һ��LSTM������
1�����ڴ�ͳRNN�����ݶ���ʧ������
https://blog.csdn.net/dchen1993/article/details/53885490
http://www.cnetnews.com.cn/2017/1118/3100705.shtml
�����漰��softmax��������https://blog.csdn.net/u014313009/article/details/51045303
��ͳRNN�����ݶ���ʧ��Ҫ����Ϊ����������ʱ��St��St-1...S1��S0������ϵ����˶���Ҫ�����������ԣ�





�������ʹ�ñ�����ʼw����ô������ε���˶���0-1֮���С�����������f�ĵ���Ҳ��0-1֮������������˺�����ĺ�С�������ݶ���ʧ�������dz�ʼ����w�Ǻܴ������w���Լ�����ĵ���������1����ô���˺��ܻᵼ���Ľ���ܴ��γ��ݶȱ�ը�� https://www.cnblogs.com/pinking/p/9418280.html
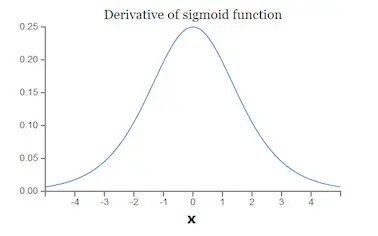

�ݶ���ʧ���ݶȱ�ը��������һ���ģ�������Ϊ�������̫����������ݶȷ����е�����ЧӦ��
RNN�е���ʧ���� ��
https://www.cnblogs.com/wuxiangli/p/7096392.html
https://www.cnblogs.com/puheng/p/9379730.html
2��RNN���ݶ���ʧ�Ľ������
��ReLU�����+���ʵIJ�����ʼ�� ��LSTM��GRU ���ݶȲü���Clipping Gradient��
��ReLU�����+���ʵIJ�����ʼ��
����ReLU��һ���̶��Ͽ��Խ���ݶ���ʧ�����⣬���ǣ�
��Ϊʲôͬ���ķ�����RNN�в���Ч�أ���ʵ��һ��Hinton������IRNN�������棨arxiv��[1504.00941] A Simple Way to Initialize Recurrent Networks of Rectified Linear Units���Ǻ���ȷ���ᵽ�ģ�
Ҳ����˵��RNN��ֱ�ӰѼ��������ReLU�ᵼ�·dz�������ֵ��
һ���棬��tanh����ReLU�����ǰ��ʱ����Ľ�����ɶ��W���ˣ�
�������ReLU�����ͳRNN�еļ���������Ҽ���ReLU����һֱ���ڼ��������������0����
���У�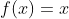 ;
; 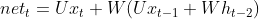 .
.
�������չ����![]() �����ս�����t��W���ɡ����W���ǵ�λ��֤����
�����ս�����t��W���ɡ����W���ǵ�λ��֤����![]() �Ľ�����ս�����0����������������ص���ֵ���⡣
