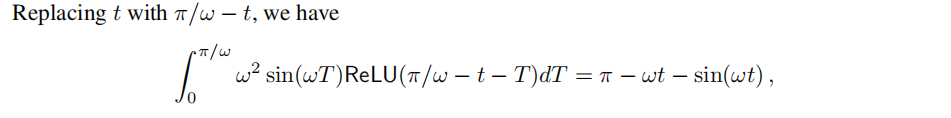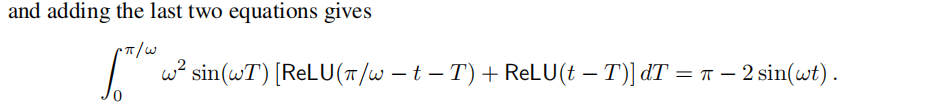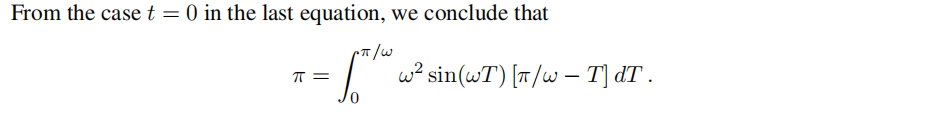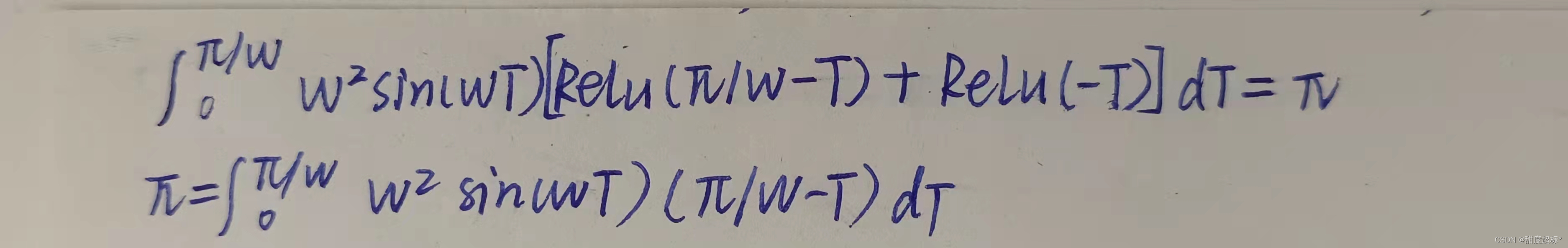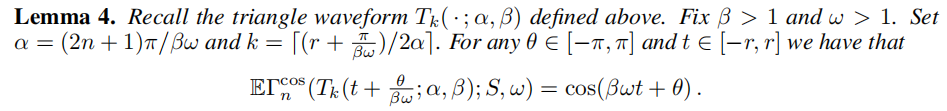آغخؤشؤ¶ء£؛Sharp Representation Theorems for ReLU Networkswith Precise Dependence on Depth
- صھزھ
- 1 Introduction
- 2 Notation, Problem Setup, and Fourier Norms
- 3 Using Depth to Improve Representation
- 4 Main Results
- 5 Technical Results
- 6 Proof of Theorem 1
- 7 Proof of Theorem 2
- A Supplementary Material
شخؤء´½س£؛https://arxiv.org/pdf/2006.04048.pdf
صھزھ
¶شسع±¾خؤ¶¨زهµؤز»ہà؛¯تGD£¬خزأاض¤أ÷ءث¾كسذD ReLU²مµؤةٌ¾حّآçشعئ½·½ثً؛ؤدآµؤاهخْخقخ¬±يت¾½ل¹û،£صâذ©½ل¹ûشعزشدآزâزهةد×¼ب·µط·´س³ءثةî¶بµؤ؛أ´¦£؛

