目录
- 摘要
- 1.引言
- 2.相关工作
-
- 自监督深度估计
- 遮挡问题
- 使用额外的模式
- 使用语义分割的深度
- 3.本文研究方法
-
- 3.1明确的深度-分割一致性
摘要
In this work we study the mutual benefits of two common computer vision tasks, self-supervised depth estimation and semantic segmentation from images.
在这项工作中,我们研究了两种常见的计算机视觉任务的相互好处,自我监督的深度估计和语义分割的图像。(自监督学习通过data的一部分,来predict其他部分,由自身来提供监督信号,从而实现自监督学习)
For example, to help unsupervised monocular depth estimation, constraints from semantic segmentation has been explored implicitly such as sharing and transforming features.
例如,为了帮助无监督的单目深度估计,语义分割的约束已经被隐含地探索,如共享和转换特征。
In contrast, we propose to explicitly measure the border consistency between seg-mentation and depth and minimize it in a greedy manner by iteratively supervising the network towards a locally optimal solution.
相反,我们建议明确测量分割和深度之间的边界一致性,并通过迭代监督网络向局部最优解决方案最小化它。
Partially this is motivated by our observation that semantic segmentation even trained with limited ground truth (200 images of KITTI) can offer more accurate border than that of any (monocular or stereo) image-based depth estimation. Through extensive experiments, our proposed approach advances the state of the art on unsupervised monocular depth estimation in the KITTI.
部分原因是由于我们的观察结果,即使使用有限的地面实况(200张KITTI图像)进行训练,语义分割也可以提供比任何(单眼或立体)基于图像的深度估计更准确的边界。 通过广泛的实验,我们提出的方法提高了KITTI中无监督单眼深度估计的最新技术水平。
1.引言
Estimating depth is a fundamental problem in computer vision with notable applications in self-driving [1] and virtual/augmented reality. To solve the challenge, a diverse set of sensors has been utilized ranging from monocular camera [12], multi-view cameras [4], and depth completion from LiDAR [18].
深度估计是计算机视觉的一个基本问题,在自动驾驶和虚拟/增强现实中有显著的应用。为了解决这一挑战,从单目摄像机、多视角摄像机,到激光雷达。
Although the monocular system is the least expensive, it is the most challenging due to scale ambiguity. The current highest performing monocular methods [9,14,22,25,39] are reliant on supervised training, thus consuming large amounts of labelled depth data.
虽然单目系统是最便宜的,它是最具挑战性的,由于规模模糊。目前表现最好的单目方法依赖监督训练,因此消耗了大量的标记深度数据
Recently,self-supervised methods with photometric supervision have made significant progress by leveraging unlabeled stereo images [10,12] or monocular videos [35,42,45] to approach comparable performance as the supervised methods.
近年来,带有光度监督的自我监督方法通过利用未标记的立体图像或单目视频来接近监督方法的性能,取得了显著的进展。
Yet, self-supervised depth inference techniques suffer from high ambiguity and sensitivity in low-texture regions,reflective surfaces, and the presence of occlusion, likely leading to a sub-optimal solution. To reduce these effects,many works seek to incorporate constraints from external modalities.
然而,自我监督的深度推论技术遭受重创来自低纹理区域的高度模糊性和敏感性,可能会导致次优解决方案。为了减少这些影响,许多研究者试图吸收来自外部的约束。
For example, prior works have explored leveraging diverse modalities such as optical flow [42], surface normal [40], and semantic segmentation [3,27,36,44].
例如,先前的工作已经探索了利用多种形式的方法,例如光流,表面法线和语义分割
Optical flow can be naturally linked to depth via ego-motion and object motion, while surface normal can be re-defined as direction of the depth gradient in 3D. Comparatively, semantic segmentation is unique in that, though highly relevant, it is difficult to form definite relationship with depth.
