һ�����ع�Ľ���
��һ��������ع��ǻ���ѧϰ��һ�ַ���ģ�ͣ����ع���һ�ַ����㷨�����ڼ�Ч����ʵ����Ӧ�÷dz��㷺��
���������ع��Ӧ�ó���
������ʡ��Ƿ�Ϊ������Ϸ���Ƿ�������թƭ������˺�
���������ع��ԭ��
1.���ĵ㣺
���ع��������ֵ�ǣ����Իع�Ľ��
�ж����ع�������
2.����Ϊ���Իع�Ľ���������ǣ�
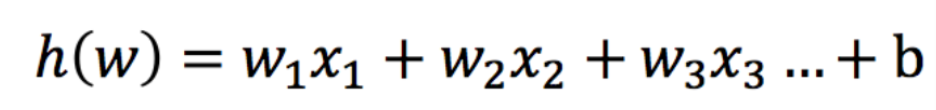 3.�������������sigmoid������
3.�������������sigmoid������
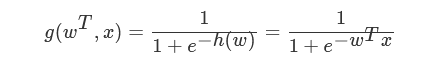
�жϱ���
�ع�Ľ�����뵽sigmoid��������
��������[0,1]�����һ������ֵ��Ĭ��Ϊ0.5Ϊ��ֵ
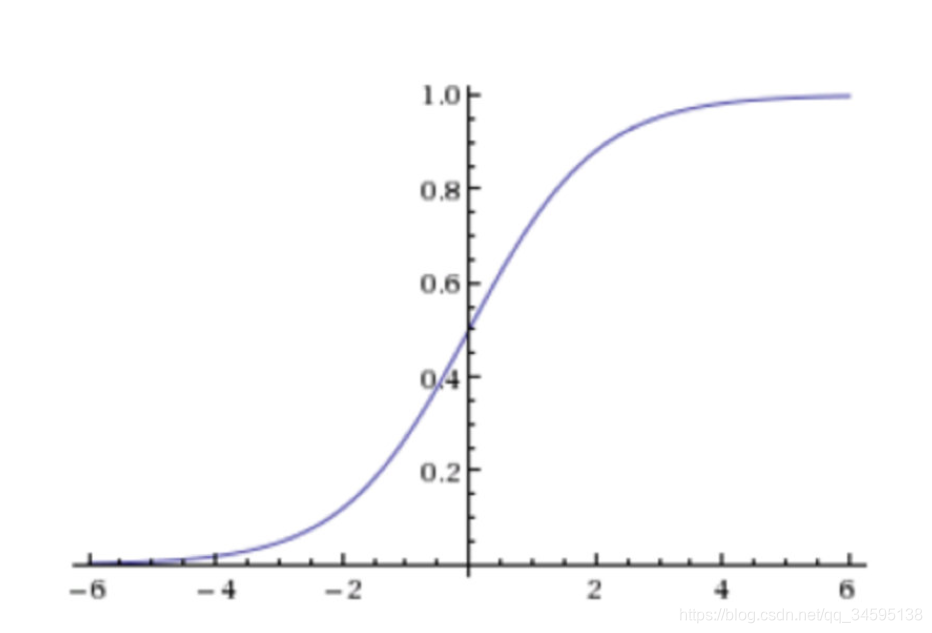 ����������(��Ҫ)���������������A��B�����Ҽ������ǵĸ���ֵΪ����A(1)������ĸ���ֵ��������һ�����������뵽���ع�������0.55����ô�������ֵ����0.5����ζ������ѵ������Ԥ��Ľ������A(1)�����ô��֮������ó����Ϊ0.3��ô��ѵ������Ԥ������ΪB(0)���
����������(��Ҫ)���������������A��B�����Ҽ������ǵĸ���ֵΪ����A(1)������ĸ���ֵ��������һ�����������뵽���ع�������0.55����ô�������ֵ����0.5����ζ������ѵ������Ԥ��Ľ������A(1)�����ô��֮������ó����Ϊ0.3��ô��ѵ������Ԥ������ΪB(0)���
�������ع����ֵ�ǿ��Խ��иı�ģ�������������У���������ֵ����Ϊ0.6����ô����Ľ��0.55��������B�ࡣ
��֮ǰ����������С���˷��������Իع����ʧ��
�����ع��У���Ԥ�������Ե�ʱ�����Ǹ���ô��������ʧ�أ�
 ��ô���ȥ�������ع��Ԥ��������ʵ����IJ����أ�
��ô���ȥ�������ع��Ԥ��������ʵ����IJ����أ�
��������ʧ�Լ��Ż�
1.������ع����ʧ��֮Ϊ������Ȼ��ʧ��
�ֿ����
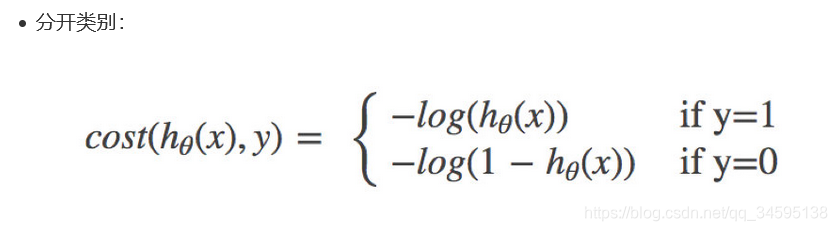 ����yΪ��ʵֵ��h��(x)ΪԤ��ֵ
����yΪ��ʵֵ��h��(x)ΪԤ��ֵ
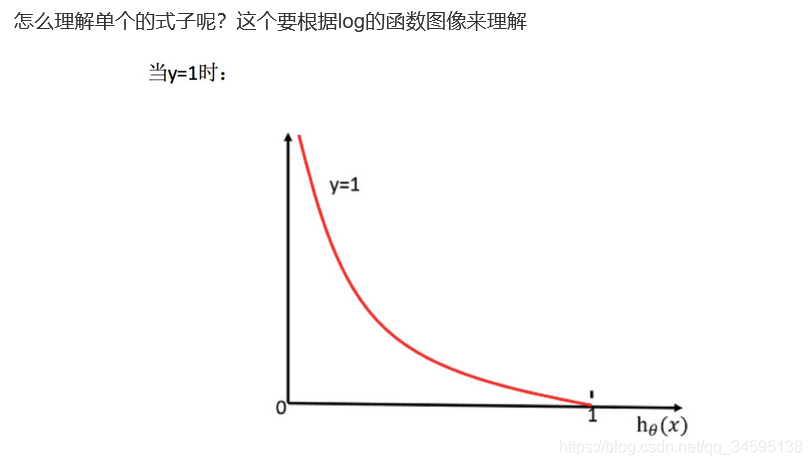 ���ۺ�ʱ�����Ƕ�ϣ����ʧ����ֵ��ԽСԽ��
���ۺ�ʱ�����Ƕ�ϣ����ʧ����ֵ��ԽСԽ��
