-
一. 倒排索引
-
二. 倒排索引原理
-
1 词语和文档的关系
-
2 倒排索引的数据结构
-
3 倒排索引的建立实例
-
4 倒排索引的更新策略
-
一. 倒排索引
- 倒排索引(Inverted Index) 也被称为“反向索引”或“反向文件”,是一种索引数据结构。倒排索引在“内容”(例如,单词、数字)和存放内容的“位置”(例如,数据库、文件、一组文件)之间建立映射,其目的在于快速全文检索和使用最小处理代价将新文件添加进数据库。通过倒排索引,可以快速地根据“内容”查找到包含它的文件。倒排索引是目前文件检索系统中使用最广泛的数据结构,被广泛用于搜索引擎中。倒排索引有两种不同的索引形式:一种是 “给定一个词语,查找出所有包含这个词语的文档”:另一种是“给定一个词语,不仅能查找出所有包含这个词语的文档,还能查找出这个词语在这篇文档中文档位置”。显然,后者可以提供更多的功能(例如,短语搜索),但是需要更多的时间和空间来创建索引。
- 一. 回到文首
二. 倒排索引原理
1. 词语和文档的关系
-
“文档”是以文本形式存在的存储对象,它是一个比较宽泛的概念:一个 Word 文件、一条短信都可以称为一个文档。在搜索引擎中,文档般指的是 “互联网网页”。将多个文档聚集在一起,就形成了“文档集合”,或称为“语料库”。
-
如果使用一个矩阵来描述词语和文档之间的关系,不难得出如下“词语-文档矩阵”。其中,每一列代表一个文档,每一行代表一个词语,每一个单元格代表“此文档中出现此词语的次数”。
| 出现次数 | 文档1 | 文档2 | 文档3 | 文档4 |
|---|---|---|---|---|
| 词语1 | 4 | 1 | ||
| 词语2 | 3 | 4 | ||
| 词语3 | 3 | 1 | ||
| 词语4 | 3 | 9 |
-
矩阵中的第一列说明 “在文档1中,词语1出现了4次、词语2和词语3均出现了3次,并且文档1中不再有其他词语出现"。同理,矩阵中的第行则说明“词语1在文档1中出现在4次,在文档4中出现1次,在其他文档中不出现"。其他行列同理。
-
人们关心的是 “篇文档中出现了哪些词语”, 但搜索引擎更关心“二个词语在哪些文档中出现”,并且需要快速地把这些文档全部呈现出来。搜索引擎的索引实际上就是上述“词语–文档矩阵”这一概念数据模型的一种具体实现形式,倒排索引便是其中一种比较有效的实现方式,通过倒排索引,可以根据单词快速获取包含这个词语的文档列表。除此之外,搜索引擎中经常用到的还有“签名文件”“后缀树”等。
- 一. 回到文首
2. 倒排索引的数据结构
-
倒排索引可以使用这样一个Map来实现:如下图所示,每一个词语都是Map中的一个键(Key),这个键对应的Value 是一个集合,里面保存着包含这个词语的文档的编号。存储形式为: Map< String key, Set< Struct< DocID> value > >。
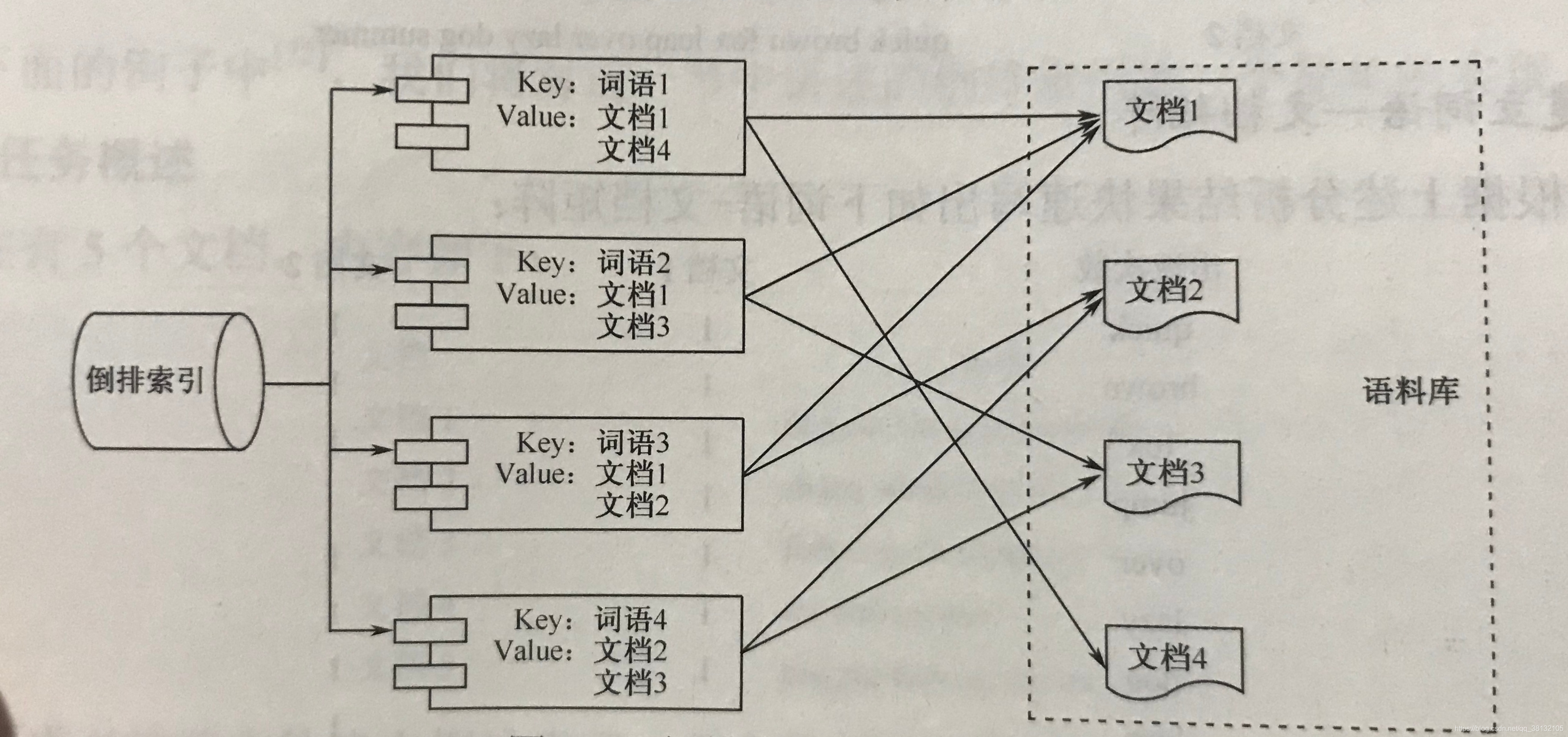
-
同理,如果要在倒排索引中加入更多信息,可以在Value 中增加记录项目,如下图所示。例如,加入“此词语在此文档中出现次数及位置”等信息。

- 一. 回到文首
3. 倒排索引的建立实例
- 假设现在有两篇文档,每篇文档的内容如下:
| 文档 | 内容 |
|---|---|
| 文档1 | The quick brown fox jumped over the lazy dog. |
| 文档2 | Quick brown foxes leap over lazy dogs in summer. |
