文章目录
-
- [1st place 解决方案](https://www.kaggle.com/c/quora-insincere-questions-classification/discussion/80568)
- [2nd place solution](https://www.kaggle.com/c/quora-insincere-questions-classification/discussion/81137)
- [银牌方案](https://www.kaggle.com/c/quora-insincere-questions-classification/discussion/80568)
1st place 解决方案
模型结构
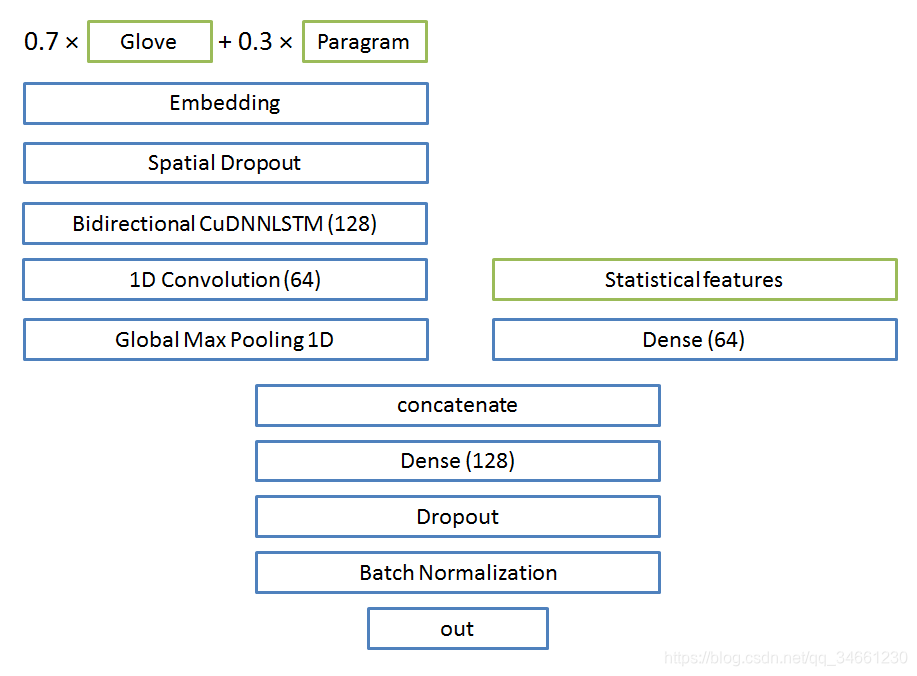
过复杂的模型不一定有效,这里只是使用了一层LSTM和卷积
Embeddings
- 多个embedding模型按权重组合
- embeding的目标是尽可能地为词典找到对应地向量,所以有以下地操作:
1 do not limit the vocab at all
2 checking singular and plural of the word
3 checking lowercase embeddings
4 removing special tokens
Threshold
rank prediction:
将概率转化为rank,然后多个模型排名均分除以长度,重新得到概率,此时的概率就不会过于贴合。
然后依旧是需要去固定搜索,然后take the mean best threshold on multiple CV runs or similar simulations
(mean,max,min)这些都要尝试,然后看与最优值的差别。
Runtime tricks
这很重要动态padding而不是一开始就padding好
- do not pad sequences to the same length based on the whole data, but just on a batch level
Fitting
它选择的batch_size是512,可以增加10times,结果相似(越多越快)
large batchsize<==>more model
Embrace the randomness
keras存在随机噪声,无法还原,但是可以拥抱它。因为毕竟最后采取ensembel的策略。
ensembel
We do a k-fold split (mostly 10-fold) and fit the same model up to v-times on the same training split and then successively evaluate it on the single out of fold.
10折训练10次,有100个模型,每一折训练很多次,最后在融合。
因为每一次初始矩阵随机化应该是不同的,所以是可以的。
What did not work for us
Different optimizers (focal loss was similar though)
Label smoothing
Auxiliary learning / multitask learning
Snapshot learning
Pseudo labeling
Fitting own embeddings with gensim
Spelling correction
Taking median/percentile of predicitons instead of average
More complex layers and architectures (Attention, QRNN, Capsule, larger/multiple LSTM layers, larger CNN kernel sizes, LGBM or bag of words)
Word collocations - Several words put together can bear a completely new meaning, which is not captured by embeddings. Glove turned out to have quite a lot of such collocations with words put together using “-” sign. So we replaced examples like “ethnical cleansing” with “ethnical-cleansing”, which is then captured by a more appropriate glove embedding. It showed no improvement on CV.
