����Ŀ¼
- ѭ��������
- �ſ�ѭ����Ԫ��GRU��
-
- �ſ�ѭ����Ԫ
- �����ź�����
- ��ѡ����״̬
- ����״̬
- ������
- �����ڼ��䣨LSTM��
-
- �����š������ź������
- ��ѡ����ϸ��
- ����ϸ��
- ����״̬
- ������
- ���ѭ��������
- ˫��ѭ��������
ѭ��������
��ѭ�������������������Ǵ���ʱ������Եģ�Ҳ����˵��ǰһ��ʱ�������ݻ�Ժ�һʱ�������ݲ���Ӱ�졣���� Xt��Rn��d\boldsymbol{X}_t \in \mathbb{R}^{n \times d}Xt?��Rn��d ��������ʱ�䲽 ttt ��С�������룬Ht��Rn��h\boldsymbol{H}_t \in \mathbb{R}^{n \times h}Ht?��Rn��h �Ǹ�ʱ�䲽�����ر����������֪����ͬ���ǣ��������DZ�����һʱ�䲽�����ر��� Ht?1\boldsymbol{H}_{t-1}Ht?1?��������һ���µ�Ȩ�ز��� Whh��Rh��h\boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h}Whh?��Rh��h���ò������������ڵ�ǰʱ�䲽���ʹ����һʱ�䲽�����ر�����������˵��ʱ�䲽 ttt �����ر����ļ����ɵ�ǰʱ�䲽���������һʱ�䲽�����ر�����ͬ������
Ht=?(XtWxh+Ht?1Whh+bh).\boldsymbol{H}_t = \phi(\boldsymbol{X}_t \boldsymbol{W}_{xh} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hh} + \boldsymbol{b}_h).Ht?=?(Xt?Wxh?+Ht?1?Whh?+bh?).
�����֪����ȣ����������������� Ht?1Whh\boldsymbol{H}_{t-1} \boldsymbol{W}_{hh}Ht?1?Whh? һ�����ʽ������ʱ�䲽�����ر��� Ht\boldsymbol{H}_tHt? �� Ht?1\boldsymbol{H}_{t-1}Ht?1? ֮��Ĺ�ϵ��֪����������ر����ܹ���������ǰʱ�䲽�����е���ʷ��Ϣ�������������統ǰʱ�䲽��״̬�����һ������ˣ������ر���Ҳ��Ϊ����״̬������״̬�� XtWxh+Ht?1Whh\boldsymbol{X}_t \boldsymbol{W}_{xh} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hh}Xt?Wxh?+Ht?1?Whh? �ļ���ȼ��� Xt\boldsymbol{X}_tXt?��Ht?1\boldsymbol{H}_{t-1}Ht?1? �����ľ������Wxh\boldsymbol{W}_{xh}Wxh?��Whh\boldsymbol{W}_{hh}Whh?�����ľ�����������״̬�ڵ�ǰʱ�䲽�Ķ���ʹ������һʱ�䲽������״̬����ʽ�ļ�����ѭ���ġ�ʹ��ѭ����������缴ѭ�������磨recurrent neural network����
ѭ���������кܶ��ֲ�ͬ�Ĺ��췽��������ʽ�����������״̬��ѭ���������Ǽ�Ϊ������һ�֡���ʱ�䲽 ttt������������Ͷ���֪���еļ������ƣ�
Ot=HtWhq+bq.\boldsymbol{O}_t = \boldsymbol{H}_t \boldsymbol{W}_{hq} + \boldsymbol{b}_q.Ot?=Ht?Whq?+bq?.
