????? 最近有点忙,现在到今天才有时间继续我的博文!
?
1. 对于现流行的J2ME游戏开发而言,有美术、策划和程序。图片由美术完成,游戏控制脚本由策划撰写,实现是由程序负责编写。在三个分工中,会出现汉字部分就是程序(操作说明),还有脚本(人物对话和场景说明)。为此我们需要编写一个程序将游戏的代码部分和脚本过滤出来。在下面的代码中,我采用扩展名来标识:
?
// 筛选出指定扩展名的文件 public String[] filterFile(String directory, String[] extendFileName) { LinkedList<String> allFilePath = new LinkedList<String>(); LinkedList<String> allFilterFilePath = new LinkedList<String>(); searchFile(directory, allFilePath); for (int i = 0, size = allFilePath.size(); i < size; i++) { String path = allFilePath.get(i); if (getFileCodeFormate(path, extendFileName) != -1) { allFilterFilePath.add(path); } } String[] pathStr = new String[allFilterFilePath.size()]; allFilterFilePath.toArray(pathStr); return pathStr; } // 查找出全部的文件 public void searchFile(String directory, LinkedList<String> linkedList) { File file = new File(directory); if (file.isFile()) { linkedList.add(directory); } else { String[] subFiles = file.list(); for (int i = 0; i < subFiles.length; i++) { searchFile(directory + "/" + subFiles[i], linkedList); } } }?
?
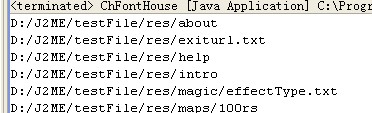
? 运行结果如图:
?
?
2.将文件中汉字提前出来,并作重复性校验 代码如下:
//读取全部文件的内容 public String getAllFileFont(String[] allFilePath, String[] extendFileName, String[] fileFormate) { String[] oneFileFont = new String[allFilePath.length]; int tem; String allfileFont = ""; for (int i = 0, len = oneFileFont.length; i < len; i++) { tem = getFileCodeFormate(allFilePath[i], extendFileName); oneFileFont[i] = getTextByFormate(allFilePath[i], fileFormate[tem]); oneFileFont[i] = getSoleWord(oneFileFont[i]); } for (int i = 0; i < allFilePath.length; i++) { allfileFont = oneFileFont[i] + allfileFont; } allfileFont = getSoleWord(allfileFont); return allfileFont; } // 由扩展名 得出对于的格式 public int getFileCodeFormate(String path, String[] extendFileName) { if (extendFileName == null || extendFileName.length == 0) { return -1; } else { for (int i = 0, len = extendFileName.length; i < len; i++) { if ("".equals(extendFileName[i].trim()) && path.indexOf(".") == -1) { return i; } else if (!"".equals(extendFileName[i].trim()) && path.endsWith(extendFileName[i])) { return i; } } return -1; } } //将对应文件的扩展名应相应的格式读取出来。 private String getTextByFormate(String name, String formate) { String strReturn = ""; int ic; ByteArrayOutputStream baos = new ByteArrayOutputStream(); DataOutputStream dos = new DataOutputStream(baos); FileInputStream fileInputStream; byte[] myData; byte[] buffer = new byte[1024]; try { fileInputStream = new FileInputStream(new File(name)); if (fileInputStream != null) { while ((ic = fileInputStream.read(buffer)) > 0) { dos.write(buffer, 0, ic); } myData = baos.toByteArray(); // // ANSI: 无格式定义; // // Unicode: 前两个字节为FFFE; // // Unicode big endian: 前两字节为FEFF; // // UTF-8: 前两字节为EFBB; // if ((myData[0] ^ (byte) 0xFE) == 0 // && (myData[1] ^ (byte) 0xFF) == 0) { // formate = "Unicode"; // } else if ((myData[0] ^ (byte) 0xFF) == 0 // && (myData[1] ^ (byte) 0xFE) == 0) { // formate = " Unicode big endian"; // } else if ((myData[0] ^ (byte) 0xEF) == 0 // && (myData[1] ^ (byte) 0xBB) == 0) { // formate = "UTF-8"; // } else { // formate = "GBK"; // } strReturn = new String(myData, formate); fileInputStream.close(); } dos.close(); baos.close(); } catch (Exception e) { System.out.println("getTextByUTF Error:" + e.toString()); } finally { myData = null; buffer = null; fileInputStream = null; dos = null; baos = null; } System.gc(); return strReturn; } //进行不重复性校验 private String getSoleWord(String str) { HashSet<String> ts = new HashSet(); for (int i = 0; i < str.length(); i++) { String subStr = str.substring(i, i + 1); ts.add(subStr); } Iterator<String> entry = ts.iterator(); StringBuffer sb = new StringBuffer(); for (; entry.hasNext();) { sb.append((String) entry.next()); } String ret = sb.toString(); return ret; }??
?
?
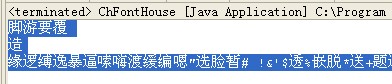
运行结果如图:
?
?3.此时我得到的只是汉字的机内码,现在我们将其排序一下,其作用以后再分析??
? ? //按机内码对字符串进行排序 private String sortAsCodeSequence(String str) { int len = str.length(); int codeSequence[] = new int[len]; for (int i = 0; i < len; i++) { codeSequence[i] = str.charAt(i); } Arrays.sort(codeSequence); StringBuffer sb = new StringBuffer(); for (int i = 0; i < len; i++) { sb.append((char) (codeSequence[i])); } return sb.toString(); }
?
?
?
?
?
????