Extra statistical features - Presence of statistical features added a little bit to the accuracy based on CV, but we saw no improvement with other extra features, like sentiment or bag-of-words based variables.
Replacement of words with synonyms - An idea of replacing all nationalities (or e.g. political party) with the same word did not work at all.
Order the train data by the length of the sentences - This approach gave a dramatic improvement in the fitting time because each batch contained only sentences with similar sizes, but it hurt the accuracy of the model too much.
2nd place solution
模型结构
ensemble还是很重要,所以限时的情况下,模型是需要简单的。
QuoraModel(
(embedding): Embedding(222910, 668, padding_idx=0)
(text): RNNBlock(
(rnn): GRU(668, 128, batch_first=True, bidirectional=True)
)
(features_dense): Sequential(
(0): Linear(in_features=92, out_features=32, bias=True)
(1): ReLU(inplace)
(2): Linear(in_features=32, out_features=16, bias=True)
(3): ReLU(inplace)
)
(dense): Sequential(
(0): BatchNorm1d(1040, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace)
(2): Dropout(p=0.25)
(3): Linear(in_features=1040, out_features=64, bias=True)
(4): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace)
(6): Dropout(p=0.1)
(7): Linear(in_features=64, out_features=1, bias=True)
)
)
Embeddings
- 除了使用别人训练好的模型,自己也重新根据数据集训练一次比赛集的embedding
Runtime tricks
这很重要动态padding而不是一开始就padding好
- do not pad sequences to the same length based on the whole data, but just on a batch level
bestCV
Tune hyperparameters based on solid CV
银牌方案
这个博客最主要是提到了很多误区。小白一般看不出来的
首先,我觉得这个比赛胜利的关键有两个
- 对数据进行正确的预处理
- 有足够多、有差异性的正确的模型来增强你结果的鲁棒性
预处理
没有认真查看提供的词向量究竟是什么
可以看到,这个kernel第一步就把所有的字母变成小写了,这个是有问题的。这个比赛官方提供的预训练词向量有Glove,这个词向量并不是所有token小写的。例如英文里一些专有名词的缩写常用全大写来表示,强制小写浪费了很多可以提供的信息。
第二步,它给所有的标点前后都加了个空格。这是为什么呢?这是因为他用的keras tokenizer太弱了。 我们来看一个英文句子,Hello, what’s your name?,一个弱的只会识别空格的tokenizer会将这句话分为[‘Hello,’,‘what’s’,‘your’,‘name?’],即标点符号会和前面紧跟的词连在一起,这样的话肯定是找不到词向量的。所以他用人工的方法将标点符号前后用空格隔开,最终可以得到[‘Hello’,’,’,‘what’,’’’,‘s’,‘your’,‘name’,’?’]这样的token序列。但还有问题,那个s被单独分出来了。
作者其实是想在replace_typical_misspell里修正这些东西来着,但问题是前面已经把词都打散了,正则其实是无法匹配出来的。
再来看他对数字的处理,他把n位的数字变成了n个#,这也是很可笑的。载入Glove后可以很容易的发现里面含有大量的数字token,我记得大概20000以内都是能找到的,根本没必要用#替换。
最后再返回来看他的replace_typical_misspell正则,写的也有问题。他没有给匹配规则前后加\b,就是可能会匹配到一个长词的中间部分,然后进行替换了。这个问题当你的替换词典大了之后就很容易会出现问题。
采用Spacy强大工具
确实这个是工业界的一个开源强工具
那么正确的方式是什么呢?一个最基本就是选择一个强大的tokenizer。这里强推一下Spacy,真的是又快又强大。我们来看一下刚才那句话spacy会分成什么样
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp("Hello, what's your name?")