ѭ��������IJ����������ز��Ȩ�� Wxh��Rd��h\boldsymbol{W}_{xh} \in \mathbb{R}^{d \times h}Wxh?��Rd��h��Whh��Rh��h\boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h}Whh?��Rh��h ��ƫ�� bh��R1��h\boldsymbol{b}_h \in \mathbb{R}^{1 \times h}bh?��R1��h���Լ�������Ȩ�� Whq��Rh��q\boldsymbol{W}_{hq} \in \mathbb{R}^{h \times q}Whq?��Rh��q ��ƫ�� bq��R1��q\boldsymbol{b}_q \in \mathbb{R}^{1 \times q}bq?��R1��q��ֵ��һ����ǣ������ڲ�ͬʱ�䲽��ѭ��������Ҳʼ��ʹ����Щģ�Ͳ�������ˣ�ѭ��������ģ�Ͳ�������������ʱ�䲽�����Ӷ�������
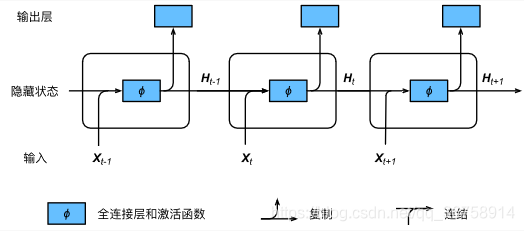
��ͼչʾ��ѭ����������3������ʱ�䲽�ļ���������ʱ�䲽 ttt������״̬�ļ�����Կ����ǽ����� Xt\boldsymbol{X}_tXt? ��ǰһʱ�䲽����״̬ Ht?1\boldsymbol{H}_{t-1}Ht?1? ���������һ�������Ϊ ?\phi? ��ȫ���Ӳ㡣��ȫ���Ӳ��������ǵ�ǰʱ�䲽������״̬ Ht\boldsymbol{H}_tHt?����ģ�Ͳ���Ϊ Wxh\boldsymbol{W}_{xh}Wxh? �� Whh\boldsymbol{W}_{hh}Whh? �����ᣬƫ��Ϊ bh\boldsymbol{b}_hbh?����ǰʱ�䲽 ttt ������״̬ Ht\boldsymbol{H}_tHt? ��������һ��ʱ�䲽 t+1t+1t+1 ������״̬ Ht+1\boldsymbol{H}_{t+1}Ht+1? �ļ��㣬�����뵽��ǰʱ�䲽��ȫ��������㡣
�ſ�ѭ����Ԫ��GRU��
ѭ�������������ͨ��ʱ�䷴����һ���н�����ѭ���������е��ݶȼ��㷽�������Ƿ��֣���ʱ�䲽���ϴ����ʱ�䲽��Сʱ��ѭ����������ݶȽ����׳���˥����ը����Ȼ�ü��ݶȿ���Ӧ���ݶȱ�ը����������ݶ�˥�������⡣ͨ���������ԭ��ѭ����������ʵ���н��Ѳ�ʱ��������ʱ�䲽����ϴ��������ϵ��
�ſ�ѭ����Ԫ
�ſ�ѭ�������磨gated recurrent neural network�������������Ϊ�˸��õز�ʱ��������ʱ�䲽����ϴ��������ϵ����ͨ������ѧϰ������������Ϣ�����������У��ſ�ѭ����Ԫ��gated recurrent unit��GRU����һ�ֳ��õ��ſ�ѭ�������硣
�����ź�����
����ͼ��ʾ���ſ�ѭ����Ԫ�е������ź����ŵ������Ϊ��ǰʱ�䲽���� Xt\boldsymbol{X}_tXt? ����һʱ�䲽����״̬ Ht?1\boldsymbol{H}_{t-1}Ht?1?������ɼ����Ϊ sigmoid ������ȫ���Ӳ����õ���
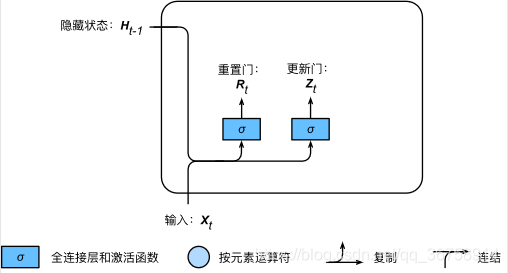 ������˵������������Ϊ nnn���������Ϊ ddd����ÿ������������Ԫ������һ��Ϊ�ʵ��С�������ص�Ԫ����Ϊ hhh������ʱ�䲽 ttt ��С�������� Xt��Rn��d\boldsymbol{X}_t \in \mathbb{R}^{n \times d}Xt?��Rn��d ����һʱ�䲽����״̬ Ht?1��Rn��h\boldsymbol{H}_{t-1} \in \mathbb{R}^{n \times h}Ht?1?��Rn��h�������� Rt��Rn��h\boldsymbol{R}_t \in \mathbb{R}^{n \times h}Rt?��Rn��h ������ Zt��Rn��h\boldsymbol{Z}_t \in \mathbb{R}^{n \times h}Zt?��Rn��h �ļ������£�
������˵������������Ϊ nnn���������Ϊ ddd����ÿ������������Ԫ������һ��Ϊ�ʵ��С�������ص�Ԫ����Ϊ hhh������ʱ�䲽 ttt ��С�������� Xt��Rn��d\boldsymbol{X}_t \in \mathbb{R}^{n \times d}Xt?��Rn��d ����һʱ�䲽����״̬ Ht?1��Rn��h\boldsymbol{H}_{t-1} \in \mathbb{R}^{n \times h}Ht?1?��Rn��h�������� Rt��Rn��h\boldsymbol{R}_t \in \mathbb{R}^{n \times h}Rt?��Rn��h ������ Zt��Rn��h\boldsymbol{Z}_t \in \mathbb{R}^{n \times h}Zt?��Rn��h �ļ������£�
Rt=��(XtWxr+Ht?1Whr+br)\boldsymbol{R}_t = \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xr} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hr} + \boldsymbol{b}_r)Rt?=��(Xt?Wxr?+Ht?1?Whr?+br?)
