本文大部分转载自:https://blog.csdn.net/huangfei711/article/details/78480078
引言
- 图像检索是根据特征匹配输出结果的,但是如何进行快速、准确的匹配是一个需要考虑的问题。如果数据库的数据量比较少,而且用于检索的特征维数也比较小,那么可以使用穷举法直接计算待检索特征和数据库中每个特征之间的距离,然后取出距离最短的几个数据作为结果返回。
- 但是如果数据量比较大,或者特征维数比较高,那么采用这种朴素的方法就行不通了,因为需要花费大量的时间用于计算。针对这个问题,一个常用的解决方法是采用聚类缩小搜索范围。
- 图像聚类是指按照特征相似性对图像进行聚合,是一种无监督的学习过程,其主要目的是将相似的特征向量分配到同一类簇,并用类簇中心代表该类簇的主要信息。
- 而在检索时首先和所有的类簇中心进行比对,并选择距离最小的中心,然后和该中心所对应的类簇中的所有数据–进行比较。通过这种方式可以大大缩小搜索范围,提高检索速度。
- 在聚类算法中,最经典的是K-means算法
聚类与分类的区别
- 分类:类别是已知的,通过对已知分类的数据进行训练和学习,找到这些不同类的特征,再对未分类的数据进行分类。属于监督学习。
- 聚类:事先不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。属于无监督学习。
- 关于监督学习和无监督学习,这里给一个简单的介绍:是否有监督,就看输入数据是否有标签,输入数据有标签,则为有监督学习,否则为无监督学习。更详尽的解释会在后续博文更新,这里不细说。
开始讲解
-
聚类算法有很多种,K-Means 是聚类算法中的最常用的一种,算法最大的特点是简单,好理解,运算速度快,但是只能应用于连续型的数据,并且一定要在聚类前需要手工指定要分成几类。
-
K-Means 聚类算法的大致意思就是“物以类聚,人以群分”:
- 首先输入 k 的值,即我们指定希望通过聚类得到 k 个分组;
- 从数据集中随机选取 k 个数据点作为初始大佬(质心);
- 对集合中每一个小弟,计算与每一个大佬的距离,离哪个大佬距离近,就跟定哪个大佬。
- 这时每一个大佬手下都聚集了一票小弟,这时候召开选举大会,每一群选出新的大佬(即通过算法选出新的质心)。
