Recurrent Neural Networks
ШЫРрВЂВЛЪЧУПЪБУППЬЖМДгвЛЦЌПеАзЕФДѓФдПЊЪМЫћУЧЕФЫМПМЁЃдкФудФЖСетЦЊЮФеТЪБКђЃЌФуЖМЪЧЛљгкздМКвбОгЕгаЕФЖдЯШЧАЫљМћДЪЕФРэНтРДЭЦЖЯЕБЧАДЪЕФецЪЕКЌвхЁЃЮвУЧВЛЛсНЋЫљгаЕФЖЋЮїЖМШЋВПЖЊЦњЃЌШЛКѓгУПеАзЕФДѓФдНјааЫМПМЁЃЮвУЧЕФЫМЯыгЕгаГжОУадЁЃ
ДЋЭГЕФЩёОЭјТчВЂВЛФмзіЕНетЕуЃЌПДЦ№РДвВЯёЪЧвЛжжОоДѓЕФБзЖЫЁЃР§ШчЃЌМйЩшФуЯЃЭћЖдЕчгАжаЕФУПИіЪБМфЕуЕФЪБМфРраЭНјааЗжРрЁЃДЋЭГЕФЩёОЭјТчгІИУКмФбРДДІРэетИіЮЪЬтЁЊЁЊЪЙгУЕчгАжаЯШЧАЕФЪТМўЭЦЖЯКѓајЕФЪТМўЁЃ
RNN НтОіСЫетИіЮЪЬтЁЃRNN ЪЧАќКЌбЛЗЕФЭјТчЃЌдЪаэаХЯЂЕФГжОУЛЏЁЃ

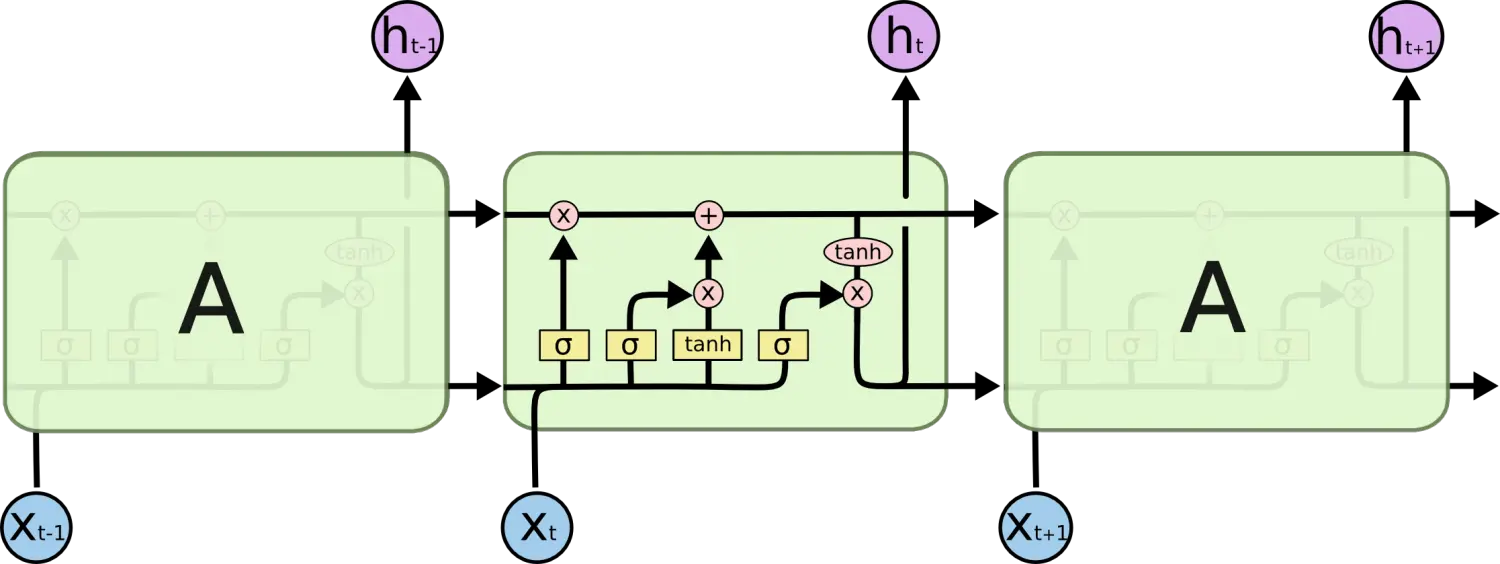
RNN АќКЌбЛЗ
дкЩЯУцЕФЪОР§ЭМжаЃЌЩёОЭјТчЕФФЃПщЃЌAЃЌе§дкЖСШЁФГИіЪфШы x_iЃЌВЂЪфГівЛИіжЕ h_iЁЃбЛЗПЩвдЪЙЕУаХЯЂПЩвдДгЕБЧАВНДЋЕнЕНЯТвЛВНЁЃ
етаЉбЛЗЪЙЕУ RNN ПДЦ№РДЗЧГЃЩёУиЁЃШЛЖјЃЌШчЙћФузаЯИЯыЯыЃЌетбљвВВЛБШвЛИіе§ГЃЕФЩёОЭјТчФбгкРэНтЁЃRNN ПЩвдБЛПДзіЪЧЭЌвЛЩёОЭјТчЕФЖрДЮИДжЦЃЌУПИіЩёОЭјТчФЃПщЛсАбЯћЯЂДЋЕнИјЯТвЛИіЁЃЫљвдЃЌШчЙћЮвУЧНЋетИібЛЗеЙПЊЃК
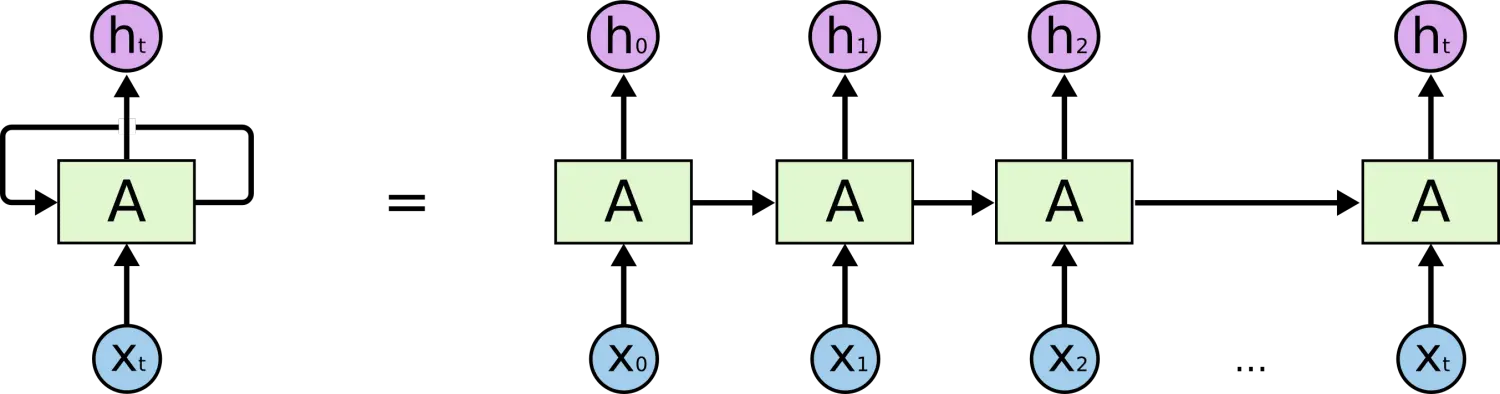
еЙПЊЕФ RNN
СДЪНЕФЬиеїНвЪОСЫ RNN БОжЪЩЯЪЧгыађСаКЭСаБэЯрЙиЕФЁЃЫћУЧЪЧЖдгкетРрЪ§ОнЕФзюздШЛЕФЩёОЭјТчМмЙЙЁЃ
ВЂЧв RNN вВвбОБЛШЫУЧгІгУСЫЃЁдкЙ§ШЅМИФъжаЃЌгІгУ RNN дкгявєЪЖБ№ЃЌгябдНЈФЃЃЌЗвыЃЌЭМЦЌУшЪіЕШЮЪЬтЩЯвбОШЁЕУвЛЖЈГЩЙІЃЌВЂЧветИіСаБэЛЙдкдіГЄЁЃЮвНЈвщДѓМвВЮПМ Andrej Karpathy ЕФВЉПЭЮФеТЁЊЁЊThe Unreasonable Effectiveness of Recurrent Neural Networks РДПДПДИќЗсИЛгаШЄЕФ RNN ЕФГЩЙІгІгУЁЃ