for t in doc:print(t)
得到的结果如下
Hello
,
what
's
your
name
?OOV
就是处理embedding里面没有的词(注意这里还有前面的很多处理)。
其实归根结底整个预处理只有一个目的让尽可能多的token能找到词向量。前面的操作只能完成90%的工作,因为有的词是真的找不到词向量,这也有两种情况,一种是拼错了,一种是词太新了。这个就只能靠人工规则来完成了。
举个例子,在语料库里有个词是Tensorflow,这个词很新,Glove里没有也在情理之中,为了能正确理解这个token,我把它替换成了deep learning framework。
对于拼错的词,也是可以处理的。第三名给出了一个方案(其实这个方案我也找到了,但是没有时间嵌入到代码里T_T)。其核心思想是用embedding提供的词作为基准,如果一个词被判断成了OOV,但编辑距离在2以内的某个词在词表里,那么就替换为这个词。
(对于英文,还有利用lemma词缀来补)
# https://www.kaggle.com/cpmpml/spell-checker-using-word2vec
spell_model = gensim.models.KeyedVectors.load_word2vec_format('../input/embeddings/wiki-news-300d-1M/wiki-news-300d-1M.vec')
words = spell_model.index2word
w_rank = {}
for i,word in enumerate(words):w_rank[word] = i
WORDS = w_rank
# Use fast text as vocabulary
def words(text): return re.findall(r'\w+', text.lower())
def P(word): "Probability of `word`."# use inverse of rank as proxy# returns 0 if the word isn't in the dictionaryreturn - WORDS.get(word, 0)
def correction(word): "Most probable spelling correction for word."return max(candidates(word), key=P)
def candidates(word): "Generate possible spelling corrections for word."return (known([word]) or known(edits1(word)) or [word])
def known(words): "The subset of `words` that appear in the dictionary of WORDS."return set(w for w in words if w in WORDS)
def edits1(word):"All edits that are one edit away from `word`."letters = 'abcdefghijklmnopqrstuvwxyz'splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]deletes = [L + R[1:] for L, R in splits if R]transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]replaces = [L + c + R[1:] for L, R in splits if R for c in letters]inserts = [L + c + R for L, R in splits for c in letters]return set(deletes + transposes + replaces + inserts)
def edits2(word): "All edits that are two edits away from `word`."return (e2 for e1 in edits1(word) for e2 in edits1(e1))
def singlify(word):return "".join([letter for i,letter in enumerate(word) if i == 0 or letter != word[i-1]])
模型
模型正确性
这次比赛公开的kernel里有不少错误。最典型的就是对embedding层结果进行dropout的部分。在Keras里有个模块叫SpatialDropout1D,顾名思义是对1维数据进行处理的,类似于2Ddropout,它也会随机mute一个feature channel。但是pytorch里并没有这个层,然后很多kernel就利用dropout2D来模拟这个行为。但可惜他们很多都写错了。
比如说这个模型
class NeuralNet(nn.Module):def __init__(self):super(NeuralNet, self).__init__()hidden_size = 60self.embedding = nn.Embedding(max_features, embed_size)self.embedding.weight = nn.Parameter(torch.tensor(embedding_matrix, dtype=torch.float32))self.embedding.weight.requires_grad = Falseself.embedding_dropout = nn.Dropout2d(0.1)self.lstm = nn.GRU(embed_size, hidden_size, bidirectional=True, batch_first=True)self.gru = nn.GRU(hidden_size*2, hidden_size, bidirectional=True, batch_first=True)self.lstm_attention = Attention(hidden_size*2, maxlen)self.gru_attention = Attention(hidden_size*2, maxlen)self.linear = nn.Linear(480, 16)self.relu = nn.ReLU()self.dropout = nn.Dropout(0.1)self.out = nn.Linear(16, 1)def forward(self, x):h_embedding = self.embedding(x)h_embedding = torch.squeeze(self.embedding_dropout(torch.unsqueeze(h_embedding, 0)))h_lstm, _ = self.lstm(h_embedding)h_gru, _ = self.gru(h_lstm)h_lstm_atten = self.lstm_attention(h_lstm)h_gru_atten = self.gru_attention(h_gru)avg_pool = torch.mean(h_gru, 1)max_pool, _ = torch.max(h_gru, 1)conc = torch.cat((h_lstm_atten, h_gru_atten, avg_pool, max_pool), 1)conc = self.relu(self.linear(conc))conc = self.dropout(conc)out = self.out(conc)return out
他在forward函数里写的是
torch.squeeze(self.embedding_dropout(torch.unsqueeze(h_embedding, 0)))
