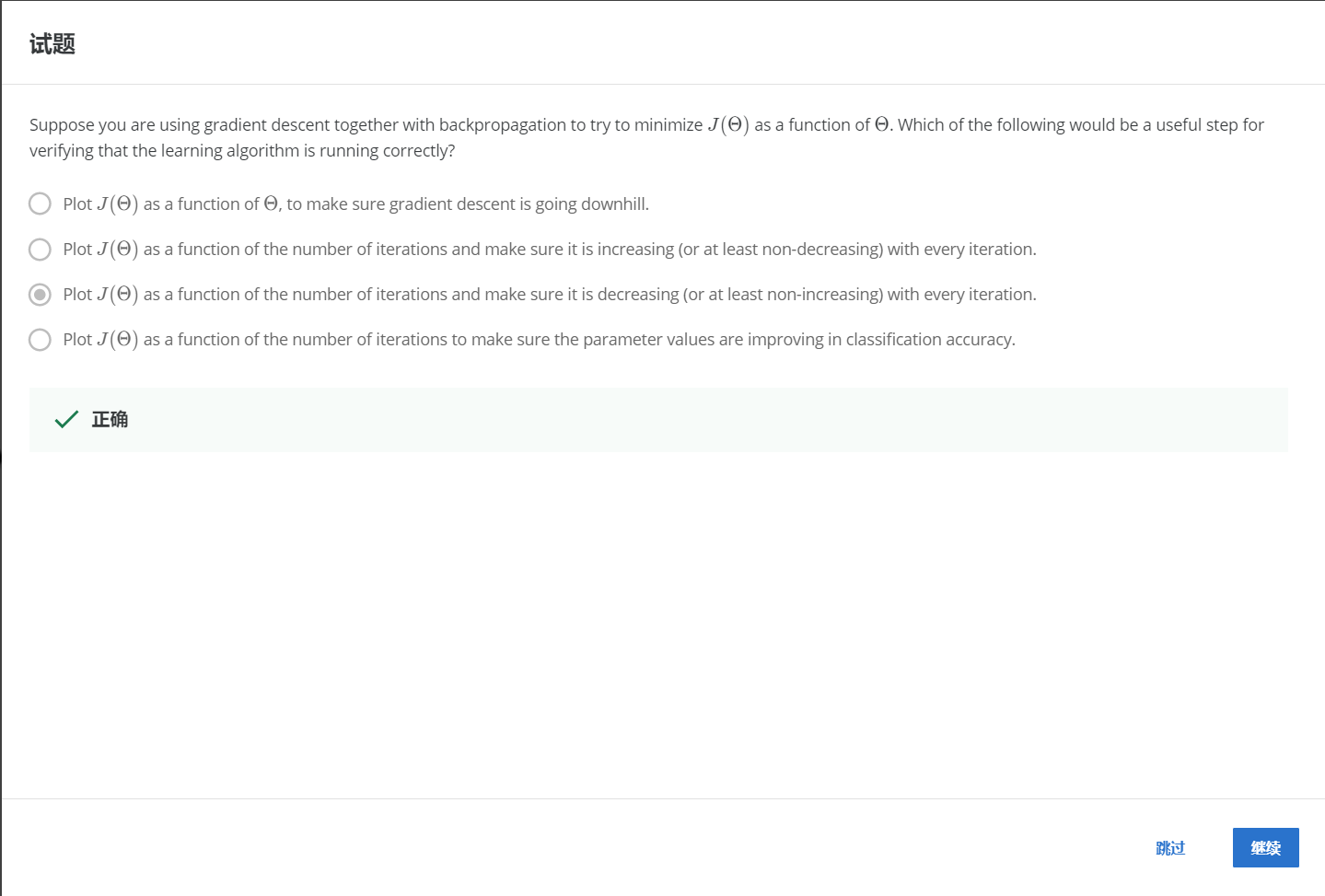
НтЃКC
ЛГіУПвЛДЮЕќДњЪБДњМлКЏЪ§JЕФЭМЯёЃЌРДШЗБЃДњМлКЏЪ§JЕФжЕЪЧвЛжБдкЯТНЕЕФЁЃ
R
R1-1.