��������ۣ���Ӧ����ʧ����ֵ��
��y=1ʱ������ϣ��h��(x)ֵԽ��Խ�ã�
��y=0ʱ������ϣ��h��(x)ֵԽСԽ���ۺ�������ʧ����
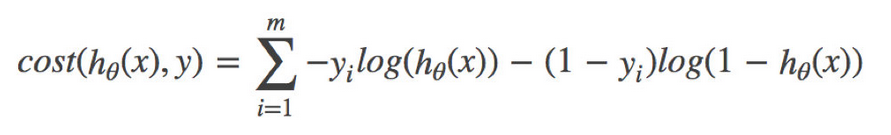 �����������ؾʹ��������Ǹ�����������һ�飬�������������ˡ�
�����������ؾʹ��������Ǹ�����������һ�飬�������������ˡ�
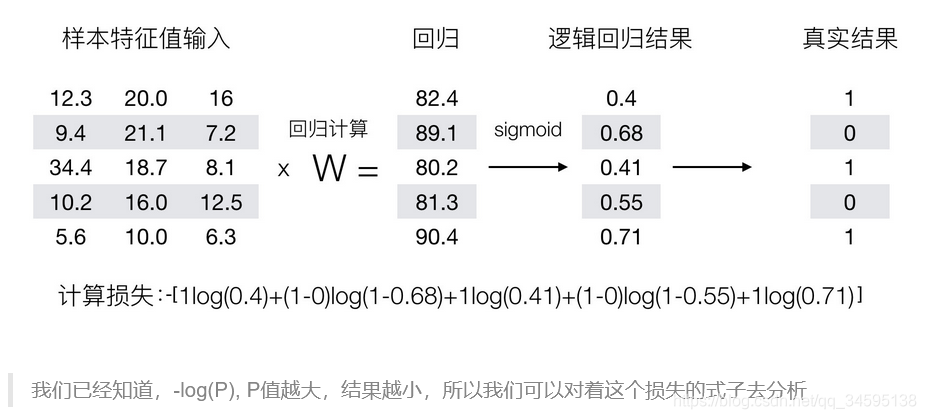 ���⣺
���⣺
��1�������Իع����Ľ��ֵW��X����sigmoid����������ó����ع�����
��2���ѻع����������ʵֵ���뵽��>�ۺ�������ʧ���������ռ���ó���ʧֵ
�����Ѿ�֪����-log��, PֵԽ���ԽС���������ǿ��Զ��������ʧ��ʽ��ȥ����
2.�Ż�
ͬ��ʹ���ݶ��½��Ż��㷨��ȥ������ʧ������ֵ������ȥ�������ع�ǰ���Ӧ�㷨��Ȩ�ز���������ԭ������1���ĸ��ʣ�����ԭ����0���ĸ��ʡ�
���ģ�С��
���ع���֪����
�������һ������������
���ع�����������Իع�����
���ع��ԭ�������ա�
���룺
���Իع�����
�����
sigmoid����
�������ֵӳ�䵽[0,1]
������һ����ֵ�����з����ж�
���ع����ʧ���Ż������ա�
��ʧ
������Ȼ��ʧ
������log˼�룬�������
��ʵֵ����0������1����������л���
�Ż�
����ԭ������1���ĸ��ʣ�����ԭ����0���ĸ��ʡ�
�������ع��API����
��һ���÷���
1.���sklear.linear_model.LogisticRegression(solver=��liblinear��,pennalty=��l2��,C=1.0)
solver={��liblinear��,��sag��,��saga��,��newton-cg��,��lbfgs��}
Ĭ��:��liblinear�������Ż�������㷨��
����С���ݼ���˵����liblinear���Ǹ�������ѡ����sag���͡�saga�����ڴ������ݼ�����졣
���ڶ������⣬ֻ�С�newton-cg���� ��sag���� 'saga���͡�lbfgs�����Դ���������ʧ;��liblinear�������ڡ�one-versus-rest�����ࡣ
penalty:��������
C:��������
Ĭ�Ͻ���������ٵĵ�������
LogisticRegression�����൱�� SGDClassifier(loss=��log��, penalty=" "),SGDClassifierʵ����һ����ͨ������ݶ��½�ѧϰ����ʹ��LogisticRegression(ʵ����SAG)