Zt=��(XtWxz+Ht?1Whz+bz)\boldsymbol{Z}_t = \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xz} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hz} + \boldsymbol{b}_z)Zt?=��(Xt?Wxz?+Ht?1?Whz?+bz?)
���� Wxr,Wxz��Rd��h\boldsymbol{W}_{xr}, \boldsymbol{W}_{xz} \in \mathbb{R}^{d \times h}Wxr?,Wxz?��Rd��h �� Whr,Whz��Rh��h\boldsymbol{W}_{hr}, \boldsymbol{W}_{hz} \in \mathbb{R}^{h \times h}Whr?,Whz?��Rh��h ��Ȩ�ز�����br,bz��R1��h\boldsymbol{b}_r, \boldsymbol{b}_z \in \mathbb{R}^{1 \times h}br?,bz?��R1��h ��ƫ�������sigmoid �������Խ�Ԫ�ص�ֵ�任��0��1֮�䡣��ˣ������� Rt\boldsymbol{R}_tRt? ������ Zt\boldsymbol{Z}_tZt? ��ÿ��Ԫ�ص�ֵ����[0,1][0, 1][0,1]��
��ѡ����״̬
���������ſ�ѭ����Ԫ�������ѡ����״̬�������Ժ������״̬���㡣����ͼ��ʾ�����ǽ���ǰʱ�䲽�����ŵ��������һʱ�䲽����״̬����Ԫ�س˷�������Ϊ��\odot�����������������Ԫ��ֵ�ӽ�0����ô��ζ�����ö�Ӧ����״̬Ԫ��Ϊ0����������һʱ�䲽������״̬�����Ԫ��ֵ�ӽ�1����ô��ʾ������һʱ�䲽������״̬��Ȼ����Ԫ�س˷��Ľ���뵱ǰʱ�䲽���������ᣬ��ͨ��������� tanh ��ȫ���Ӳ�������ѡ����״̬��������Ԫ�ص�ֵ��Ϊ[?1,1][-1, 1][?1,1]��

������˵��ʱ�䲽 ttt �ĺ�ѡ����״̬ H~t��Rn��h\tilde{\boldsymbol{H}}_t \in \mathbb{R}^{n \times h}H~t?��Rn��h �ļ���Ϊ��
H~t=tanh(XtWxh+(Rt��Ht?1)Whh+bh)\tilde{\boldsymbol{H}}_t = \text{tanh}(\boldsymbol{X}_t \boldsymbol{W}_{xh} + \left(\boldsymbol{R}_t \odot \boldsymbol{H}_{t-1}\right) \boldsymbol{W}_{hh} + \boldsymbol{b}_h)H~t?=tanh(Xt?Wxh?+(Rt?��Ht?1?)Whh?+bh?)
���� Wxh��Rd��h\boldsymbol{W}_{xh} \in \mathbb{R}^{d \times h}Wxh?��Rd��h �� Whh��Rh��h\boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h}Whh?��Rh��h ��Ȩ�ز�����bh��R1��h\boldsymbol{b}_h \in \mathbb{R}^{1 \times h}bh?��R1��h ��ƫ������������������ʽ���Կ����������ſ�������һʱ�䲽������״̬������뵱ǰʱ�䲽�ĺ�ѡ����״̬������һʱ�䲽������״̬���ܰ�����ʱ�����н�����һʱ�䲽��ȫ����ʷ��Ϣ����ˣ������ſ�������������Ԥ���ص���ʷ��Ϣ�Ӷ������ڲ�ʱ����������ڵ�������ϵ
����״̬
���ʱ�䲽 ttt ������״̬ Ht��Rn��h\boldsymbol{H}_t \in \mathbb{R}^{n \times h}Ht?��Rn��h �ļ���ʹ�õ�ǰʱ�䲽�ĸ����� Zt\boldsymbol{Z}_tZt? ������һʱ�䲽������״̬ Ht?1\boldsymbol{H}_{t-1}Ht?1? �͵�ǰʱ�䲽�ĺ�ѡ����״̬ H~t\tilde{\boldsymbol{H}}_tH~t? ����ϣ�
Ht=Zt��Ht?1+(1?Zt)��H~t\boldsymbol{H}_t = \boldsymbol{Z}_t \odot \boldsymbol{H}_{t-1} + (1 - \boldsymbol{Z}_t) \odot \tilde{\boldsymbol{H}}_tHt?=Zt?��Ht?1?+(1?Zt?)��H~t?