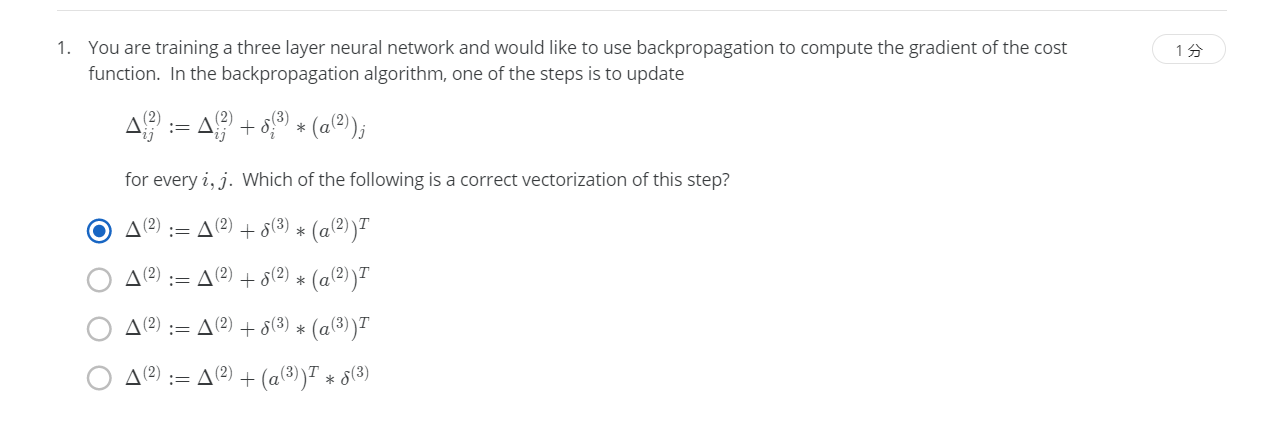
НтЃКA
This version is correct, as it takes the ЁАouter productЁБ of the two vectors ІФ*(3) and a*(2) which is a matrix such that the (i,j)-th entry is ІФi*(3)?(a(2))*j as desired.
МДЪзЯШгУе§ЯђДЋВЅЗНЗЈМЦЫуГіУПвЛВуЕФМЄЛюЕЅдЊ,РћгУбЕСЗМЏЕФНсЙћгыЩёОЭјТчдЄВтЕФНсЙћЧѓГізюКѓвЛВуЕФЮѓВюЃЌШЛКѓРћгУИУЮѓВюдЫгУЗДЯђДЋВЅЗЈМЦЫуГіжБжСЕквЛВуЕФЫљгаЮѓВюЁЃ
R1-2.
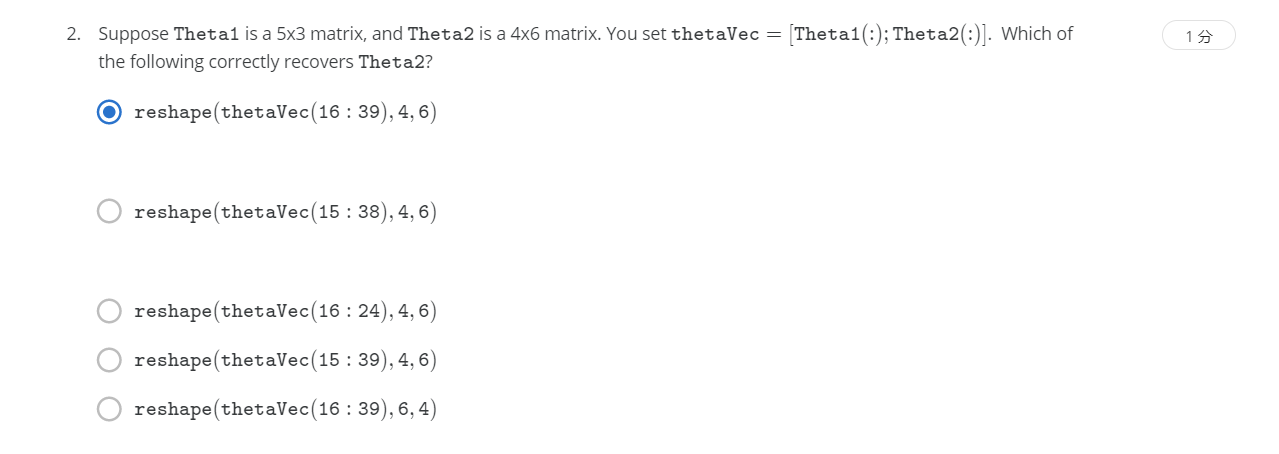
НтЃКA
This choice is correct, since Theta1 has 15 elements, so Theta2 begins at index 16 and ends at index 16 + 24 - 1 = 39.
