����������ѧϰ̨����������ڡ�����ѧϰ��ʯ���γ̺������ļ�Ҫ�ʼǣ�δ���γ̻�Ŀ�ֽڣ������ݴ���Դ����������ڵĿγ����ϣ�������زο������ѱ����
��Ȩ���У�CSDN���� ����֢���ߵ�����С��
����ģ�� - Linear models
- Logisticsregression ���ع�
��值�����÷ֶκ�����scoreӳ�䵽+1��-1�����ع�������Logistic������scoreӳ�䵽[0,1]�����Ҳ˵���ع���soft�Ķ�值����
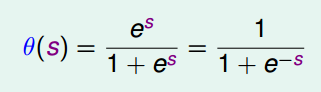
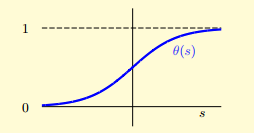
��Logistic������approximateĿ����ʺ�����
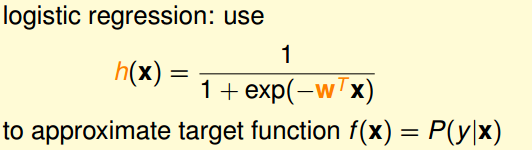
������������ð죬��Ϊ�����������У�ֻ�ܿ����˿͡��Ƿ�������Ľ��������û�С�������Ŀ����ԡ�������ݿ���ѧϰ������˼·����h��f�����������ݵĽǶȣ��۴��ڵ�����D����f�����ģ���ôh����������D�ĸ���Խ��Խ�ã������ͰѴ�����С���Ĺ���ת�����˸���������⣺
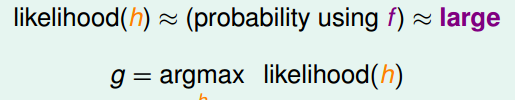
��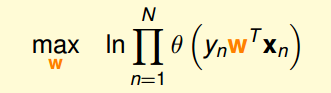
�ɴ���ת������С���⣬����Cross-entropy error��
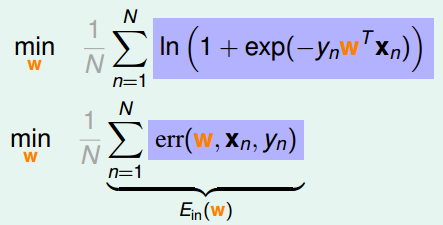
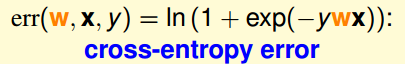
�����Ƶ����˴����������������������С值�������ˡ�����Ein(w)�����������������������֣�
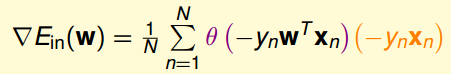
ֱ�ӽ���Ϊ���ʽ�Ӳ������ף�����������ݶ��½���
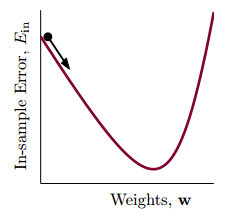
�ݶ��½������ͺñ�վ�ڸߴ���ȵ��ƶ������ĸ������߿��Ը��ӽ��ȵͳ���������һ����һ��һ���ӽ��ȵס���ʱ����������������v��������
��ѷ����Ǹõ��ݶȵķ�����
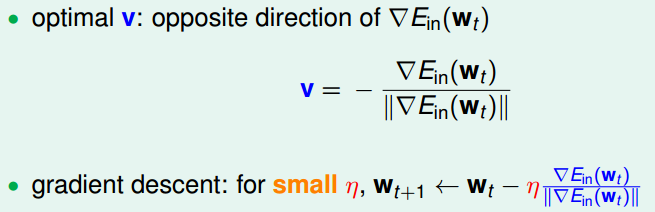
�������Ż�˼����Խ�ӽ��ȵ�ԽҪ��С��������һЩ���͡��õ㵽�ȵ��롱�����ȣ�

���ˣ����ع��㷨������¯��

PS������ݶ��½���SGD(stochasticgradient descent)
ԭ�ݶ��½�����wʱ�����㨌 E�ǽ����������㰴Ȩ�ش�С��������һ���ݶȣ������ܷ�����(��pocketЧ���൱)��SGD��˼·�����������������һ������������������ƽ��值����������ݶȡ�(=true gradient+��noise�� direction)��������ж��ݶ��Ƿ�Ϊ����������ʱ�㷨ֹͣ�ʹﲻ���������ͼ��㸴�Ӷȵij������ˣ�����ͨ���ø��´����㹻����ֹͣ���¡���������������̫��ʱ���ǵľ���值��0.1
��ʱ������ᵽ��SGD Logistic Regression �� ��soft�� PLA��ÿ�ֵĸ��¼��������һ������
PPS���ûع��㷨�����������(Regression for classification)

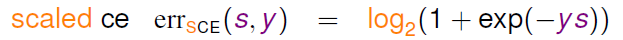


���Է����������㷨ʱ������NP-hard���⣬������Ҫ���Խ����ع��㷨��������Է������⣬��������ͼʽ�ӱ��Σ����ع��㷨err����ʽ�����Է���ͳһ����������ͼ����err�����߽��бȽϣ���֤��regression err���þͿ��Ա�֤0/1 errҲ�Ǻõģ�����������
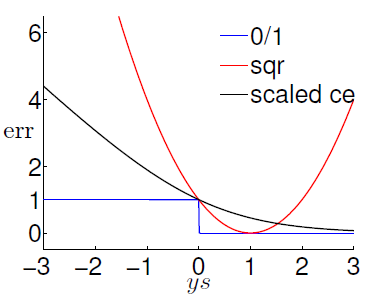
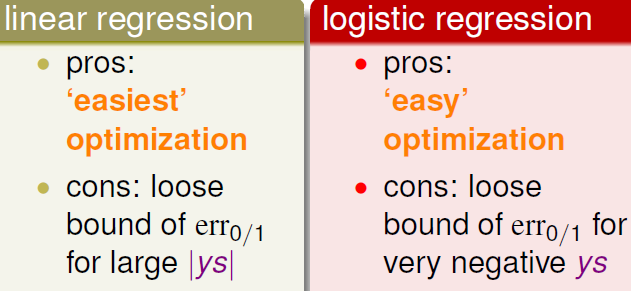
�ûع����������prosҲ�����������ij����㣬�Ƚ�����optimization��cons��ͼ��ֱ�ۿɵã�һЩ�����err���нϴ�ƫ��
Ӧ�ò������£�

ʵ��Ӧ���У�PLA�����������������Կɷֵģ���δ֪�Ƿ����Կɷֵĸ��������£�����Linear Regression����ʼ����������������PLA/Pocket/LogisticRegression��w0��ԭ����linearRegression��bound̫������Logistic Regression��pocket����ѡ