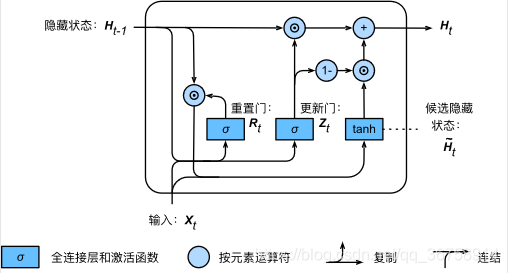 ֵ��ע����ǣ������ſ��Կ�������״̬Ӧ����α�������ǰʱ�䲽��Ϣ�ĺ�ѡ����״̬�����£�����ͼ��ʾ�������������ʱ�䲽 t��t't�� �� ttt��t��<tt' < tt��<t��֮��һֱ������1����ô����ʱ�䲽 t��t't�� �� ttt ֮���������Ϣ����û������ʱ�䲽 ttt ������״̬ Ht\boldsymbol{H}_tHt?��ʵ���ϣ�����Կ����ǽ���ʱ�̵�����״̬ Ht��?1\boldsymbol{H}_{t'-1}Ht��?1? һֱͨ��ʱ�䱣�沢��������ǰʱ�䲽 ttt�������ƿ���Ӧ��ѭ���������е��ݶ�˥�����⣬�����õز�ʱ��������ʱ�䲽����ϴ��������ϵ�������ڵ�������ϵ����
ֵ��ע����ǣ������ſ��Կ�������״̬Ӧ����α�������ǰʱ�䲽��Ϣ�ĺ�ѡ����״̬�����£�����ͼ��ʾ�������������ʱ�䲽 t��t't�� �� ttt��t��<tt' < tt��<t��֮��һֱ������1����ô����ʱ�䲽 t��t't�� �� ttt ֮���������Ϣ����û������ʱ�䲽 ttt ������״̬ Ht\boldsymbol{H}_tHt?��ʵ���ϣ�����Կ����ǽ���ʱ�̵�����״̬ Ht��?1\boldsymbol{H}_{t'-1}Ht��?1? һֱͨ��ʱ�䱣�沢��������ǰʱ�䲽 ttt�������ƿ���Ӧ��ѭ���������е��ݶ�˥�����⣬�����õز�ʱ��������ʱ�䲽����ϴ��������ϵ�������ڵ�������ϵ����
������
������õ�������״̬ HtH_tHt? ���������磬�õ���� Yt��Rn��q\boldsymbol{Y}_t \in \mathbb{R}^{n \times q}Yt?��Rn��q��
Yt=HtWhq+bq\boldsymbol{Y}_t = \boldsymbol{H}_t \boldsymbol{W}_{hq} + \boldsymbol{b}_qYt?=Ht?Whq?+bq?
�ܽ���˵��
- �����������ڲ�ʱ����������ڵ�������ϵ��
- �����������ڲ�ʱ�������ﳤ�ڵ�������ϵ��
�����ڼ��䣨LSTM��
LSTM ��������3���ţ��������ţ�input gate���������ţ�forget gate��������ţ�output gate�����Լ�������״̬��״��ͬ�ļ���ϸ����ijЩ���װѼ���ϸ������һ�����������״̬�����Ӷ���¼�������Ϣ��
�����š������ź������
���ſ�ѭ����Ԫ�е������ź�����һ��������ͼ��ʾ�������ڼ�����ŵ������Ϊ��ǰʱ�䲽����Xt\boldsymbol{X}_tXt? ����һʱ�䲽����״̬ Ht?1\boldsymbol{H}_{t-1}Ht?1?������ɼ����Ϊ sigmoid ������ȫ���Ӳ����õ������һ������3����Ԫ�ص�ֵ���Ϊ[0,1][0,1][0,1]��
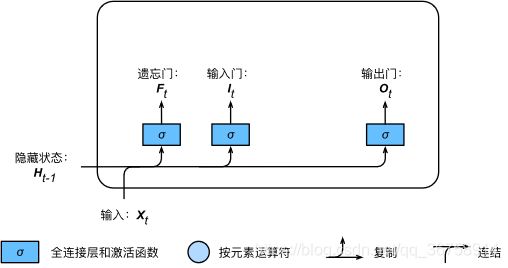
������˵������������Ϊ nnn���������Ϊ ddd�����ص�Ԫ����Ϊ hhh������ʱ�䲽 ttt ��С�������� Xt��Rn��d\boldsymbol{X}_t \in \mathbb{R}^{n \times d}Xt?��Rn��d ����һʱ�䲽����״̬ Ht?1��Rn��h\boldsymbol{H}_{t-1} \in \mathbb{R}^{n \times h}Ht?1?��Rn��h�� ʱ�䲽 ttt �������� It��Rn��h\boldsymbol{I}_t \in \mathbb{R}^{n \times h}It?��Rn��h�������� Ft��Rn��h\boldsymbol{F}_t \in \mathbb{R}^{n \times h}Ft?��Rn��h ������� Ot��Rn��h\boldsymbol{O}_t \in \mathbb{R}^{n \times h}Ot?��Rn��h �ֱ�������£�
It=��(XtWxi+Ht?1Whi+bi)\boldsymbol{I}_t = \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xi} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hi} + \boldsymbol{b}_i)It?=��(Xt?Wxi?+Ht?1?Whi?+bi?)