光流可以通过自我运动和物体运动自然地与深度联系起来,而表面法线可以被重新定义为三维深度梯度的方向。相对而言,语义分割的独特之处在于,它虽然相关性高,很难与深度形成确定的关系。
In response, prior works tend to model the relation of semantic segmentation and depth implicitly [3,27,36,44]. For instance, [3,36] show that jointly training a shared network with semantic segmentation and depth is helpful to both.[44] learns a transformation between semantic segmentation and depth feature spaces. Despite empirically positive results, such techniques lack clear and detailed explanation for their improvement. Moreover, prior work has yet to explore the relationship from one of the most obvious aspects— the shared borders between segmentation and depth.
因此,先前的研究倾向于隐含地对语义分割和深度之间的关系进行建模[3,27,36,44]。例如[3,36]表明,联合训练一个具有语义分割和深度的共享网络对两者都有帮助。[44]学习了语义分割和深度特征空间之间的转换。尽管实证结果是积极的,但这些技术缺乏对其改进的清晰、详细的解释。此外,之前的工作还没有从一个最明显的方面探索关系-分割和深度之间的共享边界。
Hence, we aim to explicitly constrain monocular self-supervised depth estimation to be more consistent and aligned to its segmentation counterpart.
因此,我们的目标是明确地约束单眼自监督深度估计,使其与分割对应对象更加一致和对齐。
We validate the intuition of segmentation being stronger than depth estimation for estimating object boundaries, even compared to depth from multi-view camera systems [41], thus demonstrating the importance of leveraging this strength (Tab. 3).
即使与多视图相机系统的深度相比,我们验证分割的直觉比深度估计更强,也能估计物体边界[41],因此证明了利用这种优势的重要性。
We use the distance between segmentation and depth’s edges as a measurement of their consistency. Since this measurement is not differentiable, we can not directly optimize it as a loss.
我们使用语义分割和深度边缘之间的距离作为他们一致性的度量。由于这种度量是不可微的,我们不能直接将其作为损失进行优化。
Rather, it is optimized as a “greedy search”, such that we iteratively construct a local optimum augmented disparity map under the proposed measurement and penalize its discrepancy with the original prediction. The construction of augmented depth map is done via a modified Beier–Neely morphing algorithm [34]. In this way, the estimated depth map gradually becomes more consistent with the segmentation edges within the scene, as demonstrated in Fig. 1.
相反,它被优化为一个“greedy search”,这样我们就可以在建议的测量值下迭代构造局部最优增强视差图,并补偿其与原始预测的差异。增强深度图的构建是通过改进的Beier-Neely变形算法完成的[34]。 以这种方式,估计的深度图逐渐变得与场景中的分割边缘更加一致。,如图1所示。
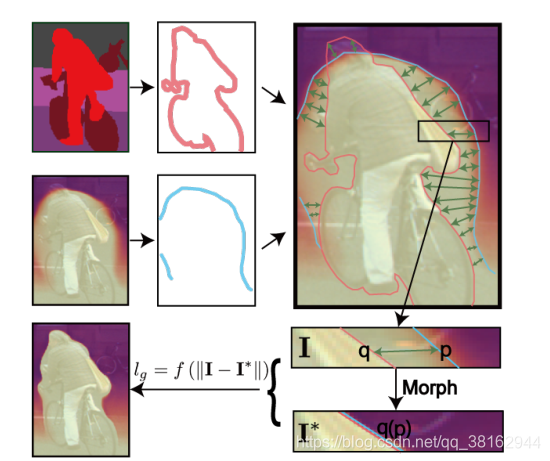
图1图示:我们将深度边界明确规范化为与分割边界一致,通过根据经过提炼的点对(pq)进行变形来创建一个“更好的”深度I?I^*I?,通过在每个训练步骤中惩罚它与原始预测I的差异,我们逐渐实现了一个更一致的边界。由于篇幅有限,这种变化发生在每一对提取对上,但只显示了一对
Since we use predicted semantics labels [46], noise is inevitably inherited. To combat this, we develop several techniques to stabilize training as well as improve performance.