صâ¹¹³ةءث¶شبخزâةî¶بD؛حةٌ¾شھتء؟Nµؤا°ہ،حّآçµؤ±يت¾ؤـء¦µؤد¸ء£¶ب±يص÷£¬¶ّدضسذµؤ±يت¾½ل¹ûزھأ´زھاَDثوN؟ىثظشِ³¤£¬زھأ´¼ظةèثù±يت¾µؤ؛¯ت·ا³£ئ½»¬،£شع؛َز»ضضاé؟ِدآ£¬؟ةزشسأµ¥¸ِ·ادكذش²م»ٌµأدàثئµؤثظآت،£خزأاµؤ½ل¹ûض¤تµءثئص±éµؤ¼ظة裬ةî²محّآç¸ü؛أµط±يت¾²»ج«ئ½»¬µؤ؛¯ت£¬تµ¼تةد£¬ض÷زھµؤ¼¼تُ´´ذآتا³ن·ضہûسأءثةî²محّآç؟ةزش²ْةْ¾كسذةظء؟¼¤»î؛¯تµؤ¸ك¶بصٌµ´؛¯تصâز»تآتµ،£
1 Introduction
ةî¶بةٌ¾حّآçتادض´ْ»ْئ÷ر§د°µؤض÷ء¦،£ز»¸ِضطزھµؤشزٍتاةî²محّآçµؤئص±é½üثئذشضت£¬ثüشتذيثüأازشبخز⾫¶ب±يت¾بخ؛خء¬ذّتµضµ؛¯ت،£¸÷ضض±يت¾¶¨ہي£¬½¨ء¢ءثةٌ¾حّآçµؤئص±é±ئ½üذشضت[2,3,4,5,6]،£شع؛¯تµؤصشٍذشجُ¼دآ£¬ز»جُ³¤¹¤×÷دك¸ّ³ِءثةٌ¾شھتء؟µؤ½üثئآت[7,8,9,10,11,12,13,14,15,16]،£µ½ؤ؟ا°خھض¹£¬µ¥¸ِ·ادكذش²مµؤاé؟ِزر¾؛ـ؛أµطہي½âءث£¬¶ّدàس¦µؤہيآغةî¶بحّآçتاب±·¦µؤ،£
¾رé±يأ÷£¬ةî²محّآçµؤ±يدضأ÷دشسإسعا³²محّآ磬´َء؟ہيآغآغخؤض¼شعہي½âصâز»µم،£ہب磬[17]±يأ÷£¬بأةî¶بثو×إرù±¾تء؟µؤشِ¼س¶ّشِ¼س£¬¶شسع·ا²خت»ط¹éبخخٌہ´ثµ£¬»ل¸ّ³ِ×î´َ×îذ،µؤ×îسإ´يخَآت،£[18]؟¼آاءثةî¶بحّآçضذµؤ·ض²مر§د°£¬ئنضذSGDرµء·²ْةْµؤ²مزہ´خ¹¹½¨¸ü¸´شسµؤجطص÷ہ´±يت¾¹¦ؤـ،£ثنب»ہي½â»ùسعت¾فرµء·µؤةٌ¾حّآçµؤ·؛»¯ذشؤـتاز»¸ِؤرج⣬»ùسعحّآçµؤ±ي´ïؤـء¦¾ِ¶¨ءثبخزâسإ»¯³جذٍدآµؤ»ù±¾صد°µؤآك¼£¬شعصâئھآغخؤضذ£¬خزأا¹ط×¢¸ü»ù±¾µؤ±يت¾ختجâ،£
ز»×é¹طسعةî¶ب·ضہëµؤرذ¾؟تشح¼ح¨¹¹¹شى؛¯تہ´ةîبëءث½âةî¶بµؤ؛أ´¦£¬صâذ©؛¯ت؟ةزش±»ز»¶¨ةî¶بµؤحّآçسذذ§µط±يت¾£¬µ«²»ؤـ±»½دا³µؤحّآç±يت¾£¬³·اثüأاµؤ؟ي¶ب·ا³£´َ [19, 20, 12, 21, 22, 23, 24, 25]،£ہب磬[23]±يأ÷¾¶دٍ؛¯تµؤ´وشع£¬ثü؟ةزش؛ـبفز×µطسأء½¸ِ·ادكذش²م±ئ½ü£¬µ«²»ؤـسأز»¸ِ·ادكذش²م±ئ½ü£¬[24]±يأ÷ءثصٌµ´؛¯تµؤ´وشعذش£¬ثü؟ةزش؛ـبفز×µطسأ¾كسذD3·ادكذش²مµؤحّآç±ئ½ü£¬µ«²»ؤـسأسةD·ادكذش²م×é³ةµؤ2D؟ي¶بحّآçہ´½üثئ،£[26, 27]ہûسأ¶¯ء¦دµح³µؤث¼دëہ©ص¹صâذ©½ل¹û£¬²¢»ٌµأةî¶ب؟ي¶بµؤب¨؛â،£شعسأ؛ح»حّآç±يت¾¸إآت·ض²¼µؤ²»ح¬ةèضأضذ£¬[28]دشت¾ءث½دا؟µؤDسëD+1·ضہë½ل¹û،£ثùسذصâذ©½ل¹û¶¼±يأ÷´وشعز»¸ِذèزھز»¶¨ةî¶بµؤ؛¯ت£¬µ«²¢أ»سذتشح¼؟ج»سة¸ّ¶¨ةî¶بµؤحّآç±ئ½üµؤز»ہà؛¯ت،£