Ft=��(XtWxf+Ht?1Whf+bf)\boldsymbol{F}_t = \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xf} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hf} + \boldsymbol{b}_f)Ft?=��(Xt?Wxf?+Ht?1?Whf?+bf?)
Ot=��(XtWxo+Ht?1Who+bo)\boldsymbol{O}_t = \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xo} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{ho} + \boldsymbol{b}_o)Ot?=��(Xt?Wxo?+Ht?1?Who?+bo?)
���е� Wxi,Wxf,Wxo��Rd��h\boldsymbol{W}_{xi}, \boldsymbol{W}_{xf}, \boldsymbol{W}_{xo} \in \mathbb{R}^{d \times h}Wxi?,Wxf?,Wxo?��Rd��h �� Whi,Whf,Who��Rh��h\boldsymbol{W}_{hi}, \boldsymbol{W}_{hf}, \boldsymbol{W}_{ho} \in \mathbb{R}^{h \times h}Whi?,Whf?,Who?��Rh��h ��Ȩ�ز�����bi,bf,bo��R1��h\boldsymbol{b}_i, \boldsymbol{b}_f, \boldsymbol{b}_o \in \mathbb{R}^{1 \times h}bi?,bf?,bo?��R1��h ��ƫ�������
��ѡ����ϸ��
�������������ڼ�����Ҫ�����ѡ����ϸ�� C~t\tilde{\boldsymbol{C}}_tC~t?�����ļ�����������ܵ�3�������ƣ���ʹ����ֵ����[?1,1][-1, 1][?1,1]�� tanh ������Ϊ�����������ͼ��ʾ��
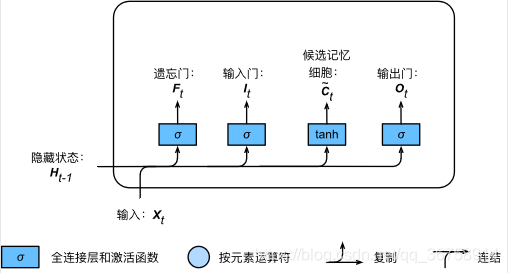
������˵��ʱ�䲽 ttt �ĺ�ѡ����ϸ�� C~t��Rn��h\tilde{\boldsymbol{C}}_t \in \mathbb{R}^{n \times h}C~t?��Rn��h �ļ���Ϊ
C~t=tanh(XtWxc+Ht?1Whc+bc)\tilde{\boldsymbol{C}}_t = \text{tanh}(\boldsymbol{X}_t \boldsymbol{W}_{xc} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hc} + \boldsymbol{b}_c)C~t?=tanh(Xt?Wxc?+Ht?1?Whc?+bc?)
���� Wxc��Rd��h\boldsymbol{W}_{xc} \in \mathbb{R}^{d \times h}Wxc?��Rd��h �� Whc��Rh��h\boldsymbol{W}_{hc} \in \mathbb{R}^{h \times h}Whc?��Rh��h ��Ȩ�ز�����bc��R1��h\boldsymbol{b}_c \in \mathbb{R}^{1 \times h}bc?��R1��h ��ƫ�������
����ϸ��
���ǿ���ͨ��Ԫ��ֵ����[0,1][0, 1][0,1]�������š������ź����������������״̬����Ϣ����������һ��Ҳ��ͨ��ʹ�ð�Ԫ�س˷�������Ϊ��\odot������ʵ�ֵġ���ǰʱ�䲽����ϸ�� Ct��Rn��h\boldsymbol{C}_t \in \mathbb{R}^{n \times h}Ct?��Rn��h �ļ����������һʱ�䲽����ϸ���͵�ǰʱ�䲽��ѡ����ϸ������Ϣ����ͨ�������ź���������������Ϣ��������
Ct=Ft��Ct?1+It��C~t.\boldsymbol{C}_t = \boldsymbol{F}_t \odot \boldsymbol{C}_{t-1} + \boldsymbol{I}_t \odot \tilde{\boldsymbol{C}}_t.Ct?=Ft?��Ct?1?+It?��C~t?.