由于我们使用预测语义标签[46],噪声不可避免地会被继承。为了解决这个问题,我们开发了几种技术来稳定训练和提高表现。
We also notice recent stereo-based self-supervised methods ubiquitously possess “bleeding artifacts”, which are fading borders around two sides of objects.
我们也注意到最近基于立体的自我监督方法都拥有“出血伪影”,即物体两侧的边界逐渐消失。
We trace its cause to occlusions in stereo cameras near object boundaries and resolve by integrating a novel stereo occlusion mask into the loss, further enabling quality edges and subsequently facilitating our morphing technique.
我们将其原因追溯到物体边界附近的立体摄像机中的遮挡,并通过将新颖的立体遮挡掩模集成到损失中来解决,进一步实现高质量边缘并随后促进我们的变形技术。
Our contributions can be summarized as follows:
我们的贡献可以总结如下
We explicitly define and utilize the border constraint between semantic segmentation and depth estimation, resulting in depth more consistent with segmentation.
我们明确地定义和利用了语义分割和深度估计之间的边界约束,使深度与分割更加一致。
We alleviate the bleeding artifacts in prior depth methods [3,12,13,29] via proposed stereo occlusion mask, furthering the depth quality near object boundaries.
我们通过提出的立体遮挡掩模来缓解先前深度方法中的“出血伪影”,进一步提高物体边界附近的深度质量。
We advance the state-of-the-art (SOTA) performance of the self-supervised monocular depth estimation task on the KITTI dataset, which for the first time matches SOTA supervised performance in the absolute relative metric.
我们在KITTI数据集上提高了自我监督单眼深度估计任务的最新状态(SOTA)性能,这首次使SOTA监督性能与绝对相对度量标准相匹配。
2.相关工作
自监督深度估计
Self-supervision has been a pivotal component in depth estimation [35,42,45].Typically, such methods require only a monocular image in inference but are trained with video sequences, stereo images, or both.
自我监督一直是深度估计中的关键组成部分。通常,此类方法仅需要推理的单目图像,但需要使用视频序列、立体图像或同时使用这两种方法进行训练
The key idea is to build pixel correspondences from a predicted depth map among images of different view angles then minimize a photometric reconstruction loss for all paired pixels.
关键思想是从不同角度的图像之间的预测深度图构建像素对应关系,然后将所有成对像素的光度重建损失降至最低。
Video-based methods [35,42,45] require both depth map estimation and ego-motion. While stereo system [10,12] requires a pair of images captured simultaneously by cameras with known relative placement, reformulating depth estimation into disparity estimation.
基于视频的方法需要深度图估计和自我运动。 虽然立体系统需要使用已知相对位置的相机同时捕获一对图像,将深度估计重新定义为视差估计。
We note the photometric loss is subject to two general issues:
我们注意到光度损失受两个一般性问题的影响:
(1) When occlusions present, via stereo cameras or dynamic scenes in video, an incorrect pixel correspondence can be made yielding sub-optimal performance.
当存在遮挡时,通过立体摄像机或视频中的动态场景,使像素对应不正确,从而产生次优的性能。
(2) There exists ambiguity in low-texture or color-saturated areas such as sky, road, tree leaves, and windows, thereby receiving a weak supervision signal.
天空、道路、树叶、窗户等低纹理或色彩饱和的区域存在模糊性,从而接收到微弱的监督信号
We aim to address(1)by proposed stereo occlusion masking, and (2) by leveraging additional explicit supervision from semantic segmentation.
我们的目标是解决(1)通过提出的立体遮挡掩模,和(2)通过利用来自语义分割的其他显式监督。
遮挡问题
Prior works in video-based depth estimation [2, 13, 20, 35] have begun to address the occlusion problem.
之前的基于视频的深度估计研究已经开始解决遮挡问题。
[13] suppresses occlusions by selecting pixels with a minimum photometric loss in consecutive frames.