¶شسعµ¥²م¾كسذN¸ِ·ادكذشµ¥شھµؤةٌ¾حّآ磬ح¨¹´َتذح²خت¶¨آةµأµ½µؤ¾µن½ل¹û²ْةْءث1/Nµؤئ½·½ثً؛ؤث¥¼ُآت[7,8]،£¼¸ئھآغخؤجل³ِءثشِ¼سةî¶بµؤ؛أ´¦[9,10,12,13]£¬ح¨¹تµدضج©ہص¼¶ت½üثئہ´±يأ÷ةî¶بReLU»ٍRePUةٌ¾حّآç؟ةزشتµدض±ب1/N¸ü؟ىµؤثظآت,µ±ثù±يت¾µؤ؛¯ت·ا³£ئ½»¬ازشتذيةî¶بثو×إثًت§ا÷سع0¶ّشِ³¤ت±،£ب»¶ّ£¬×î½üشع[16]ضذدشت¾£¬µ±صâضض¶îحâµؤئ½»¬تا¼ظةèµؤ£¬ز»¸ِµ¥ز»µؤ·ادكذش²م×مزش´ïµ½دàثئµؤخَ²îث¥¼ُآت،£زٍ´ث£¬صâذ©½ل¹û²¢أ»سذجهدض³ِةî¶بµؤ؛أ´¦،£
سëخزأا×îدà¹طµؤ¹¤×÷تا[14]£¬ثü؟¼آاشعsup·¶تدآ¸ّ¶¨ء¬ذّؤ£µؤ؛¯ت±يت¾،£µ±ةî¶بDس뼤»î؛¯ت×ـتN³ةدكذش¹طدµت±£¬خَ²îث¥¼ُآترد¸ٌسإسعD²»±نت±µؤخَ²îث¥¼ُآت،£صâ±يأ÷ةî¶بشعحّآç±ي´ïؤـء¦ضذتاسذہûµؤ£¬µ«تا£¬ثظآتتاء؟¸ظدà¹طµؤ£¬زٍ´ث£¬½ل¹ûش¶²»ؤـاهخْµطأèتِةî¶بµؤب·اذ؛أ´¦£¬صâز»µم½«±نµأ؛ـاه³،£
شع±¾خؤضذ£¬خزأا¶شةî¶بشعReLUحّآç±يت¾ؤـء¦ضذµؤ×÷سأ½ّذذءثد¸ء£¶ب±يص÷،£¸ّ¶¨ز»¸ِ¾كسذD¸ِReLU²م؛حتنبëخ¬تdµؤحّآ磬خزأا¶¨زهءثز»ہàزشئن¸µہïز¶±ن»»ث¥¼ُخھجطص÷µؤتµضµ؛¯تGD,ہàثئسع¾µن×÷ئ·ضذثù؟¼آاµؤہ࣬بç[7]،£ثو×إDµؤشِ¼س£¬¸µہïز¶±ن»»µؤخ²²؟±»شتذي±نµأ¸ü؟ي£¬´س¶ّ²¶»ٌ¸ü¹م·؛µؤ؛¯تہà.اë×¢ز⣬ضعثùضـضھ£¬؛¯تµؤ¸µہïز¶±ن»»µؤث¥¼ُسëثüµؤ¹â»¬ذشسذ¹ط(c.f.£¬[29])،£خزأاشعµع4½عضذثùتِµؤ½ل¹û±يأ÷£¬شعD²مضذ¾كسذN¸ِReLUµ¥شھµؤحّآç؟ةزشتµدضGDہà؛¯تµؤN½×ثظآت£¬¶ّ¾كسذD،¯<D¸ِReLU²مµؤحّآç±طذë¾كسذ½دآµؤN-D،¯/D½×ثظآت،£ثùسذصâذ©ثظآتشع³£تزٍثطدآ¶¼تا×îسإµؤ،£بçµع3½عثùتِ£¬خزأاح¨¹ہûسأةî²محّآçµؤ×é³ة½ل¹¹دµح³µط²ْةْا³²محّآçؤرزش²ْةْµؤ¸كصٌµ´؛¯تہ´ض¤أ÷صâذ©½ل¹û،£
×éض¯،£±¾خؤ×éض¯بçدآ،£شعµع2½عضذ£¬خزأا½éةـءث·û؛إ²¢¶¨زهءثختجâ،£شعµع3½عضذ£¬خزأا¸إتِءث½لآغ±³؛َµؤض÷زھث¼د룬ب»؛َشعµع4½عضذصت½³آتِ،£µع5،¢6؛ح7½عض¤أ÷ءثصâذ©½ل¹û،£
2 Notation, Problem Setup, and Fourier Norms
2·û؛إ،¢ختجâةèضأ؛ح¸µہïز¶·¶ت
 D:ReLU²مµؤتء؟
D:ReLU²مµؤتء؟
d:تنبëخ¬ت,d1=d,d1=ni-1(i ،ف\geq،ف 2)
ej:±ê×¼»ùدٍء؟