ЖјетаЉГЩЙІгІгУЕФЙиМќжЎДІОЭЪЧ LSTM ЕФЪЙгУЃЌетЪЧвЛжжЬиБ№ЕФ RNNЃЌБШБъзМЕФ RNN дкКмЖрЕФШЮЮёЩЯЖМБэЯжЕУИќКУЁЃМИКѕЫљгаЕФСюШЫеёЗмЕФЙигк RNN ЕФНсЙћЖМЪЧЭЈЙ§ LSTM ДяЕНЕФЁЃетЦЊВЉЮФвВЛсОЭ LSTM НјааеЙПЊЁЃ
ГЄЦквРРЕЃЈLong-Term DependenciesЃЉЮЪЬт
RNN ЕФЙиМќЕужЎвЛОЭЪЧЫћУЧПЩвдгУРДСЌНгЯШЧАЕФаХЯЂЕНЕБЧАЕФШЮЮёЩЯЃЌР§ШчЪЙгУЙ§ШЅЕФЪгЦЕЖЮРДЭЦВтЖдЕБЧАЖЮЕФРэНтЁЃШчЙћ RNN ПЩвдзіЕНетИіЃЌЫћУЧОЭБфЕУЗЧГЃгагУЁЃЕЋЪЧецЕФПЩвдУДЃПД№АИЪЧЃЌЛЙгаКмЖрвРРЕвђЫиЁЃ
гаЪБКђЃЌЮвУЧНіНіашвЊжЊЕРЯШЧАЕФаХЯЂРДжДааЕБЧАЕФШЮЮёЁЃР§ШчЃЌЮвУЧгавЛИігябдФЃаЭгУРДЛљгкЯШЧАЕФДЪРДдЄВтЯТвЛИіДЪЁЃШчЙћЮвУЧЪдзХдЄВт ЁАthe clouds are in the skyЁБ зюКѓЕФДЪЃЌЮвУЧВЂВЛашвЊШЮКЮЦфЫћЕФЩЯЯТЮФ ЁЊЁЊ вђДЫЯТвЛИіДЪКмЯдШЛОЭгІИУЪЧ skyЁЃдкетбљЕФГЁОАжаЃЌЯрЙиЕФаХЯЂКЭдЄВтЕФДЪЮЛжУжЎМфЕФМфИєЪЧЗЧГЃаЁЕФЃЌRNN ПЩвдбЇЛсЪЙгУЯШЧАЕФаХЯЂЁЃ
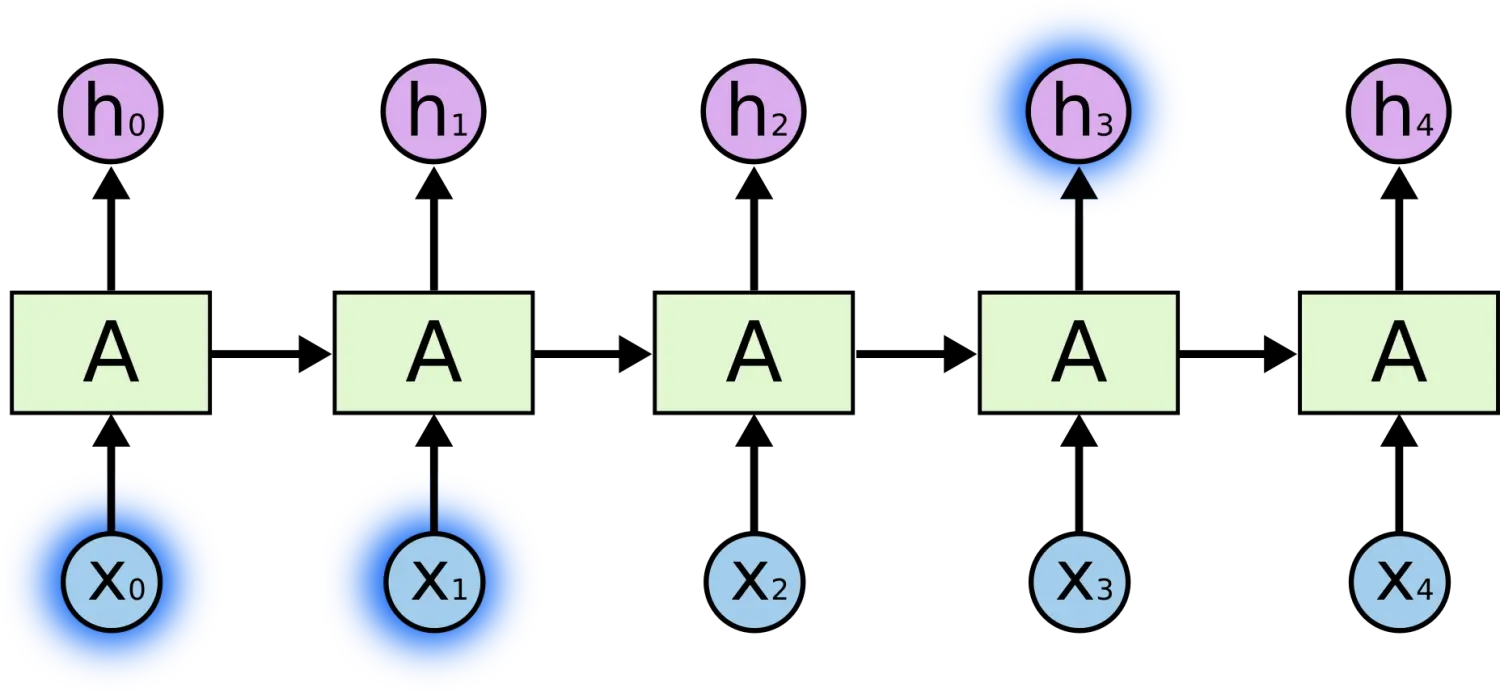
ВЛЬЋГЄЕФЯрЙиаХЯЂКЭЮЛжУМфИє
ЕЋЪЧЭЌбљЛсгавЛаЉИќМгИДдгЕФГЁОАЁЃМйЩшЮвУЧЪдзХШЅдЄВтЁАI grew up in France... I speak fluent FrenchЁБзюКѓЕФДЪЁЃЕБЧАЕФаХЯЂНЈвщЯТвЛИіДЪПЩФмЪЧвЛжжгябдЕФУћзжЃЌЕЋЪЧШчЙћЮвУЧашвЊХЊЧхГўЪЧЪВУДгябдЃЌЮвУЧЪЧашвЊЯШЧАЬсЕНЕФРыЕБЧАЮЛжУКмдЖЕФ France ЕФЩЯЯТЮФЕФЁЃетЫЕУїЯрЙиаХЯЂКЭЕБЧАдЄВтЮЛжУжЎМфЕФМфИєОЭПЯЖЈБфЕУЯрЕБЕФДѓЁЃ