�Ľ�����ս�����0����������������ص���ֵ���⡣
ͬʱ���������ReLU���������һ��ʼ���е���Ԫ�����ڼ���״̬�����ݶȴ�����n��֮���У�
���Կ�����ֻҪW���ǵ�λ�����ݶȻ��ǻ������ʧ���߱�ը�����⡣
����������������ReLU��Ϊ�����ʱ��ֻ�е�W��ȡֵ�ڵ�λ������ʱ����ȡ�ñȽϺõ�Ч����
��LSTM��GRU
LSTM��GRUͨ���ſػ���ʹ�ݶȵij˷�������ӷ���
https://www.cnblogs.com/wuxiangli/p/7096392.html
���ݶȲü�
��Ȼ��BP�����л�����ݶ���ʧ������ƫ�����ӽ�0�����³�ʱ���������£�����ô��ֱ��ķ������趨��ֵ�����ݶ�С����ֵʱ�����µ��ݶ�Ϊ��ֵ������ͼ��ʾ�� 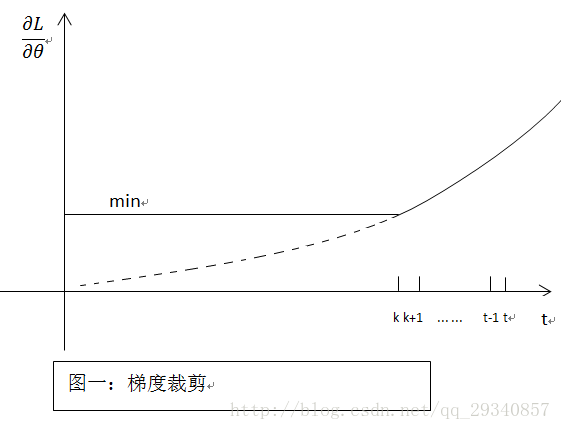
�ŵ㣺�ֱ�
ȱ�㣺�����ҵ��������ֵ
���ϵ��ݶȲü��ķ���һ������������ݶȱ�ը����ģ����ڽ���ݶ���ʧ������д����ġ�����
3��LSTM������Ϊʲô���Խ����ͳRNN�����ݶ���ʧ������
LSTM��GRUͨ���ſػ���ʹ�ݶȷ���ʱ�ɳ˷�������ӷ���
https://zhuanlan.zhihu.com/p/28749444 ����д�ĺܺã�
https://www.cnblogs.com/wuxiangli/p/7096392.html ��ƪ���¶�RNN�еĺܶ����ⶼ��������ϸ�Ľ��ܡ�ֵ��һ��
4��LSTM�������GRU��ϵ������
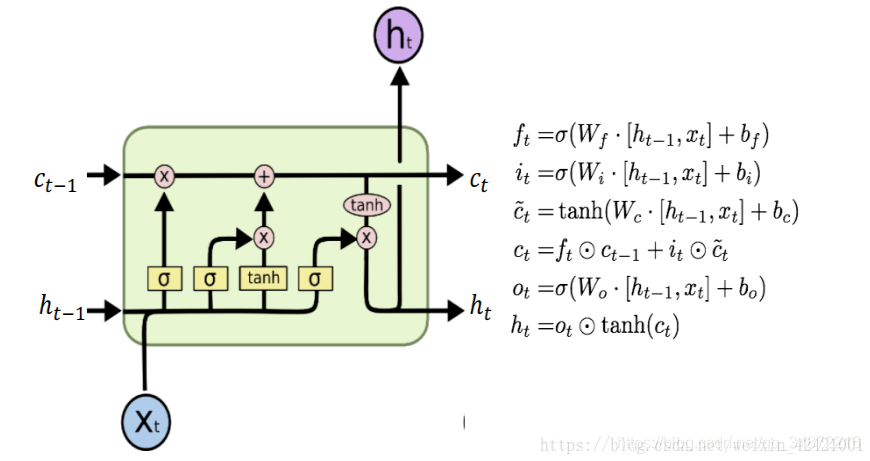
�����ţ�
���ö�����һ��ʱ�䲽�ļ��䵥ԪCt-1
���ã�����һ��ʱ�䲽�ļ��䵥Ԫ�е���Ϣѡ���Ե�����
�����ţ�
���ö���ǰ����õ�����״̬
���ã����µ���Ϣѡ���Եļ�¼��ϸ��״̬��
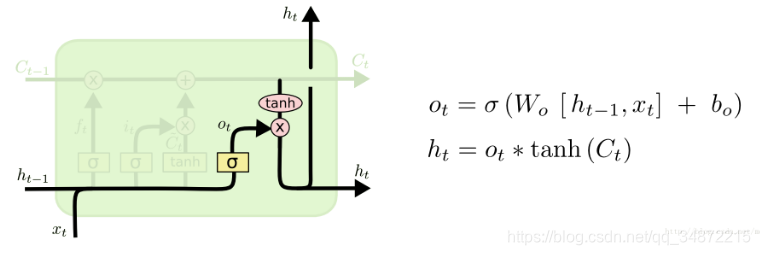
����ţ�
���ö���ǰ�ļ��䵥ԪCt
������������Ƶ�ǰ�ļ��䵥ԪCt �ж��ٱ����˵���
GRU����LSTM�����ſأ�����ȻҲ���ţ�����ֻ���������ֱ���������ţ�reset gate�����������ţ�update gate���������Ź���˼�壬�������Ƿ����ã�Ҳ����˵���̶��ϲ�����ǰ��״̬state�����������ʾ�����̶���Ҫ��candidate �����µ�ǰ��hidden layer����������һ��ʾ��ͼ���Լ����Ĺ�ʽ��
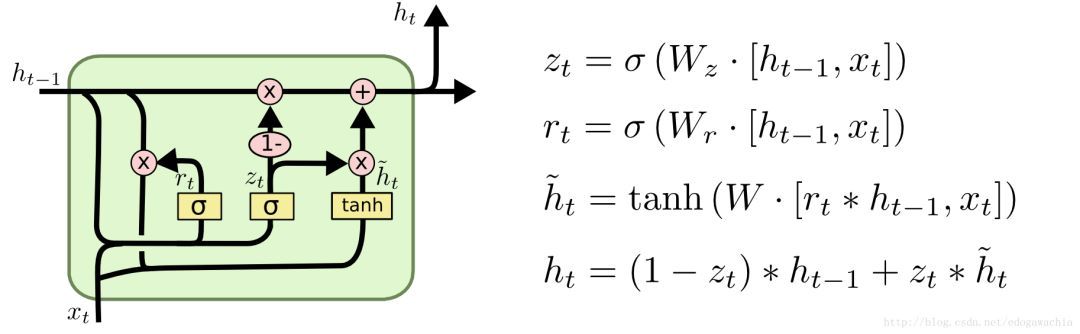