خزأادëضھµہشعةî¶بخھDµؤةٌ¾حّآçضذ£¬سذ¶àةظ¸ِReLUµ¥شھتا±طزھµؤ؛ح³ن·ضµؤ£¬ت¹ئنتن³ِfµؤئ½·½ثً؛ؤخھ:
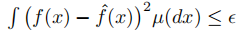

¶¨زهسٍRdح¨³£تازت½µؤ£¬µ«خھءثاهخْئً¼û£¬خزأاإ¼¶ûز²ذ´GK(Rd)»ٍGK( R)،£سةسع¸µہïز¶±ن»»µؤث¥¼ُسë؛¯تµؤ¹â»¬ذشسذ¹ط£¬؛¯ت؟ص¼نذٍءذ(GK)ثو×إKµؤشِ¼س¶ّشِ¼س¹â»¬ذش½د²îµؤ؛¯ت،£؛ـؤر×¼ب·µطأèتِصâہà؛¯ت£¬µ«خزأا×¢زâµ½£¬¶شسعBd?ض®حâµؤثùسذK×م¹»´َ(ح¨¹سë؛دتتµؤ°¼ح¹؛¯تدà³ث)£¬µ±ذق¸ؤµ½ث¥±نخھ0ت±£¬GKضذ°ü؛¬ءث¸÷ضض؛¯تہà،£صâذ©°üہ¨¶àدîت½،¢ب½ا¶àدîت½(¶شسعثùسذK ،ف\geq،ف 1)؛حبخزâةî¶بµؤبخ؛خReLUحّآç(µ±K ،ف\geq،ف 2ت±)،£