Дг16ЕН39ЃЌзЊЛЏЮЊ4*6ЕФОиеѓЁЃ
R1-3.

НтЃКB
We compute \frac{(3(1.01)^3 + 2) - (3(0.99)^3 + 2)}{2(0.01)} = 9.00032(0.01)(3(1.01)3+2)?(3(0.99)3+2)=9.0003.
ДјШыМЦЫуПЩЕУ9.0003.
R1-4.

НтЃКAB
Checking the gradient numerically is a debugging tool: it helps ensure a correct implementation, but it is too slow to use as a method for actually computing gradients.ДгЪ§зжЩЯМьВщЬнЖШЪЧвЛжжЕїЪдЙЄОп:ЫќгажњгкШЗБЃе§ШЗЕФЪЕЯжЃЌЕЋзїЮЊвЛжжЪЕМЪМЦЫуЬнЖШЕФЗНЗЈЬЋТ§СЫЁЃ
If the gradient computed by backpropagation is the same as one computed numerically with gradient checking, this is very strong evidence that you have a correct implementation of backpropagation.ШчЙћЭЈЙ§ЗДЯђДЋВЅМЦЫуЕФЬнЖШгыЭЈЙ§ЬнЖШМьВщЪ§жЕМЦЫуЕФЬнЖШЯрЭЌЃЌетЪЧЗДЯђДЋВЅЕФе§ШЗЪЕЯжЕФЗЧГЃгаСІЕФжЄОнЁЃ
AЃКЮЊСЫБЃжЄаЇТЪЃЌдкЪЙгУЗДЯђДЋВЅЫуЗЈЧАЙиБеЬнЖШМьбщЃЌе§ШЗЁЃ
BЃКЪЙгУЬнЖШМьбщПЩвдРДМьВщЗДЯђДЋВЅЪЧЗёе§ШЗЃЌе§ШЗЁЃ
CЃКЬнЖШМьбщЖдгкЬнЖШЯТНЕЫуЗЈРДЫЕЗЧГЃгагУЃЌДэЮѓЁЃ
DЃКЬнЖШМьбщЕФаЇТЪвЊЕЭгкЗДЯђДЋВЅЃЌДэЮѓЁЃ
R1-5.

НтЃКBC
AЃКМДБуЪЧЗНеѓЃЌзЊжУжЎКѓвВЛсВњЩњгАЯьЃЌДэЮѓЁЃ
BЃКSince gradient descent uses the gradient to take a step toward parameters with lower cost (ie, lower J(ІЈ)), the value of J(ІЈ) should be equal or less at each iteration if the gradient computation is correct and the learning rate is set properly.гЩгкgradient descentЪЙгУЬнЖШЯђГЩБОИќЕЭЕФВЮЪ§ТѕГівЛВН(МДИќЕЭЕФJ(ІЈ))ЃЌШчЙћЬнЖШМЦЫуе§ШЗЃЌбЇЯАТЪЩшжУе§ШЗЃЌдђУПДЮЕќДњЪБJ(ІЈ)ЕФжЕгІИУЕШгкЛђаЁгкЁЃ
CЃКIf the learning rate is too large, the cost function can diverge during gradient descent. Thus, you should select a smaller value of ІС.ШчЙћбЇЯАТЪЙ§ДѓЃЌЬнЖШЯТНЕЙ§ГЬжаДњМлКЏЪ§ЛсЗЂЩЂЁЃвђДЫЃЌФњгІИУбЁдёНЯаЁЕФІСжЕЁЃ
DЃКбЁдёДѓЕФІСжЕВЛвЛЖЈФмМгЫйЃЌПЩФмЛсЕМжТКЏЪ§ЗЂЩЂЃЌЮоЗЈевЕНзюгХНтЁЃ