[13]通过选择连续帧中光度损失最小的像素来抑制遮挡。
Other works [20, 35] leverage optical flow to account for object and scene movement. In comparison, occlusion in stereo pairs has not received comparable attention in SOTA methods.
其他作品[20,35]利用光流来考虑物体和场景的运动。相比之下,立体对的遮挡在SOTA方法中没有得到类似的关注。
Such occlusions often result in bleeding depth artifacts when (self-)supervised with photometric loss. [12]partially relieves the bleeding artifacts via a left-right consistency term. Comparatively, [29,39] incorporates a regularization onto the depth magnitude to suppress the artifacts.
当(自)监督光度损失时,此类遮挡通常会导致出血伪影。[12]通过左右一致性部分缓解出血伪影。相比之下,[29,39]在深度大小上采用正则化来抑制伪影。
In our work, we propose an efficient occlusion masking based only on a single estimated disparity map, which significantly improves estimation convergence and qualities around dynamic objects’ border (Sec. 3.2). Another positive side effect is improved edge maps, which facilitates our proposed semantic-depth edge consistency (Sec. 3.1).
在我们的工作中,我们提出了一种有效的遮挡掩蔽仅基于单个估计的视差图,这显著提高了估计收敛性和动态对象边界附近的质量(第3.2节)。另一个积极的副作用是改进了边缘图,这有助于我们提出的语义深度边缘一致性(第3.1节)。
使用额外的模式
To address weak supervision in low-texture regions, prior work has begun incorporating
modalities such as surface normal [40], semantic segmentation [3,27,31,36], optical flow [20,35] and stereo matching proxies [33,38]. For instance, [40] constrains the estimated depth to be more consistent with predicted surface normals.While [33,38] leverage proxy disparity labels produced by Semi-Global Matching (SGM) algorithms [16, 17], which serve as additional psuedo ground truth supervision. In our work, we provide a novel study focusing on constraints from the shared borders between segmentation and depth.
为了解决低纹理区域的弱监督问题,之前的工作已经开始融合各种形式,如表面法线[40]、语义分割[3,27,31,36]、光流[20,35]和立体匹配代理[33,38]。例如,[40]约束深度估计,使其与预测表面法线更一致。而[33,38]则利用半全局匹配(Semi-Global Matching, SGM)算法产生的代理差异标签[16,17],作为附加的伪ground truth监督。在我们的工作中,我们提供了一项新的研究,关注分割和深度之间的共享边界的约束。
使用语义分割的深度
The relationship between depth and semantic segmentation is fundamentally different from the aforementioned modalities. Specifically,semantic segmentation does not inherently hold a definite mathematical relationship with depth. In contrast, surface normal can be interpreted as normalized depth gradient in 3D space; disparity possesses an inverse linear relationship with depth; and optical flow can be decomposed into object movement, ego-motion, and depth estimation. Due to the vague relationship between semantic segmentation and depth, prior work primarily use it in an implicit manner.
深度与语义分割之间的关系与上述模式有本质的不同。具体来说,语义分割与深度并没有固有的数学关系。在三维空间中,表面法线可以解释为归一化深度梯度;视差与深度呈反线性关系;光流可以分解为物体运动、自我运动和深度估计。由于语义分割和深度之间的模糊关系,以前的研究主要以隐式的方式使用它。
We classify the uses of segmentation for depth estimation into three categories. Firstly, share weights between semantics and depth branches as in [3,36].
我们将分割用于深度估计的方法分为三类。首先,像[3,36]一样,在语义和深度分支之间共享权值。
Secondly, mix semantics and depth features as in [27, 36, 44]. For instance, [27,36] use a conditional random field to pass information between modalities.
其次,像[27,36,44]那样混合语义和深度特征。例如,[27,36]使用条件随机场在模式之间传递信息。
Thirdly, [21,31] opt to model the statistical relationship between segmentation and depth.[21] specifically models the uncertainty of segmentation and depth to re-weight themselves in the loss function.