-
(1)文章本分词
-
我们需要将整段的字 符串拆分成为一个一个的词语,即文本分词。英文句子由于单词间有空格分隔,比较容易处理,但中文不同,词语之间并没有空格分开。这时就需要借助专业分词工具将句子正确地切分成词语。例如,将“中国科学家屠呦呦获得诺贝尔医学和生理学奖”可以被拆分成“中国 科学家 屠呦呦 获得 诺贝尔 医学 和 生理学 奖”。
-
(2)去除无关词语
-
英文中存在大量的“a”“the”“too”之类的对搜索没有实际帮助的词语,中文中的“的”“是”“这”等字也通常无具体含义。这些词语都可以直接被去除掉。另外,所有标点符号也可以一并去除。
-
(3)词语归一化
-
我们通常希望在查询“fox"的时候将包含“Fox" “FOX"“foxes" 的文章一同查询出来,并且在查询"jump"的时候能将包含“jumped"“jumps"的文章也. 并查询出来。这时就要做统一大小写、 统一词语的格式等操作。
-
经过上述操作,上述两个文档内容会“变成”以下文档:
| 文档 | 内容 |
|---|---|
| 文档1 | quick brown fox jump over lazy dog |
| 文档2 | quick brown fox leap over lazy dog summer |
-
(4)建立词语文档矩阵
-
可以根据上述分析结果快速写出如下词语–文档矩阵:
| 出现次数 | 文档1 | 文档1 |
|---|---|---|
| quick | 1 | 1 |
| brown | 1 | 1 |
| fox | 1 | 1 |
| jump | 1 | |
| over | 1 | 1 |
| lazy | 1 | 1 |
| dog | 1 | 1 |
| leap | 1 | |
| summer | 1 |
-
(5)建立倒排索引
-
可以根据上述词语–文档矩阵建立如下倒排索引:
| Key(词语) | Value(在哪些文档中出现) |
|---|---|
| quick | {1,2} |
| brown | {1,2} |
| fox | {1,2} |
| jump | {1} |
| over | {1} |
| lazy | {1,2} |
| dog | {1,2} |
| leap | {2} |
| summer | {2} |
- 一. 回到文首
4. 倒排索引的更新策略
-
更新策略主要有4种:完全重建策略、再合并策略、原地更新策略及混合策略。
-
(1)完全重建策略:新文档并不立即被解析和加入索引中,而是先进行“文档暂存”。待文档暂存区中的文档达到一定数量后,将这些新文档和旧文档混在起, 对所有文档重建新索引,替换旧索引。这种方法代价极高,但主流商业搜索引擎有时会采用这种方法更新索引。
-
(2)再合并策略:新文档会立即被解析,但解析结果并不会立刻加入到旧索引中,而是进行“索引暂存”。索引暂存其实也是一个建立索引的过程。待索引暂存区达到一定数量后,暂存区中的索引和旧索引进行合并。
-
(3) 原地更新策略:新文档立刻被解析,解析结果立刻被加入旧索引中。这种方法有较好的时效性,在理论上是种比较优秀的策略。 为了加快索引速度, 索引内部-般都有一个“调优”的机制,例如,移动某些文件在磁盘上的位置,使索引过程中磁头移动距离尽可能小,磁盘等待时间尽量少。如果新文档立刻进入旧索引,那么索引内部就会不停地执行“调优”过程,有时反而会使性能下降。
-
(4)混合策略:其思想是混合地使用上述几种策略,取长补短,以达到最好的性能。
- 一. 回到文首