ВЛавЕФЪЧЃЌдкетИіМфИєВЛЖЯдіДѓЪБЃЌRNN ЛсЩЅЪЇбЇЯАЕНСЌНгШчДЫдЖЕФаХЯЂЕФФмСІЁЃ
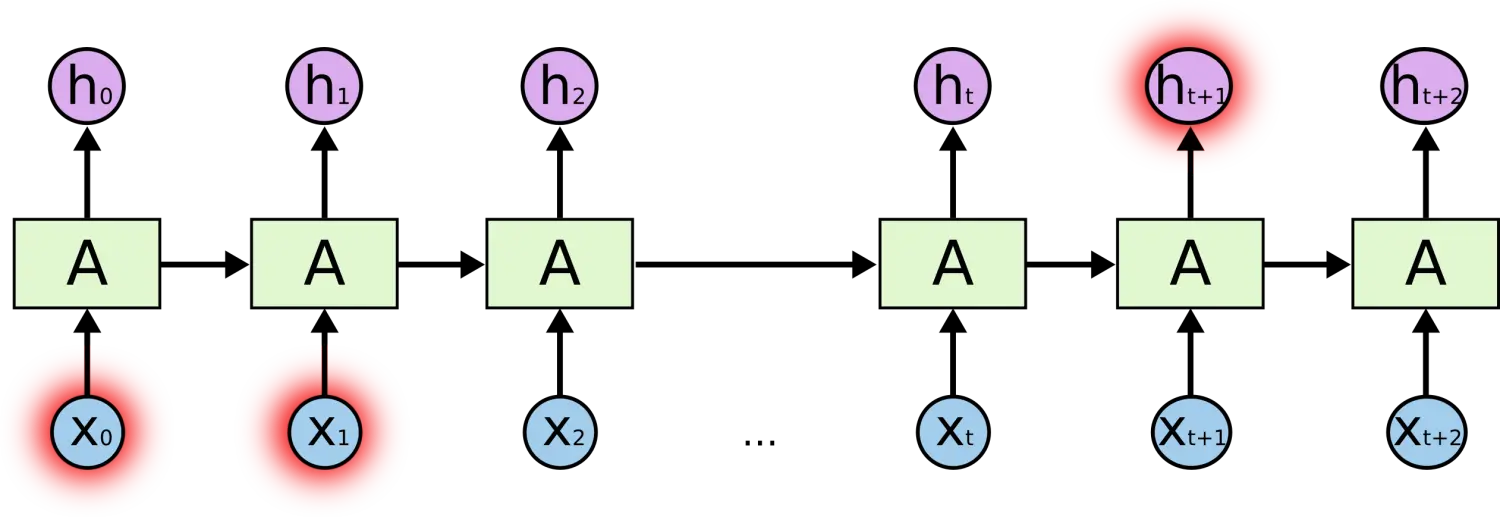
ЯрЕБГЄЕФЯрЙиаХЯЂКЭЮЛжУМфИє
дкРэТлЩЯЃЌRNN ОјЖдПЩвдДІРэетбљЕФ ГЄЦквРРЕ ЮЪЬтЁЃШЫУЧПЩвдзаЯИЬєбЁВЮЪ§РДНтОіетРрЮЪЬтжаЕФзюГѕМЖаЮЪНЃЌЕЋдкЪЕМљжаЃЌRNN ПЯЖЈВЛФмЙЛГЩЙІбЇЯАЕНетаЉжЊЪЖЁЃBengio, et al. (1994)ЕШШЫЖдИУЮЪЬтНјааСЫЩюШыЕФбаОПЃЌЫћУЧЗЂЯжвЛаЉЪЙбЕСЗ RNN БфЕУЗЧГЃРЇФбЕФЯрЕБИљБОЕФдвђЁЃ
ШЛЖјЃЌавдЫЕФЪЧЃЌLSTM ВЂУЛгаетИіЮЪЬтЃЁ
LSTM ЭјТч
Long Short Term ЭјТчЁЊЁЊ вЛАуОЭНазі LSTM ЁЊЁЊЪЧвЛжж RNN ЬиЪтЕФРраЭЃЌПЩвдбЇЯАГЄЦквРРЕаХЯЂЁЃLSTM гЩHochreiter & Schmidhuber (1997)ЬсГіЃЌВЂдкНќЦкБЛAlex GravesНјааСЫИФСМКЭЭЦЙуЁЃдкКмЖрЮЪЬтЃЌLSTM ЖМШЁЕУЯрЕБОоДѓЕФГЩЙІЃЌВЂЕУЕНСЫЙуЗКЕФЪЙгУЁЃ
LSTM ЭЈЙ§ПЬвтЕФЩшМЦРДБмУтГЄЦквРРЕЮЪЬтЁЃМЧзЁГЄЦкЕФаХЯЂдкЪЕМљжаЪЧ LSTM ЕФФЌШЯааЮЊЃЌЖјЗЧашвЊИЖГіКмДѓДњМлВХФмЛёЕУЕФФмСІЃЁ
Ыљга RNN ЖМОпгавЛжжжиИДЩёОЭјТчФЃПщЕФСДЪНЕФаЮЪНЁЃдкБъзМЕФ RNN жаЃЌетИіжиИДЕФФЃПщжЛгавЛИіЗЧГЃМђЕЅЕФНсЙЙЃЌР§ШчвЛИі tanh ВуЁЃ
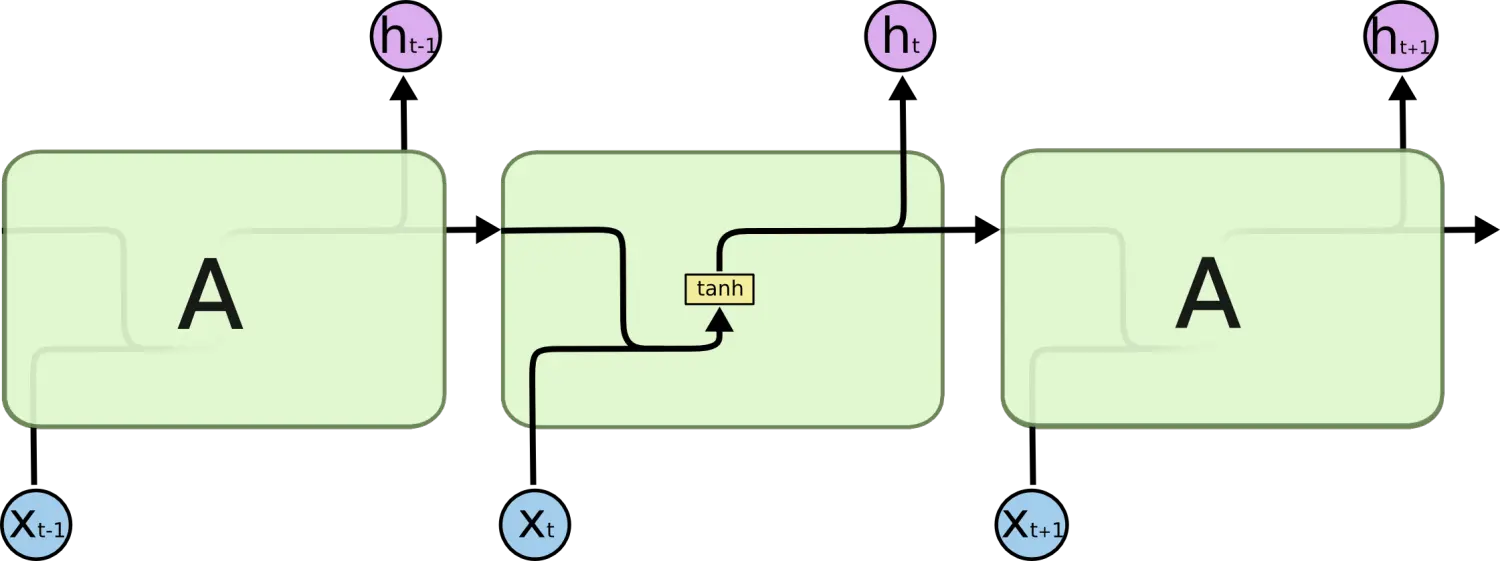
БъзМ RNN жаЕФжиИДФЃПщАќКЌЕЅвЛЕФВу
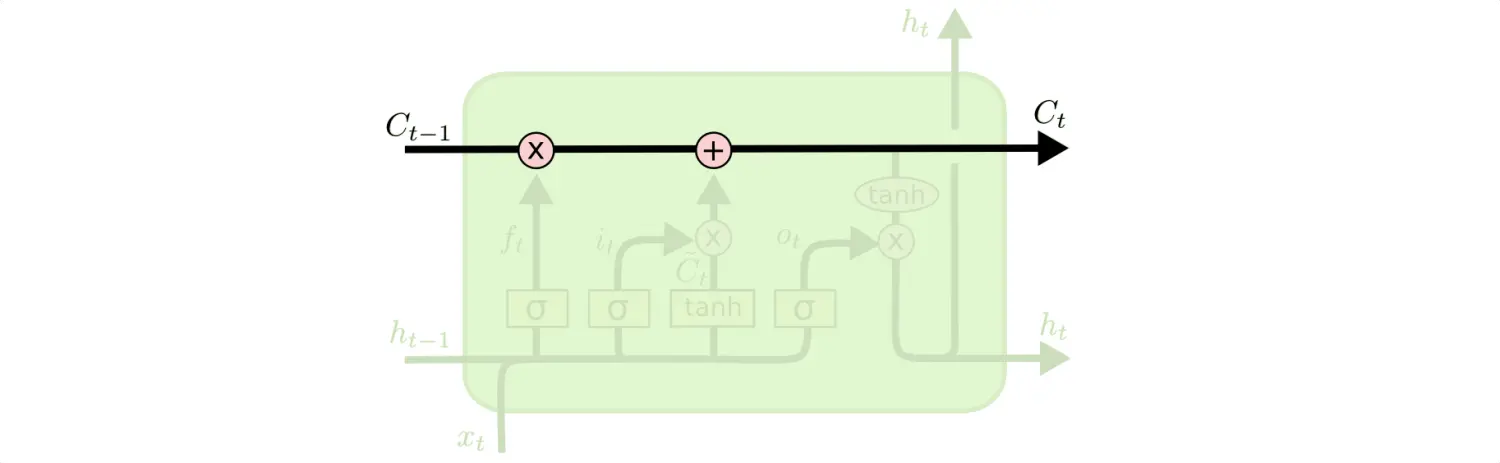
LSTM ЭЌбљЪЧетбљЕФНсЙЙЃЌЕЋЪЧжиИДЕФФЃПщгЕгавЛИіВЛЭЌЕФНсЙЙЁЃВЛЭЌгк ЕЅвЛЩёОЭјТчВуЃЌетРяЪЧгаЫФИіЃЌвдвЛжжЗЧГЃЬиЪтЕФЗНЪННјааНЛЛЅЁЃ
LSTM жаЕФжиИДФЃПщАќКЌЫФИіНЛЛЅЕФВу