3 Using Depth to Improve Representation
شعدآز»½عضذ³آتِخزأاµؤ±يت¾¶¨ہيض®ا°£¬خزأادضشع¼ٍزھµط½âتح؛ثذؤث¼دë£؛
- شع[7]ض®؛َ£¬خزأات¹سأ¸µہïز¶·´±ن»»½«f(x)±يت¾خھؤ³¸ِثو»ْ±نء؟¦خµؤAcos(<¦خ,x>+ ¦ب(¦خ))µؤئعحû£¬ب»؛َت¹سأReLUµ¥شھتµدضcos(<¦خ,x>+ ¦ب(¦خ))،£
- خزأات¹سأز»¸ِہàثئسع[24]ضذµؤدë·¨ہ´تµدضز»¸ِ¾كسذ2k·هضµµؤب½اذخ²¨ذخTk£¬ت¹سأ~k1/D¸ِ ReLUµ¥شھشعةî¶بDµؤحّآçضذإإءذ،£
- ہûسأµحئµسàدزسëب½ا²¨ذخµؤ×é؛د£¬ح¨¹ReLUµ¥شھسذذ§±ئ½ücos(<¦خ,x>+ ¦ب(¦خ))ذخت½µؤ¸كئµسàدز،£
¼ظةèخزأادëزھت¹سأ´ّسذµ¥¸ِز²ط²مµؤReLUحّآç½üثئاّ¼ن[-1,1]ؤعtµؤ؛¯تf(t) = cos(¦طt)،£زٍخھاّ¼ن[-1,1]°ü؛¬؛¯تµؤ¦¸(¦ط)¸ِضـئع£¬سذذ§µط¸ْ×ظثüذèزھ¦¸(¦ط)¸ِ ReLUµ¥شھ،£تآتµض¤أ÷£¬بç¹ûخزأاشتذيء½¸ِ·ادكذش²م£¬صâضضزہہµذش؟ةزشµأµ½دشضّ¸ؤةئ،£The first layer is used

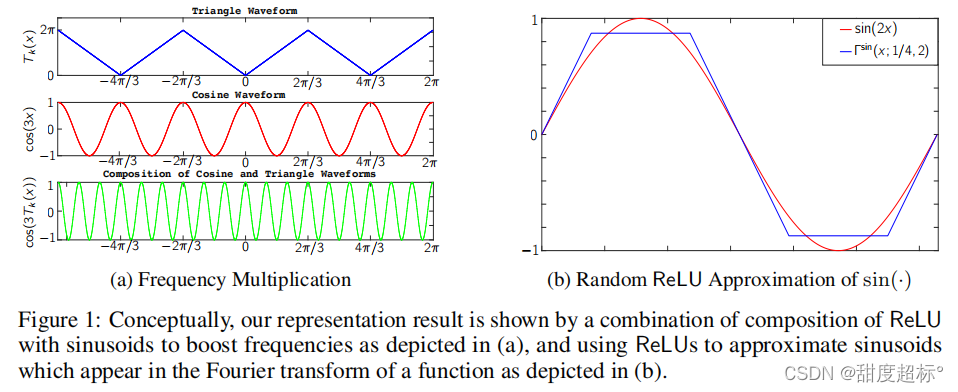
4 Main Results

½سدآہ´£¬خزأاشع¶¨ہي2ضذ¸ّ³ِءثز»¸ِئ¥إندآ½ç£¬ثüز²±يأ÷ءث¶شسعبخزâD£¬ةî¶بD؛حD + 1حّآçض®¼نµؤةî¶ب·ضہë،£
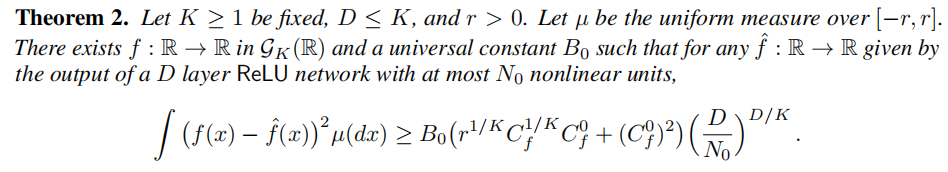