假设输入时一个BLC的Tensor,经过他第一个unsqueeze,变成了1BL*C。而nn.Dropout2d要求的输入是
#https://pytorch.org/docs/stable/nn.html?highlight=dropout2d#torch.nn.Dropout2d
Input: (N, C, H, W)
Output: (N, C, H, W) (same shape as input)
也就是说dropout发生在了batch维,这显然不是我们希望看到的。我很奇怪的是这种错误在比赛过程中没人提出来(我也没提出来0_0),类似kernel层出不穷,在比赛结束后终于有良心人士在discussion板块指出。
还有一些错误不是那么明显,就是pooling和softmax部分。大多数kernel里都是将输入句子提前pad好,这就导致大量的0会出现在句子(尤其是数据里的短句子)的开头或结尾。这个时候直接对RNN过后的Tensor进行mean或者max pooling都会产生问题。这里推荐看看知名NLP框架AllenNLP实现的masked_mean,masked_max。
而softmax的问题主要出现在attention部分。也可以参考AllenNLP的masked_softmax。
模型的性能
我最终的最好单模型比kernel里的强了不少,主要贡献我觉得有以下几个。
第一个是attention。在大部分的kernel里都用上了attention,但都只局限在了单头的attention模型上。我参考A STRUCTURED SELF-ATTENTIVE SENTENCE EMBEDDING里的方式,写了多头的attention,读者可以对比一下。
# single-head attention
# https://www.kaggle.com/hung96ad/pytorch-starterclass Attention(nn.Module):def __init__(self, feature_dim, step_dim, bias=True, **kwargs):super(Attention, self).__init__(**kwargs)self.supports_masking = Trueself.bias = biasself.feature_dim = feature_dimself.step_dim = step_dimself.features_dim = 0weight = torch.zeros(feature_dim, 1)nn.init.xavier_uniform_(weight)self.weight = nn.Parameter(weight)if bias:self.b = nn.Parameter(torch.zeros(step_dim))def forward(self, x, mask=None):feature_dim = self.feature_dimstep_dim = self.step_dimeij = torch.mm(x.contiguous().view(-1, feature_dim), self.weight).view(-1, step_dim)if self.bias:eij = eij + self.beij = torch.tanh(eij)a = torch.exp(eij)if mask is not None:a = a * maska = a / torch.sum(a, 1, keepdim=True) + 1e-10weighted_input = x * torch.unsqueeze(a, -1)return torch.sum(weighted_input, 1)
# multi-head attention
# 还改进了一些小细节,会比上面的版本快一些
class Attention(nn.Module):def __init__(self, feature_dim, bias=True, head_num=1, **kwargs):super(Attention, self).__init__(**kwargs)self.supports_masking = Trueself.bias = biasself.feature_dim = feature_dimself.head_num = head_numweight = torch.zeros(feature_dim, self.head_num)bias = torch.zeros((1, 1, self.head_num))nn.init.xavier_uniform_(weight)self.weight = nn.Parameter(weight)self.b = nn.Parameter(bias)def forward(self, x, mask=None):batch_size, step_dim, feature_dim = x.size()eij = torch.mm(x.contiguous().view(-1, feature_dim), # B*L*Hself.weight # B*H*1).view(-1, step_dim, self.head_num) # B*L*1if self.bias:eij = eij + self.beij = torch.tanh(eij)if mask is not None:eij = eij * mask - 99999.9 * (1 - mask)a = torch.softmax(eij, dim=1)weighted_input = torch.bmm(x.permute((0,2,1)),a).view(batch_size, -1)return weighted_input
词向量的如何重新训练
另一个是词向量的训练。所有的公开kernel都讲embedding层设置为不可训练,这当然是有原因的。第一,这个题目语料不是很大,训练embedding层很容易过拟合;第二,训练embedding层会引入几千万的参数,速度没法保证。
经过我的多次尝试,我得出了一个可以克服上面两个问题的方法:在最后一个epoch,用小学习率训练embedding层。
实现的时候充分利用pytorch的灵活性,相关代码如下
# model
class NeuralNet(nn.Module):def turn_on_embedding(self):self.embedding.weight.requires_grad = Truedef __init__(self, hidden_size=128, keyword_dim=None, meta_feat_dim=6, init_embedding=None):super(NeuralNet, self).__init__()self.hidden_size = hidden_sizeself.meta_feat_dim = meta_feat_dimself.keyword_dim = keyword_dimself.embedding = nn.Embedding(max_features, embed_size)if init_embedding is not None:self.embedding.weight.data.copy_(torch.from_numpy(init_embedding))self.embedding.weight.requires_grad = False# other code
# when training
if epoch == 5: # last epochrnn_model.turn_on_embedding()optimizer_rnn.add_param_group({
'params': rnn_model.embedding.parameters()})
实际测下来这样可以在最后一轮有一个大的飞跃,一轮的时间大概是不训练词向量的接近2倍。