ВЛБиЕЃаФетРяЕФЯИНкЁЃЮвУЧЛсвЛВНвЛВНЕиЦЪЮі LSTM НтЮіЭМЁЃЯждкЃЌЮвУЧЯШРДЪьЯЄвЛЯТЭМжаЪЙгУЕФИїжждЊЫиЕФЭМБъЁЃ

LSTM жаЕФЭМБъ
дкЩЯУцЕФЭМР§жаЃЌУПвЛЬѕКкЯпДЋЪфзХвЛећИіЯђСПЃЌДгвЛИіНкЕуЕФЪфГіЕНЦфЫћНкЕуЕФЪфШыЁЃЗлЩЋЕФШІДњБэ pointwise ЕФВйзїЃЌжюШчЯђСПЕФКЭЃЌЖјЛЦЩЋЕФОиеѓОЭЪЧбЇЯАЕНЕФЩёОЭјТчВуЁЃКЯдквЛЦ№ЕФЯпБэЪОЯђСПЕФСЌНгЃЌЗжПЊЕФЯпБэЪОФкШнБЛИДжЦЃЌШЛКѓЗжЗЂЕНВЛЭЌЕФЮЛжУЁЃ
LSTM ЕФКЫаФЫМЯы
LSTM ЕФЙиМќОЭЪЧЯИАћзДЬЌЃЌЫЎЦНЯпдкЭМЩЯЗНЙсДЉдЫааЁЃ
ЯИАћзДЬЌРрЫЦгкДЋЫЭДјЁЃжБНгдкећИіСДЩЯдЫааЃЌжЛгавЛаЉЩйСПЕФЯпадНЛЛЅЁЃаХЯЂдкЩЯУцСїДЋБЃГжВЛБфЛсКмШнвзЁЃ
Paste_Image.png
LSTM гаЭЈЙ§ОЋаФЩшМЦЕФГЦзїЮЊЁАУХЁБЕФНсЙЙРДШЅГ§ЛђепдіМгаХЯЂЕНЯИАћзДЬЌЕФФмСІЁЃУХЪЧвЛжжШУаХЯЂбЁдёЪНЭЈЙ§ЕФЗНЗЈЁЃЫћУЧАќКЌвЛИі sigmoid ЩёОЭјТчВуКЭвЛИі pointwise ГЫЗЈВйзїЁЃ
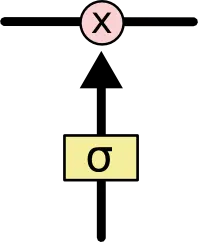
Paste_Image.png
Sigmoid ВуЪфГі 0 ЕН 1 жЎМфЕФЪ§жЕЃЌУшЪіУПИіВПЗжгаЖрЩйСППЩвдЭЈЙ§ЁЃ0 ДњБэЁАВЛаэШЮКЮСПЭЈЙ§ЁБЃЌ1 ОЭжИЁАдЪаэШЮвтСПЭЈЙ§ЁБЃЁ
LSTM гЕгаШ§ИіУХЃЌРДБЃЛЄКЭПижЦЯИАћзДЬЌЁЃ
ж№ВНРэНт LSTM
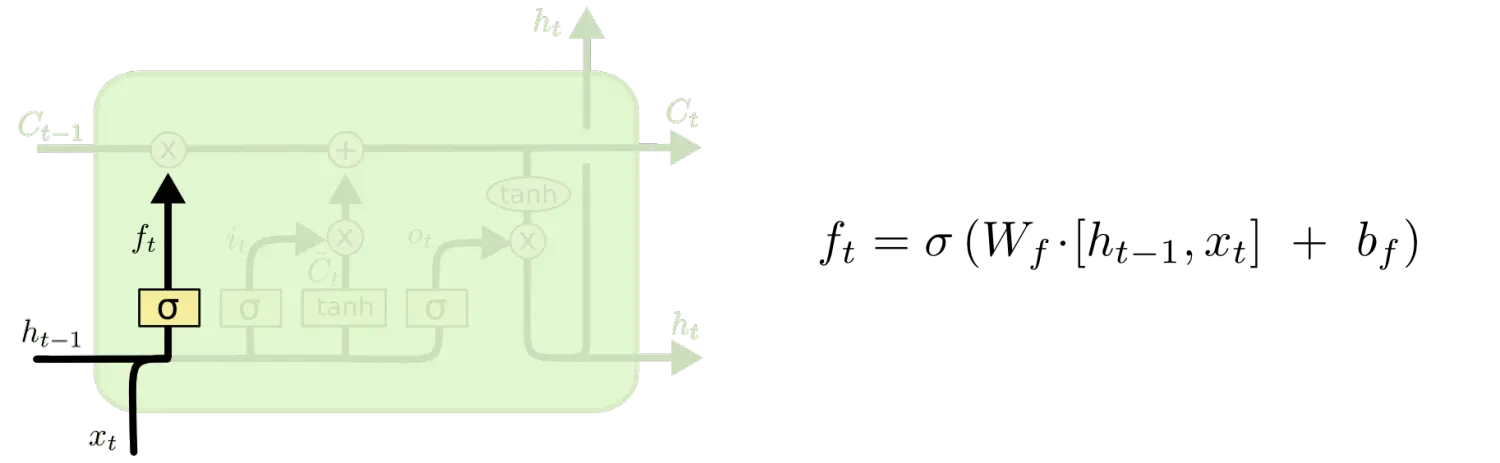
дкЮвУЧ LSTM жаЕФЕквЛВНЪЧОіЖЈЮвУЧЛсДгЯИАћзДЬЌжаЖЊЦњЪВУДаХЯЂЁЃетИіОіЖЈЭЈЙ§вЛИіГЦЮЊЭќМЧУХВуЭъГЩЁЃИУУХЛсЖСШЁh_{t-1}КЭx_tЃЌЪфГівЛИідк 0 ЕН 1 жЎМфЕФЪ§жЕИјУПИідкЯИАћзДЬЌC_{t-1}жаЕФЪ§зжЁЃ1 БэЪОЁАЭъШЋБЃСєЁБЃЌ0 БэЪОЁАЭъШЋЩсЦњЁБЁЃ