第三,[21,31]选择建模分割与深度的统计关系。[21]专门对分割和深度的不确定性进行建模,以在损失函数中重新加权。
Interestingly, no prior work has leveraged the border consistency naturally existed between segmentation and depth. We emphasize that leveraging this observation has two difficulties.
有趣的是,以前的工作并没有利用分割和深度之间自然存在的边界一致性。我们强调,利用这种观测有两个困难。
First, segmentation and depth only share partial borders. Secondly, formulating a differentiable function to link binarized borders to continuous semantic and depth prediction remains a challenge.
首先,分割和深度只共享部分边界。其次,建立一个可微函数来连接二值化边界和连续语义和深度预测仍然是一个挑战。
Hence, designing novel approaches to address these challenges is our contribution to an explicit segmentation-depth constraint.
因此,设计新颖的方法来解决这些挑战是我们对显式分割深度约束的贡献。
3.本文研究方法
We observe recent self-supervised depth estimationmethods [38] preserve deteriorated object borders compared to semantic segmentation methods [46] (Tab. 3).It motivates us to explicitly use segmentation borders as a constraint in addition to the typical photometric loss.
我们观察到,与语义分割方法[46]相比,最近的自监督深度估计方法[38]保留了恶化的对象边界(表3)。除了典型的光度损失外,这促使我们明确使用分割边界作为约束
We propose an edge-edge consistence loss lcl_clc?(Sec. 3.1.1)between depth map and segmentation map.
在深度图和分割图之间,我们提出了边缘-边缘一致性(edge-edge consistence)损失lcl_clc?,具体在文章的3.1.1节。
However, as the lcl_clc? is not differentiable, we circumvent it by constructing an optimized depth map Id?I^*_dId?? and penalizing its difference with original prediction IdI_dId?(Sec. 3.3.1).
但是,由于lcl_clc?是不可微分的,我们绕过lcl_clc?,构造一个优化的深度图Id?I^*_dId??,惩罚Id?I^*_dId??与原始预测IdI_dId?的差异
This construction is accomplished via a novel morphing algorithm (Sec. 3.1.2).
这种构造是通过一种新的变形算法完成的
Additionally, we resolve bleeding artifacts (Sec. 3.2) for improved border quality and rectify batch normalization layer statistics via a finetuning strategy (Sec. 3.3.1)
此外,我们还解决了出血伪影(第3.2节)以改善边界质量,通过微调策略纠正BN层统计
As in Fig. 2, our method consumes stereo image pairs and precomputed semantic labels [46] in training, while only requiring a monocular RGB image at inference.
如图2所示,我们的方法在训练时使用立体图像对和预先计算的语义标签[46],而在推理时只需要一幅单目RGB图像。
It predicts a disparity map ImdI_mdIm?d and then converted to depth map IdI_dId? given baseline bbb and focal length fff under relationship IdI_dId?=f·b/ImdI_mdIm?d
它预测一个视差图 ImdI_mdIm?d,然后在给定基线b和焦距f的关系下IdI_dId?=f·b/ImdI_mdIm?d转换成深度图IdI_dId?
3.1明确的深度-分割一致性
To explicitly encourage estimated depth to agree with its segmentation counterpart on their edges, we propose two steps.
为了明确估计的深度与其分割对象在边缘上一致,我们提出了两个步骤。
We first extract matching edges from segmentation IsI_sIs? and corresponding depth map IdI_dId?(Sec. 3.1.1)
我们首先从分割中提取匹配的边缘IsI_sIs?和相应的深度图IdI_dId?
Using these pairs, we propose a continuous morphing function to warp all depth values in its inner-bounds (Sec. 3.1.2), such that depth edges are aligned to semantic edges while preserving the continuous integrity of the depth map.
使用这些对,我们提出了一个连续的变形函数来扭曲所有深度值在其内部范围内,这样深度边缘与语义边缘对齐,同时保持深度图的连续完整性。
3.1.1Edge-Edge Consistency边缘–边缘一致性