������������
1 �������ܣ�ͨ������Ԥ�ⰸ����ѧ�����ʹ�����ع��ģ�ͽ���ѵ��
2.��������
��1��699����������11�����ݣ���һ�����������id����9�зֱ���������
��ص�ҽѧ���������һ�б�ʾ�������͵���ֵ��
��2������16��ȱʧֵ���á�?�������
3.��������
1.��ȡ����
2.�������ݴ���
2.1 ȱʧֵ����
2.2 ȷ������ֵ,Ŀ��ֵ
2.3 �ָ�����
3.��������(����)
4.����ѧϰ(���ع�)
5.ģ������
4.����ʵ��
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegressionimport ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 1.��ȡ����
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class']data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names=names)
data.head()
# 2.�������ݴ���
# 2.1 ȱʧֵ����
data = data.replace(to_replace="?", value=np.NaN)
data = data.dropna()
# 2.2 ȷ������ֵ,Ŀ��ֵ
x = data.iloc[:, 1:10]
x.head()
y = data["Class"]
y.head()
# 2.3 �ָ�����
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)# 3.��������(����)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.����ѧϰ(���ع�)
**estimator = LogisticRegression()
estimator.fit(x_train, y_train)**
# 5.ģ������
**y_predict = estimator.predict(x_test)
y_predict
estimator.score(x_test, y_test)**
�ںܶ���ೡ���������Dz�һ��ֻ��עԤ���ȷ�ʣ���������
�����������֢�����ӣ��������Dz�����עԤ���ȷ�ʣ����ǹ�ע�����е��������У���֢������û�б�ȫ��Ԥ�⣨��⣩������
5.��
����Ԥ�ⰸ��ʵ�֡�֪����
�����������ȱʧֵ��һ��Ҫ������д���
ȷ�ʲ����Ǻ���������ȷ��Ψһ��
�ġ��������������C��ģ������������