ШУЮвУЧЛиЕНгябдФЃаЭЕФР§згжаРДЛљгквбОПДЕНЕФдЄВтЯТвЛИіДЪЁЃдкетИіЮЪЬтжаЃЌЯИАћзДЬЌПЩФмАќКЌЕБЧАжїгяЕФадБ№ЃЌвђДЫе§ШЗЕФДњДЪПЩвдБЛбЁдёГіРДЁЃЕБЮвУЧПДЕНаТЕФжїгяЃЌЮвУЧЯЃЭћЭќМЧОЩЕФжїгяЁЃ
ОіЖЈЖЊЦњаХЯЂ
ЯТвЛВНЪЧШЗЖЈЪВУДбљЕФаТаХЯЂБЛДцЗХдкЯИАћзДЬЌжаЁЃетРяАќКЌСНИіВПЗжЁЃЕквЛЃЌsigmoid ВуГЦ ЁАЪфШыУХВуЁБ ОіЖЈЪВУДжЕЮвУЧНЋвЊИќаТЁЃШЛКѓЃЌвЛИі tanh ВуДДНЈвЛИіаТЕФКђбЁжЕЯђСПЃЌ\tilde{C}_tЃЌЛсБЛМгШыЕНзДЬЌжаЁЃЯТвЛВНЃЌЮвУЧЛсНВетСНИіаХЯЂРДВњЩњЖдзДЬЌЕФИќаТЁЃ
дкЮвУЧгябдФЃаЭЕФР§згжаЃЌЮвУЧЯЃЭћдіМгаТЕФжїгяЕФадБ№ЕНЯИАћзДЬЌжаЃЌРДЬцДњОЩЕФашвЊЭќМЧЕФжїгяЁЃ
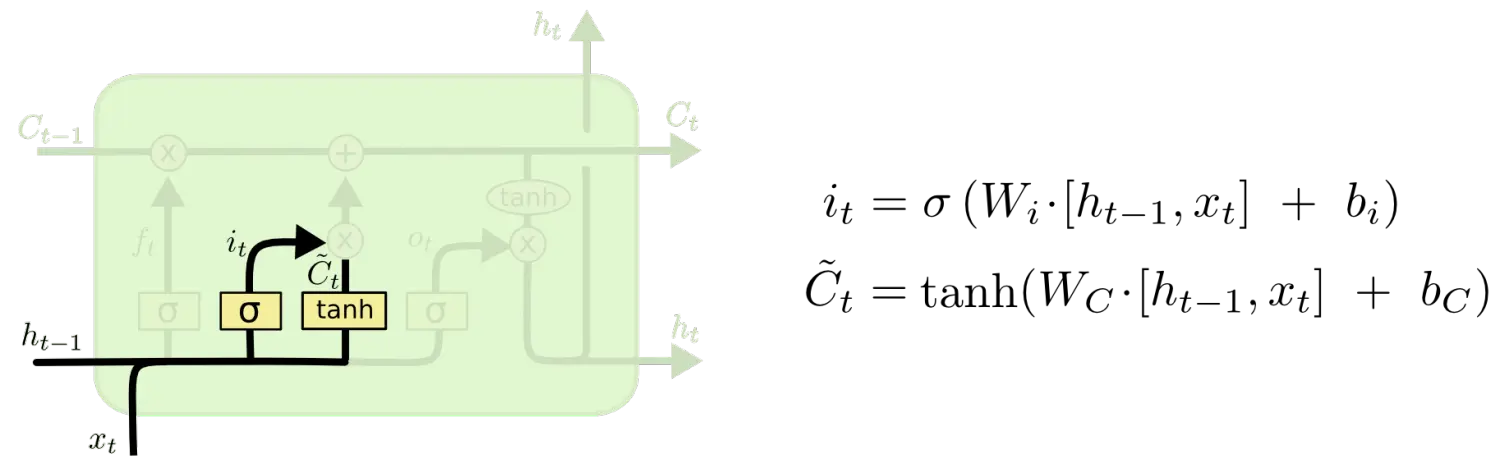
ШЗЖЈИќаТЕФаХЯЂ
ЯждкЪЧИќаТОЩЯИАћзДЬЌЕФЪБМфСЫЃЌC_{t-1}ИќаТЮЊC_tЁЃЧАУцЕФВНжшвбООіЖЈСЫНЋЛсзіЪВУДЃЌЮвУЧЯждкОЭЪЧЪЕМЪШЅЭъГЩЁЃ
ЮвУЧАбОЩзДЬЌгыf_tЯрГЫЃЌЖЊЦњЕєЮвУЧШЗЖЈашвЊЖЊЦњЕФаХЯЂЁЃНгзХМгЩЯi_t * \tilde{C}_tЁЃетОЭЪЧаТЕФКђбЁжЕЃЌИљОнЮвУЧОіЖЈИќаТУПИізДЬЌЕФГЬЖШНјааБфЛЏЁЃ
дкгябдФЃаЭЕФР§згжаЃЌетОЭЪЧЮвУЧЪЕМЪИљОнЧАУцШЗЖЈЕФФПБъЃЌЖЊЦњОЩДњДЪЕФадБ№аХЯЂВЂЬэМгаТЕФаХЯЂЕФЕиЗНЁЃ
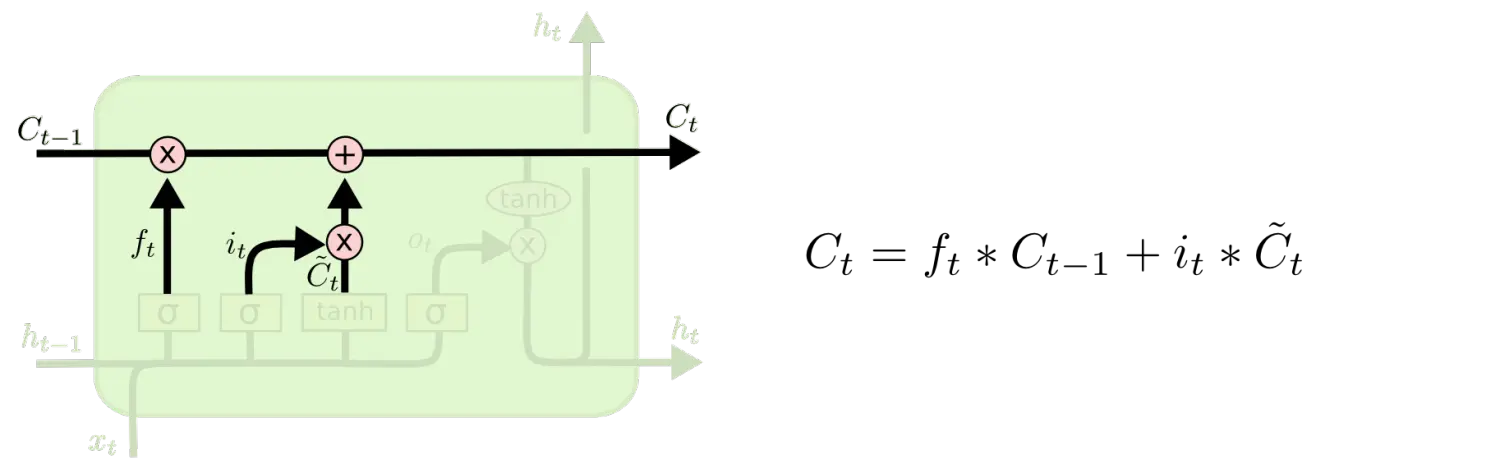
ИќаТЯИАћзДЬЌ
зюжеЃЌЮвУЧашвЊШЗЖЈЪфГіЪВУДжЕЁЃетИіЪфГіНЋЛсЛљгкЮвУЧЕФЯИАћзДЬЌЃЌЕЋЪЧвВЪЧвЛИіЙ§ТЫКѓЕФАцБОЁЃЪзЯШЃЌЮвУЧдЫаавЛИі sigmoid ВуРДШЗЖЈЯИАћзДЬЌЕФФФИіВПЗжНЋЪфГіГіШЅЁЃНгзХЃЌЮвУЧАбЯИАћзДЬЌЭЈЙ§ tanh НјааДІРэЃЈЕУЕНвЛИідк -1 ЕН 1 жЎМфЕФжЕЃЉВЂНЋЫќКЭ sigmoid УХЕФЪфГіЯрГЫЃЌзюжеЮвУЧНіНіЛсЪфГіЮвУЧШЗЖЈЪфГіЕФФЧВПЗжЁЃ