- 如果新大佬和老大佬之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),可以认为我们进行的聚类已经达到期望的结果,算法终止。
- 如果新大佬和老大佬距离变化很大,需要迭代3~5步骤。
- 说了这么多,估计还是有点糊涂,下面举个非常形象简单的例子:
有6个点,从图上看应该可以分成两堆,前三个点一堆,后三个点另一堆。现在我手工地把 k-means 计算过程演示一下,同时检验是不是和预期一致:
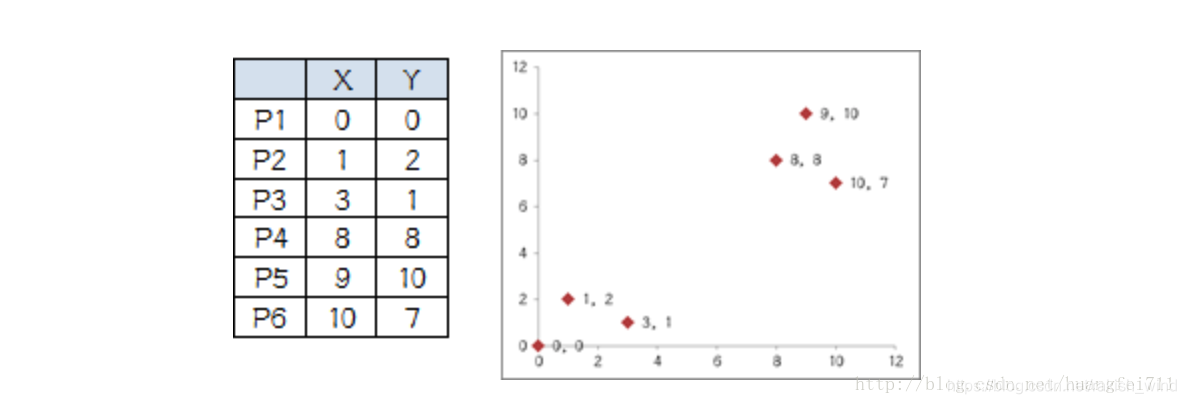
-
设定 k 值为2
-
选择初始大佬(就选 P1 和 P2)
-
计算小弟与大佬的距离:
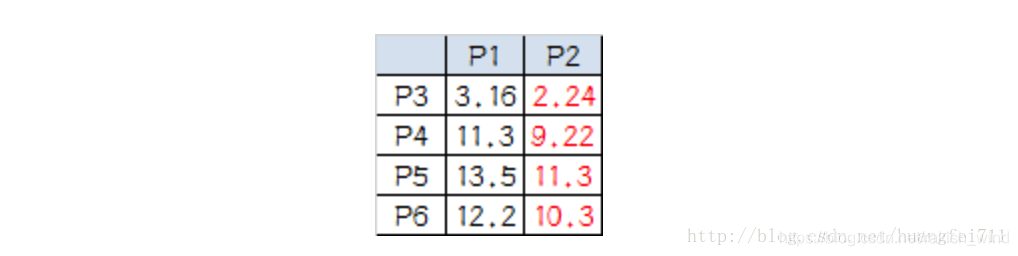
从上图可以看出,所有的小弟都离 P2 更近,所以次站队的结果是:
A 组:P1
B 组:P2、P3、P4、P5、P6
- 召开选举大会:
- A 组没什么可选的,大佬就是自己
- B 组有5个人,需要重新选大佬,这里要注意选大佬的方法是每个人 X 坐标的平均值和 Y 坐标的平均值组成的新的点,为新大佬,也就是说这个大佬是“虚拟的”。因此,B 组选出新大哥的坐标为:P 哥((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)。
- 综合两组,新大哥为 P1(0,0),P哥(6.2,5.6),而P2-P6重新成为小弟。
- 再次计算小弟到大佬的距离:
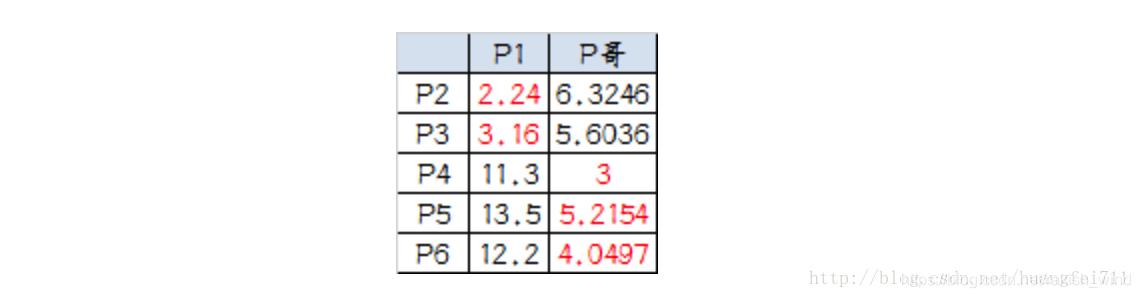
- 这时可以看到P2、P3离P1更近,P4、P5、P6离P哥更近,所以第二次站队的结果是:
A 组:P1、P2、P3
B 组:P4、P5、P6(虚拟大哥这时候消失)
-
第二届选举大会:
同样的方法选出新的虚拟大佬:P哥1(1.33,1),P哥2(9,8.33),P1-P6都成为小弟。 -
第三次计算小弟到大佬的距离:
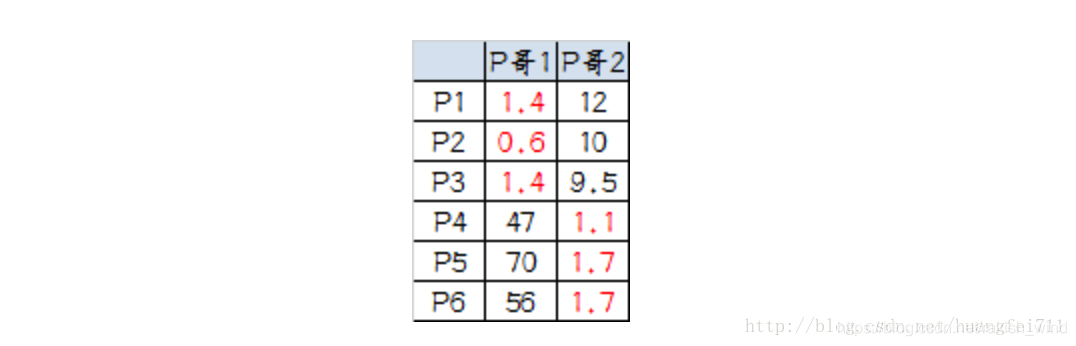
- 这时可以看到 P1、P2、P3 离 P哥1 更近,P4、P5、P6离 P哥2 更近,所以第二次站队的结果是:
A 组:P1、P2、P3
B 组:P4、P5、P6
- 我们可以发现,这次站队的结果和上次没有任何变化了,说明已经收敛,聚类结束,聚类结果和我们最开始设想的结果完全一致。