5 Technical Results
شعةîبëرذ¾؟¶¨ہي1؛ح¶¨ہي2µؤض¤أ÷ض®ا°£¬خزأاذèزھز»ذ©¼¼تُذشزہي،£



6 Proof of Theorem 1
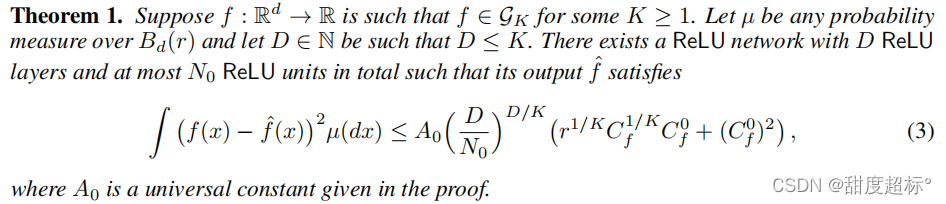



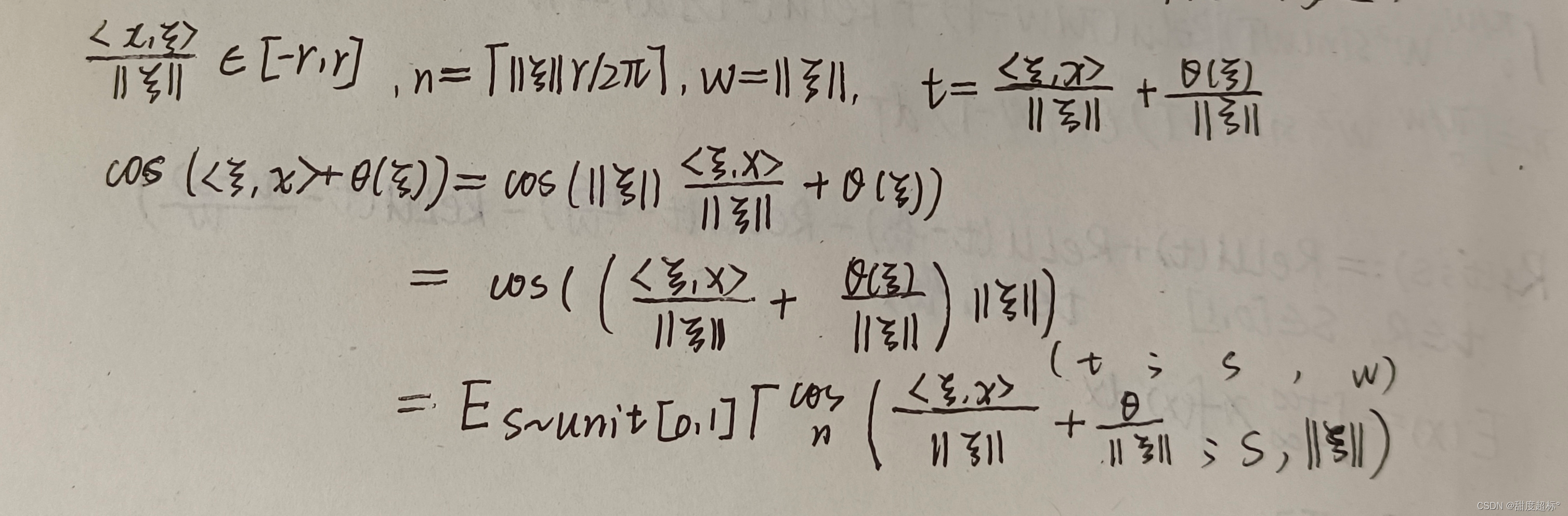








7 Proof of Theorem 2
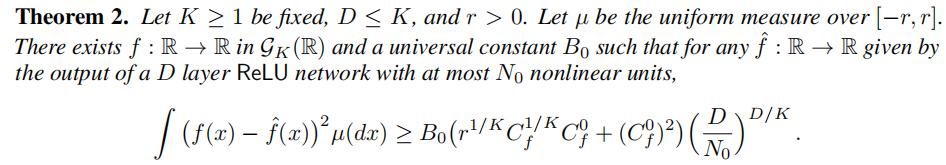
A Supplementary Material
A.1 Frequency Multipliers - Proofs
خزأاجّ¹زہي1µؤض¤أ÷£¬زٍخھثüتا³ُµبµؤ،£خزأا¸ّ³ِزہي2µؤض¤أ÷بçدآ،£
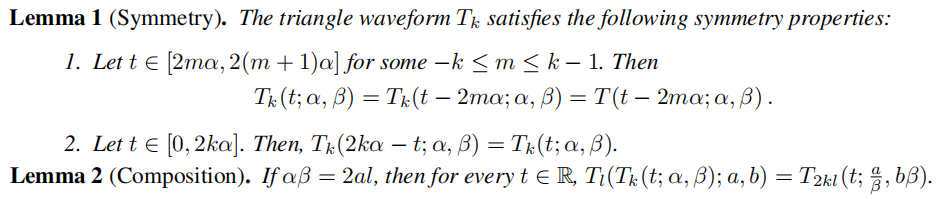

A.2 ReLU Representation for Sinusoids - Proofs