дкгябдФЃаЭЕФР§згжаЃЌвђЮЊЫћОЭПДЕНСЫвЛИі ДњДЪЃЌПЩФмашвЊЪфГігывЛИі ЖЏДЪ ЯрЙиЕФаХЯЂЁЃР§ШчЃЌПЩФмЪфГіЪЧЗёДњДЪЪЧЕЅЪ§ЛЙЪЧИКЪ§ЃЌетбљШчЙћЪЧЖЏДЪЕФЛАЃЌЮвУЧвВжЊЕРЖЏДЪашвЊНјааЕФДЪаЮБфЛЏЁЃ
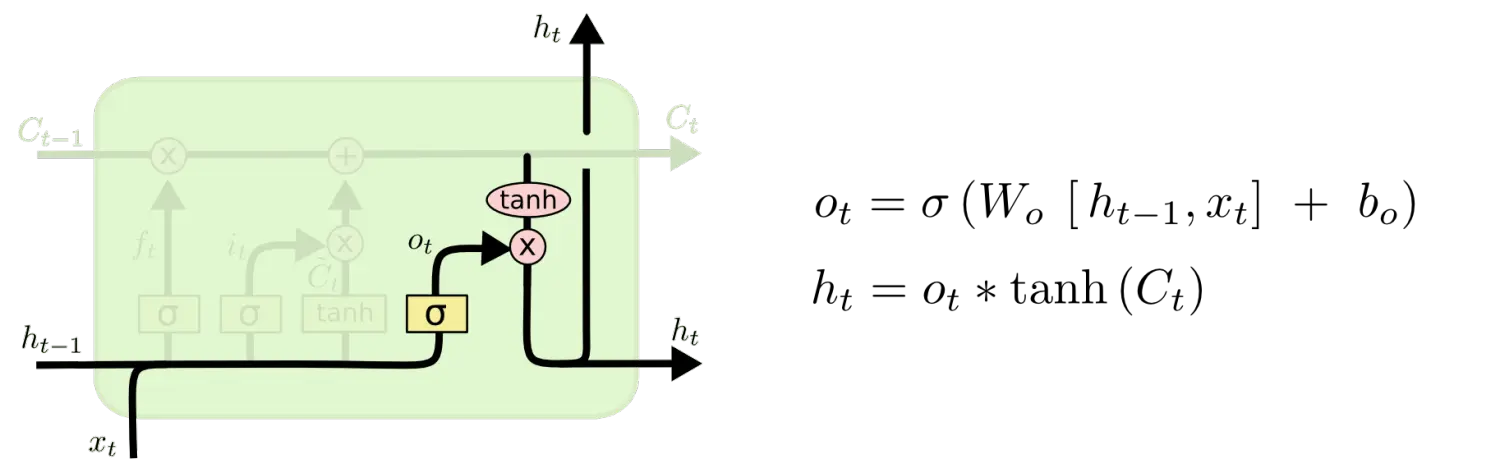
ЪфГіаХЯЂ
LSTM ЕФБфЬх
ЮвУЧЕНФПЧАЮЊжЙЖМЛЙдкНщЩме§ГЃЕФ LSTMЁЃЕЋЪЧВЛЪЧЫљгаЕФ LSTM ЖМГЄГЩвЛИібљзгЕФЁЃЪЕМЪЩЯЃЌМИКѕЫљгаАќКЌ LSTM ЕФТлЮФЖМВЩгУСЫЮЂаЁЕФБфЬхЁЃВювьЗЧГЃаЁЃЌЕЋЪЧвВжЕЕУФУГіРДНВвЛЯТЁЃ
ЦфжавЛИіСїаЮЕФ LSTM БфЬхЃЌОЭЪЧгЩ Gers & Schmidhuber (2000) ЬсГіЕФЃЌдіМгСЫ ЁАpeephole connectionЁБЁЃЪЧЫЕЃЌЮвУЧШУ УХВу вВЛсНгЪмЯИАћзДЬЌЕФЪфШыЁЃ
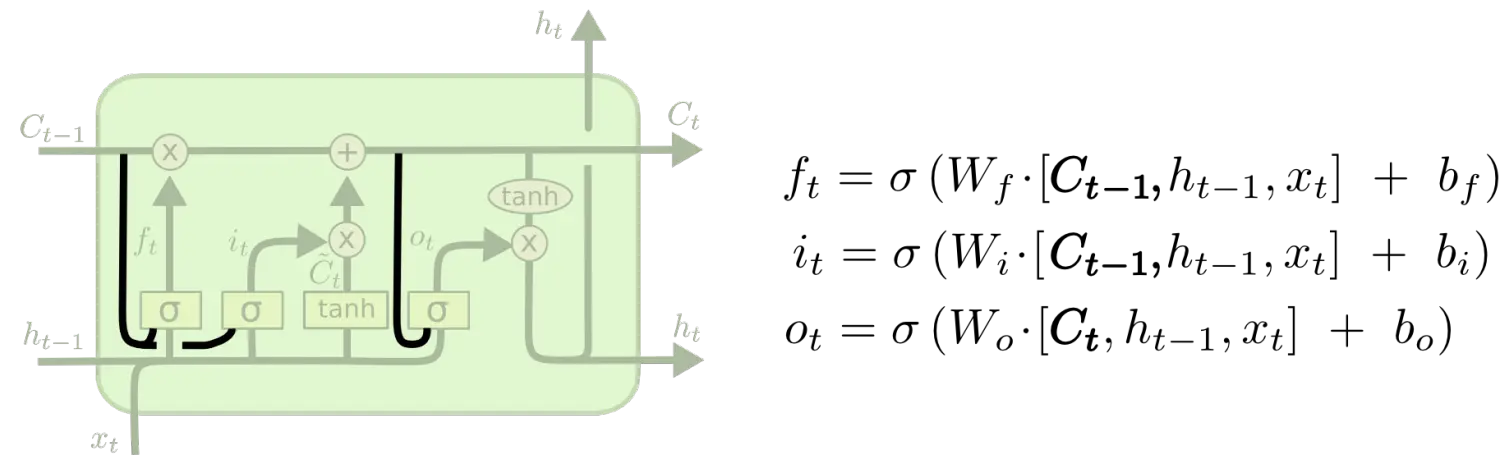
peephole СЌНг
ЩЯУцЕФЭМР§жаЃЌЮвУЧдіМгСЫ peephole ЕНУПИіУХЩЯЃЌЕЋЪЧаэЖрТлЮФЛсМгШыВПЗжЕФ peephole ЖјЗЧЫљгаЖММгЁЃ
СэвЛИіБфЬхЪЧЭЈЙ§ЪЙгУ coupled ЭќМЧКЭЪфШыУХЁЃВЛЭЌгкжЎЧАЪЧЗжПЊШЗЖЈЪВУДЭќМЧКЭашвЊЬэМгЪВУДаТЕФаХЯЂЃЌетРяЪЧвЛЭЌзіГіОіЖЈЁЃЮвУЧНіНіЛсЕБЮвУЧНЋвЊЪфШыдкЕБЧАЮЛжУЪБЭќМЧЁЃЮвУЧНіНіЪфШыаТЕФжЕЕНФЧаЉЮвУЧвбОЭќМЧОЩЕФаХЯЂЕФФЧаЉзДЬЌ ЁЃ

coupled ЭќМЧУХКЭЪфШыУХ
СэвЛИіИФЖЏНЯДѓЕФБфЬхЪЧ Gated Recurrent Unit (GRU)ЃЌетЪЧгЩ Cho, et al. (2014) ЬсГіЁЃЫќНЋЭќМЧУХКЭЪфШыУХКЯГЩСЫвЛИіЕЅвЛЕФ ИќаТУХЁЃЭЌбљЛЙЛьКЯСЫЯИАћзДЬЌКЭвўВизДЬЌЃЌКЭЦфЫћвЛаЉИФЖЏЁЃзюжеЕФФЃаЭБШБъзМЕФ LSTM ФЃаЭвЊМђЕЅЃЌвВЪЧЗЧГЃСїааЕФБфЬхЁЃ

GRU