�����ͼ�Ĺ�ʽ������r��z���������ţ��ֱ��ʾreset��update������ͼ�Ĺ�ʽ������Learning Phrase Representations using RNN Encoder�CDecoder for Statistical Machine Translation �еĹ�ʽ���г��룬����ͼ��������Ϊ��ͼ���ã���Ϊ���Ͻ�updateԽ��Ӧ�ø��µ����ݣ�Ҳ����ѡ���candidate������Խ�ࣩ
GRU�Ļ���ԭ���ǣ����ȣ���x(t)��h(t-1)���������ţ�Ȼ����reset�ų�����һʱ�̵�״̬�������Ƿ�Ҫreset����reset���̶ȣ�Ȼ���������xƴ�ӣ������粢��tanh����γ�candidate����������hat{h_t}��Ȼ����һʱ�̵�h��candidate��h��һ��������ϣ����ߵ�Ȩ�غ�Ϊ1��candidate��Ȩ�ؾ���update�ŵ��������������ǿ�ȶ��
Ҫע����ǣ�hֻ��һ�������������ÿ��ʱ�̣���������������ϣ�h����������ǰ���Լ�����ǰ�ı�ѡ�������Լ���������˵����һ�������ñ�һ���ƣ�ÿ������Ҫ��һ���־Ƶ���ȥ�����ѵ���ȥ�ľƺ��¼����ԭ�ϻ�ϣ�Ȼ���ڵ������������reset���Ƶľ���Ҫ����ȥ�ģ����һ�Ϻ�֮���ٵ������ľƵı�������update���Ƶ������ö��ı��������ԭ�Ϻ͵�������֮ǰ���ƺõľơ�ͬ����Ҳ�����Դ�����LSTM��LSTM�������Ź����Ϻ�reset���ƣ�����������update���ƣ���֮ͬ������LSTM�������˵�ǰ״̬��exposure��Ҳ��������ŵĹ��ܣ�����GRU��û�еġ�
GRU�����٣���ѵ�����ṹ��Լ�һЩ��������ͼչʾ��GRU��ʽ�����reset = 1��update = 1����ô�ͱ����һ��plain RNN��ʵ���ϣ��в��Ա�����RNN���ֱ���֮����������������ͬ��
��lstm��ȣ���ֱ�������ǿ��Կ������š���������Ϊ�����������г�Ϊ�����ź����š�ͬʱ��Ҳ����ct���״̬������
gru��ͨ��1-zt����ht-1ѡ���ס���ֹ�ȥ��Ϣ��ͨ��zt����ht(~)ѡ���ס���ֵ�ǰ��Ϣ�����Ϊ��ǰstep�������Ϣ����lstm�ĺ���ԭ����ͬ��gruҲ��ѡ���סһ�������Ĺ�ȥ����Ϣ��һ�����������ڵ���Ϣ�����ڱ�����ѡ���ϳ��ֲ�����lstm�Թ�ȥ�����ڵ���Ϣѡ����ͬ�ı����������gru�Թ�ȥ�����ڵ���Ϣ����ı�����Ϊ1��������Ĺ�ȥ��Ϣ��������Ϣ��һ��Ȩ�ص����á�
������������gru�ڼ��㵱ǰstate��Ϣʱ�Թ�ȥ��Ϣ��һ��ѡ���ԣ�����ǰ��Ϣ�IJ����Ƿ��ܹ�ȥ��Ϣ��Ӱ�졣