Transformer最近很火,相应的kaggle中很多比赛最近开始大量使用Transformer及其变体。Transformer之所以奏效,attention机制起了很大的作用,这次我们聊一聊attention机制
参考:https://zhuanlan.zhihu.com/p/46250529
https://zhuanlan.zhihu.com/p/47470866
https://blog.csdn.net/fan_fan_feng/article/details/81666736
https://blog.csdn.net/weixin_43788143/article/details/107724225
Seq2seq中的attention
你可能很常听到Seq2seq这词,却不明白是什么意思。Seq2seq全名是Sequence-to-sequence,是近年当红的模型之一。Seq2seq被广泛应用在机器翻译、聊天机器人甚至是图像生成文字等情境。seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列, Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。
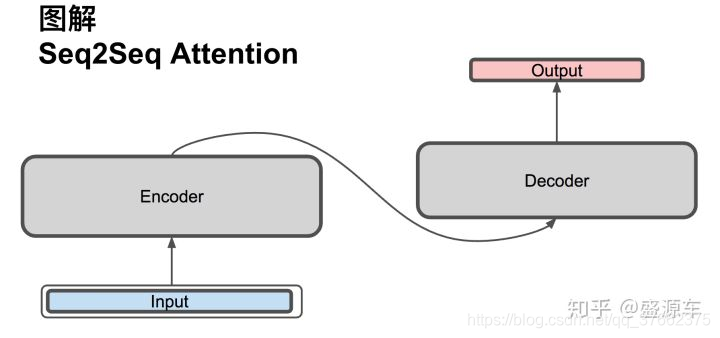
想象一下翻译任务,input是一段英文,output是一段中文。

详细图解seq-seq

左侧为Encoder+输入,右侧为Decoder+输出。中间为Attention
什么是attention
以上述seq2seq框架为基础,输入Source和输出Target内容是不一样的,比如对一件商品的评价和总结来说,Source是一个对一件商品好评或差评的句子,Target是对应的评价的总结,Attention发生在Target的元素Query和Source中的所有元素之间。
Attention主要用在两个句子或短语之间。通过对第一个句子单词的重要程度的不同进行加权,使其有侧重的表达再后面的句子上。例如:He is a student 翻译成中文 他是一个学生。如果不用attention 那么这四个单词的权重是一样的,会同等重要的反应再后面的中文上。但很明显翻译成中文后学生这个词明显要比其他几个更加的重要,使用attention进行不同程度的加权会使得我们的翻译更加的准确。
attention注重的是(输入与输出)两个句子之间的关系
Attention model虽然解决了输入句仅有一个context vector的缺点,但依旧存在不少问题。1.context vector计算的是输入句、目标句间的关联,却忽略了输入句中文字间的关联,和目标句中文字间的关联性,2.不管是Seq2seq或是Attention model,其中使用的都是RNN,RNN的缺点就是无法平行化处理,导致模型训练的时间很长,有些论文尝试用CNN去解决这样的问题,像是Facebook提出的Convolutional Seq2seq learning,但CNN实际上是透过大量的layer去解决局部信息的问题,在2017年,Google提出了一种叫做”The transformer”的模型,透过self attention、multi-head的概念去解决上述缺点,完全舍弃了RNN、CNN的构架。
Transfoemer中的Self-attention
上面介绍了attention model是如何运作的,它缺点就是不能平行化,且忽略了输入句中文字间和目标句中文字间的关系。
让我们复习一下Seq2seq、Attention model,差别在于计算context vector的方式。(图源:见图上文字)
Self-attention是Google在 “Attention is all you need”论文中提出的”The transformer”模型中主要的概念之一,我们可以把”The transformer”想成是个黑盒子,将输入句输入这个黑盒子,就会产生目标句。
最特别的地方是,”The transformer”完全舍弃了RNN、CNN的架构。
详解Transformer
“The transformer”和Seq2seq模型皆包含两部分:Encoder和Decoder。比较特别的是,”The transformer”中的Encoder是由6个Encoder堆积而成(paper当中N=6),Deocder亦然,这和过去的attention model只使用一个encoder/decoder是不同的。
Query, Key, Value
我们重新复习attention model,attention model是从输入句<X1,X2,X3…Xm>产生h1,h2,h….hm的hidden state,透过attention score α 乘上input 的序列加权求和得到Context vector c_{i},有了context vector和hidden state vector,便可计算目标句<y1…yn>。换言之,就是将输入句作为input而目标句作为output。
如果用另一种说法重新诠释:
输入句中的每个文字是由一系列成对的 <地址Key, 元素Value>所构成,而目标中的每个文字是Query,那么就可以用Key, Value, Query去重新解释如何计算context vector,透过计算Query和各个Key的相似性,得到每个Key对应Value的权重系数,权重系数代表讯息的重要性,亦即attention score;Value则是对应的讯息,再对Value进行加权求和,得到最终的Attention/context vector。
这概念非常创新,特别是从attention model到”The transformer”间,鲜少有论文解释这种想法是如何连结的,间接导致”attention is all you need”这篇论文难以入门,有兴趣可以参考key、value的起源论文 Key-Value Memory Networks for Directly Reading Documents。
在NLP的领域中,Key, Value通常就是指向同一个文字隐向量(word embedding vector)。
有了Key, Value, Query的概念,我们可以将attention model中的Decoder公式重新改写。1. score e_{ij}= Similarity(Query, Key_{i}),上一篇有提到3种计算权重的方式,而我们选择用内积。2. 有了Similarity(Query, Key_{i}),便可以透过softmax算出Softmax(sim_{i})=a_{i},接著就可以透过attention score a_{i}乘上Value_{i}的序列和加总所得 = Attention(Query, Source),也就是context/attention vector。
Scaled Dot-Product Attention
如果仔细观察,其实“The transformer”计算 attention score的方法和attention model如出一辙,但”The transformer”还要除上分母=根号d_{k},目的是避免内积过大时,softmax產出的结果非0即1。

什么是self-attention
Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的Attention。
The animal did not corss the river because it was too tired.
The animal did not corss the river because it was too narrow.
在这样的二句话中,只有最后的一个形容词不同但表示的意义却相差很大,在这两句中it代指的词语是不相同的,那怎样才能让机器识别it到底代表的是什么呢 这就要用到self-attention机制了。self-attention的作用是在本句子之间,它让句子中的每个单词除了关注它本身以为也会分配出不同的权重来关注其他单词。例如第一个句子animal除了要花费0.8的注意力在本身,还有可能话0.1的注意力在it上面,所以机器很容易就能理解到it代之的就是animal.
self-attention主要用在Tranformer和Bert中,这些过些时间也会整理出来
计算
attention 和 self-attention 的计算方法是一样的, 只不过是它们关注的对象不同而已。具体的计算方法大家可以看这个人写的一篇文章,用了一些动态的画面来演示计算的过程。