����ͼ��ʾ�������ſ�����һʱ�䲽�ļ���ϸ�� Ct?1\boldsymbol{C}_{t-1}Ct?1? �е���Ϣ�Ƿݵ���ǰʱ�䲽��������������Ƶ�ǰʱ�䲽������ Xt\boldsymbol{X}_tXt? ͨ����ѡ����ϸ�� C~t\tilde{\boldsymbol{C}}_tC~t? ������뵱ǰʱ�䲽�ļ���ϸ�������������һֱ����1��������һֱ����0����ȥ�ļ���ϸ����һֱͨ��ʱ�䱣�沢��������ǰʱ�䲽�������ƿ���Ӧ��ѭ���������е��ݶ�˥�����⣬�����õز�ʱ��������ʱ�䲽����ϴ��������ϵ��
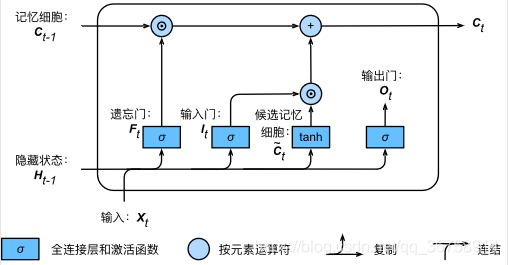
����״̬
���˼���ϸ���Ժ��������ǻ�����ͨ������������ƴӼ���ϸ��������״̬ Ht��Rn��h\boldsymbol{H}_t \in \mathbb{R}^{n \times h}Ht?��Rn��h ����Ϣ��������
Ht=Ot��tanh(Ct).\boldsymbol{H}_t = \boldsymbol{O}_t \odot \text{tanh}(\boldsymbol{C}_t).Ht?=Ot?��tanh(Ct?).
����� tanh ����ȷ������״̬Ԫ��ֵ��-1��1֮�䡣��Ҫע����ǣ�������Ž���1ʱ������ϸ����Ϣ�����ݵ�����״̬�������ʹ�ã�������Ž���0ʱ������ϸ����Ϣֻ�Լ���������ͼչʾ�˳����ڼ���������״̬�ļ��㡣
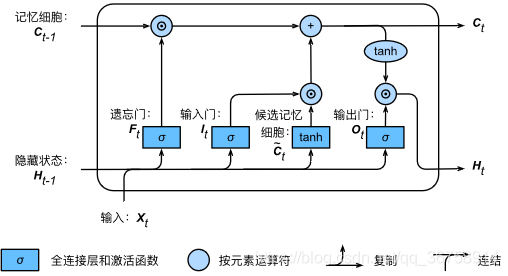
������
�����ڼ�������ز������������״̬�ͼ���ϸ������ֻ������״̬�ᴫ�ݵ�����㣬������ϸ�������������ļ��㡣
������õ�������״̬ HtH_tHt? ���������磬�õ���� Yt��Rn��q\boldsymbol{Y}_t \in \mathbb{R}^{n \times q}Yt?��Rn��q��
Yt=HtWhq+bq\boldsymbol{Y}_t = \boldsymbol{H}_t \boldsymbol{W}_{hq} + \boldsymbol{b}_qYt?=Ht?Whq?+bq?