етРяжЛЪЧВПЗжСїааЕФ LSTM БфЬхЁЃЕБШЛЛЙгаКмЖрЦфЫћЕФЃЌШчYao, et al. (2015) ЬсГіЕФ Depth Gated RNNЁЃЛЙгагУвЛаЉЭъШЋВЛЭЌЕФЙлЕуРДНтОіГЄЦквРРЕЕФЮЪЬтЃЌШчKoutnik, et al. (2014) ЬсГіЕФ Clockwork RNNЁЃ
вЊЮЪФФИіБфЬхЪЧзюКУЕФЃПЦфжаЕФВювьадецЕФживЊТ№ЃПGreff, et al. (2015) ИјГіСЫСїааБфЬхЕФБШНЯЃЌНсТлЪЧЫћУЧЛљБОЩЯЪЧвЛбљЕФЁЃJozefowicz, et al. (2015) дђдкГЌЙ§ 1 Эђжж RNN МмЙЙЩЯНјааСЫВтЪдЃЌЗЂЯжвЛаЉМмЙЙдкФГаЉШЮЮёЩЯвВШЁЕУСЫБШ LSTM ИќКУЕФНсЙћЁЃ

JozefowiczЕШШЫТлЮФНиЭМ
НсТл
ИеПЊЪМЃЌЮвЬсЕНЭЈЙ§ RNN ЕУЕНживЊЕФНсЙћЁЃБОжЪЩЯЫљгаетаЉЖМПЩвдЪЙгУ LSTM ЭъГЩЁЃЖдгкДѓЖрЪ§ШЮЮёШЗЪЕеЙЪОСЫИќКУЕФадФмЃЁ
гЩгк LSTM вЛАуЪЧЭЈЙ§вЛЯЕСаЕФЗНГЬБэЪОЕФЃЌЪЙЕУ LSTM гавЛЕуСюШЫЗбНтЁЃШЛЖјБОЮФжавЛВНвЛВНЕиНтЪЭШУетжжРЇЛѓЯћГ§СЫВЛЩйЁЃ
LSTM ЪЧЮвУЧдк RNN жаЛёЕУЕФживЊГЩЙІЁЃКмздШЛЕиЃЌЮвУЧвВЛсПМТЧЃКФФРяЛсгаИќМгжиДѓЕФЭЛЦЦФиЃПдкбаОПШЫдБМфЦеБщЕФЙлЕуЪЧЃКЁАYes! ЯТвЛВНвбОгаСЫЁЊЁЊФЧОЭЪЧзЂвтСІЃЁЁБ етИіЯыЗЈЪЧШУ RNN ЕФУПвЛВНЖМДгИќМгДѓЕФаХЯЂМЏжаЬєбЁаХЯЂЁЃР§ШчЃЌШчЙћФуЪЙгУ RNN РДВњЩњвЛИіЭМЦЌЕФУшЪіЃЌПЩФмЛсбЁдёЭМЦЌЕФвЛИіВПЗжЃЌИљОнетВПЗжаХЯЂРДВњЩњЪфГіЕФДЪЁЃЪЕМЪЩЯЃЌXu, et al.(2015)вбОетУДзіСЫЁЊЁЊШчЙћФуЯЃЭћЩюШыЬНЫїзЂвтСІПЩФметОЭЪЧвЛИігаШЄЕФЦ№ЕуЃЁЛЙгавЛаЉЪЙгУзЂвтСІЕФЯрЕБеёЗмШЫаФЕФбаОПГЩЙћЃЌПДЦ№РДгаИќЖрЕФЖЋЮїиНД§ЬНЫїЁЁ
зЂвтСІвВВЛЪЧ RNN баОПСьгђжаЮЈвЛЕФЗЂеЙЗНЯђЁЃР§ШчЃЌKalchbrenner, et al. (2015) ЬсГіЕФ Grid LSTM ПДЦ№РДвВЪЧКмгаЧАЭОЁЃЪЙгУЩњГЩФЃаЭЕФ RNNЃЌжюШчGregor, et al. (2015) Chung, et al. (2015) КЭ Bayer & Osendorfer (2015) ЬсГіЕФФЃаЭЭЌбљКмгаШЄЁЃдкЙ§ШЅМИФъжаЃЌRNN ЕФбаОПвбОЯрЕБЕФШМЃЌЖјбаОПГЩЙћЕБШЛвВЛсИќМгЗсИЛЃЁ
жТаЛ
IЁЏm grateful to a number of people for helping me better understand LSTMs, commenting on the visualizations, and providing feedback on this post.
IЁЏm very grateful to my colleagues at Google for their helpful feedback, especially Oriol Vinyals,Greg Corrado, Jon Shlens, Luke Vilnis, and Ilya Sutskever. IЁЏm also thankful to many other friends and colleagues for taking the time to help me, including Dario Amodei, and Jacob Steinhardt. IЁЏm especially thankful to Kyunghyun Cho for extremely thoughtful correspondence about my diagrams.
Before this post, I practiced explaining LSTMs during two seminar series I taught on neural networks. Thanks to everyone who participated in those for their patience with me, and for their feedback.
From:http://www.jianshu.com/p/9dc9f41f0b29
зїепЃКwangduo
ГіДІЃКhttp://www.cnblogs.com/wangduo/
БОВЉПЭжаЮДБъУїзЊдиЕФЮФеТЙщзїепwangduoКЭВЉПЭдАЙВгаЃЌЛЖгзЊдиЃЌЕЋЮДОзїепЭЌвтБиаыБЃСєДЫЖЮЩљУїЃЌЧвдкЮФеТвГУцУїЯдЮЛжУИјГідЮФСЌНгЃЌЗёдђБЃСєзЗОПЗЈТЩд№ШЮЕФШЈРћЁЃ