���ѭ��������
��ĿǰΪֹ���漰��ѭ��������ֻ��һ����������ز㣬�����ѧϰӦ�������ͨ�����õ����ж�����ز��ѭ�������磬Ҳ�������ѭ�������硣��ͼ��ʾ��һ���� LLL �����ز�����ѭ�������磬ÿ������״̬���ϴ�������ǰ�����һʱ�䲽�͵�ǰʱ�䲽����һ�㡣��֮ǰ�Ľ����У�����ֻ��������㡢��һ�����ز������㡣
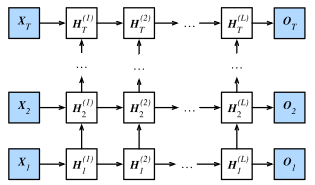
������˵����ʱ�䲽 ttt ���С�������� Xt��Rn��d\boldsymbol{X}_t \in \mathbb{R}^{n \times d}Xt?��Rn��d��������Ϊ nnn���������Ϊ ddd ������ ?\ell? ���ز㣨 ?=1,��,L\ell=1,\ldots,L?=1,��,L ��������״̬Ϊ Ht(?)��Rn��h\boldsymbol{H}_t^{(\ell)} \in \mathbb{R}^{n \times h}Ht(?)?��Rn��h�����ص�Ԫ����Ϊ hhh ������������Ϊ Ot��Rn��q\boldsymbol{O}_t \in \mathbb{R}^{n \times q}Ot?��Rn��q���������Ϊ qqq ���������ز�ļ����Ϊ ?\phi?����һ�����ز������״̬��֮ǰ�ļ���һ����
Ht(1)=?(XtWxh(1)+Ht?1(1)Whh(1)+bh(1)),\boldsymbol{H}_t^{(1)} = \phi(\boldsymbol{X}_t \boldsymbol{W}_{xh}^{(1)} + \boldsymbol{H}_{t-1}^{(1)} \boldsymbol{W}_{hh}^{(1)} + \boldsymbol{b}_h^{(1)}),Ht(1)?=?(Xt?Wxh(1)?+Ht?1(1)?Whh(1)?+bh(1)?),
����Ȩ�� Wxh(1)��Rd��h\boldsymbol{W}_{xh}^{(1)} \in \mathbb{R}^{d \times h}Wxh(1)?��Rd��h��Whh(1)��Rh��h\boldsymbol{W}_{hh}^{(1)} \in \mathbb{R}^{h \times h}Whh(1)?��Rh��h ��ƫ�� bh(1)��R1��h\boldsymbol{b}_h^{(1)} \in \mathbb{R}^{1 \times h}bh(1)?��R1��h �ֱ�Ϊ��һ�����ز��ģ�Ͳ�����
�� 1<?��L1 < \ell \leq L1<?��L ʱ���� ?\ell? ���ز������״̬�ı���ʽΪ
Ht(?)=?(Ht(??1)Wxh(?)+Ht?1(?)Whh(?)+bh(?)),\boldsymbol{H}_t^{(\ell)} = \phi(\boldsymbol{H}_t^{(\ell-1)} \boldsymbol{W}_{xh}^{(\ell)} + \boldsymbol{H}_{t-1}^{(\ell)} \boldsymbol{W}_{hh}^{(\ell)} + \boldsymbol{b}_h^{(\ell)}),Ht(?)?=?(Ht(??1)?Wxh(?)?+Ht?1(?)?Whh(?)?+bh(?)?),
����Ȩ�� Wxh(?)��Rh��h\boldsymbol{W}_{xh}^{(\ell)} \in \mathbb{R}^{h \times h}Wxh(?)?��Rh��h��Whh(?)��Rh��h\boldsymbol{W}_{hh}^{(\ell)} \in \mathbb{R}^{h \times h}Whh(?)?��Rh��h ��ƫ�� bh(?)��R1��h\boldsymbol{b}_h^{(\ell)} \in \mathbb{R}^{1 \times h}bh(?)?��R1��h �ֱ�Ϊ�� ?\ell? ���ز��ģ�Ͳ�����
���գ����������ֻ����ڵ� LLL ���ز������״̬��
Ot=Ht(L)Whq+bq,\boldsymbol{O}_t = \boldsymbol{H}_t^{(L)} \boldsymbol{W}_{hq} + \boldsymbol{b}_q,Ot?=Ht(L)?Whq?+bq?,
����Ȩ�� Whq��Rh��q\boldsymbol{W}_{hq} \in \mathbb{R}^{h \times q}Whq?��Rh��q ��ƫ�� bq��R1��q\boldsymbol{b}_q \in \mathbb{R}^{1 \times q}bq?��R1��q Ϊ������ģ�Ͳ�����
ͬ����֪��һ�������ز���� LLL �����ص�Ԫ���� hhh ���dz����������⣬���������״̬�ļ��㻻���ſ�ѭ����Ԫ���߳����ڼ���ļ��㣬���ǿ��Եõ�����ſ�ѭ�������硣
˫��ѭ��������
֮ǰ���ܵ�ѭ��������ģ�Ͷ��Ǽ��赱ǰʱ�䲽����ǰ��Ľ���ʱ�䲽�����о����ģ�������Ƕ�����Ϣͨ������״̬��ǰ���ݡ���ʱ��ǰʱ�䲽Ҳ�����ɺ���ʱ�䲽���������磬������д��һ������ʱ�����ܻ���ݾ��Ӻ���Ĵ����ľ���ǰ����ôʡ�˫��ѭ��������ͨ�����ӴӺ���ǰ������Ϣ�����ز��������ش���������Ϣ����ͼ��ʾ��һ���������ز��˫��ѭ��������ļܹ���
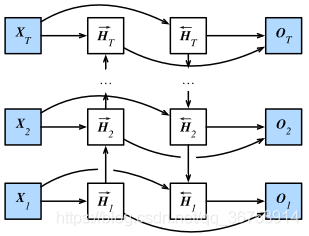
�������������ܾ���Ķ��塣 ����ʱ�䲽 ttt ��С�������� Xt��Rn��d\boldsymbol{X}_t \in \mathbb{R}^{n \times d}Xt?��Rn��d��������Ϊ nnn���������Ϊ ddd �������ز㼤���Ϊ ?\phi?����˫��ѭ��������ļܹ��У� ���ʱ�䲽��������״̬ΪH��t��Rn��h\overrightarrow{\boldsymbol{H}}_t \in \mathbb{R}^{n \times h}Ht?��Rn��h���������ص�Ԫ����Ϊ hhh ���� ��������״̬Ϊ H��t��Rn��h\overleftarrow{\boldsymbol{H}}_t \in \mathbb{R}^{n \times h}Ht?��Rn��h���������ص�Ԫ����Ϊ hhh �������ǿ��Էֱ������������״̬�ͷ�������״̬��
H��t=?(XtWxh(f)+H��t?1Whh(f)+bh(f)),H��t=?(XtWxh(b)+H��t+1Whh(b)+bh(b))\begin{aligned} \overrightarrow{\boldsymbol{H}}_t &= \phi(\boldsymbol{X}_t \boldsymbol{W}_{xh}^{(f)} + \overrightarrow{\boldsymbol{H}}_{t-1} \boldsymbol{W}_{hh}^{(f)} + \boldsymbol{b}_h^{(f)}),\ \overleftarrow{\boldsymbol{H}}_t &= \phi(\boldsymbol{X}_t \boldsymbol{W}_{xh}^{(b)} + \overleftarrow{\boldsymbol{H}}_{t+1} \boldsymbol{W}_{hh}^{(b)} + \boldsymbol{b}_h^{(b)}) \end{aligned} Ht??=?(Xt?Wxh(f)?+Ht?1?Whh(f)?+bh(f)?), Ht??=?(Xt?Wxh(b)?+Ht+1?Whh(b)?+bh(b)?)?
����Ȩ�� Wxh(f)��Rd��h\boldsymbol{W}_{xh}^{(f)} \in \mathbb{R}^{d \times h}Wxh(f)?��Rd��h��Whh(f)��Rh��h\boldsymbol{W}_{hh}^{(f)} \in \mathbb{R}^{h \times h}Whh(f)?��Rh��h��Wxh(b)��Rd��h\boldsymbol{W}_{xh}^{(b)} \in \mathbb{R}^{d \times h}Wxh(b)?��Rd��h��Whh(b)��Rh��h\boldsymbol{W}_{hh}^{(b)} \in \mathbb{R}^{h \times h}Whh(b)?��Rh��h ��ƫ�� bh(f)��R1��h\boldsymbol{b}_h^{(f)} \in \mathbb{R}^{1 \times h}bh(f)?��R1��h��bh(b)��R1��h\boldsymbol{b}_h^{(b)} \in \mathbb{R}^{1 \times h}bh(b)?��R1��h ��Ϊģ�Ͳ�����
Ȼ�����������������������״̬ H��t\overrightarrow{\boldsymbol{H}}_tHt? �� H��t\overleftarrow{\boldsymbol{H}}_tHt? ���õ�����״̬ Ht��Rn��2h\boldsymbol{H}_t \in \mathbb{R}^{n \times 2h}Ht?��Rn��2h�����������뵽����㡣����������� Ot��Rn��q\boldsymbol{O}_t \in \mathbb{R}^{n \times q}Ot?��Rn��q���������Ϊ qqq ����
Ot=HtWhq+bq\boldsymbol{O}_t = \boldsymbol{H}_t \boldsymbol{W}_{hq} + \boldsymbol{b}_qOt?=Ht?Whq?+bq?
����Ȩ�� Whq��R2h��q\boldsymbol{W}_{hq} \in \mathbb{R}^{2h \times q}Whq?��R2h��q ��ƫ�� bq��R1��q\boldsymbol{b}_q \in \mathbb{R}^{1 \times q}bq?��R1��q Ϊ������ģ�Ͳ�������ͬ�����ϵ����ص�Ԫ����Ҳ���Բ�ͬ��