Exposure Fusion Using Boosting Laplacian Pyramid
ЮФеТФПТМ
- Exposure Fusion Using Boosting Laplacian Pyramid
-
- JND Model
-
- Luminance Adaptation
- Contrast Masking
- Overall JND Model
- A Hybrid Exposure Weight Measurement
-
- Local Exposure Weight
- Global Exposure Weight
- JND-Based Saliency Weight
- Boosting Laplacian Pyramid
-
- Boosting guidance
- Boosting Function
- Combining
БОЮФЫуЗЈНсЙЙКЭЁЖExposure FusionЁЗЪЎЗжНгНќЃЌБШНЯВЛЭЌЕФЪЧдкFusionЫуЗЈФкВПШћНјСЫTone Mapping
JND Model
JNDЪЧШЫблЪгОѕЯЕЭГ(HVS)жаЕФвЛИіживЊИХФюЃЌМђЕЅРДЫЕОЭЪЧЭМЯёЕБжаИеКУФмЙЛв§Ц№ЪгОѕИажЊЕФЭМЯёВювь(the visibility threshold below which any change cannot be detected by HVS)ЃЌгыжЎУмЧаЯрЙиЕФРэТлЪЧWeber-LawЁЂCenter-SurroundЁЂContrast Sensitivity FunctionЃЌзмЕФРДЫЕОЭЪЧФЃФтЖдШЫблЪгОѕЖдЭМЯёБфЛЏЕФЯьгІЃЌЙигкJNDЕФМђЕЅИХЪіПЩвдВЮПМЁЖDigital Video Image Quality and Perceptual Coding-Chapter 9 ЃКComputational Models for Just-Noticeable DifferenceЁЗЃЌБОЮФJNDФЃаЭжївЊВЮПМТлЮФЁЖJust Noticeable Difference for Images with Decomposition Model for Separating Edge and Textured RegionsЁЗЁЃ
- Masking effectЃКЮвЕФРэНтгІИУЪЧжИЪгОѕЯджјадКЭЪгОѕШнШЬадЕФвтЫМЃЌБШШчЭЌвЛдыЩљБЛЗжБ№ЕўМгЕНЦНЬЙЧјгђЁЂБпдЕЧјгђЁЂЮЦРэЧјгђЃЌШЫблЖдетвЛдыЩљДјРДЕФЪгОѕЯьгІЪЧВЛЭЌЕФЃЌЦфжаЖдЦНЬЙЧјгђЕФдыЩљзюЮЊУєИаЃЌЮЦРэЧјгђетвЛдыЩљДјРДЕФЪгОѕБфЛЏзюаЁЃЌЫљвдЮвРэНтmasking effectгІИУЪЧЕБЧАЧјгђЖдаХКХБфЛЏЕФШнШЬЖШЛђуажЕ
ШЫблЪгОѕЯЕЭГЖдЭМЯёЕФБГОАССЖШаХЯЂ(Luminance Adaptation)КЭВњЩњОжВПЖдБШЖШЕФЯИНкаХЯЂ(Contrast Masking)ЕФЯьгІМАУєИаЖШЪЧЪЧКмВЛвЛбљЕФЃЌЖјЯИНкаХЯЂжаЕФБпдЕаХЯЂ(Edge Masking)КЭЮЦРэаХЯЂ(Texture Masking)вВДцдкИажЊЩЯЕФВювьЃЌвђДЫЃЌJNDФЃаЭЭЈГЃашвЊДгЭМЯёжаЗжНтГіБГОАССЖШаХЯЂ(LA)ЁЂБпдЕаХЯЂ(EM)ЁЂЮЦРэаХЯЂ?ЃЌЫуЗЈЛљБОПђМмШчЯТЃК
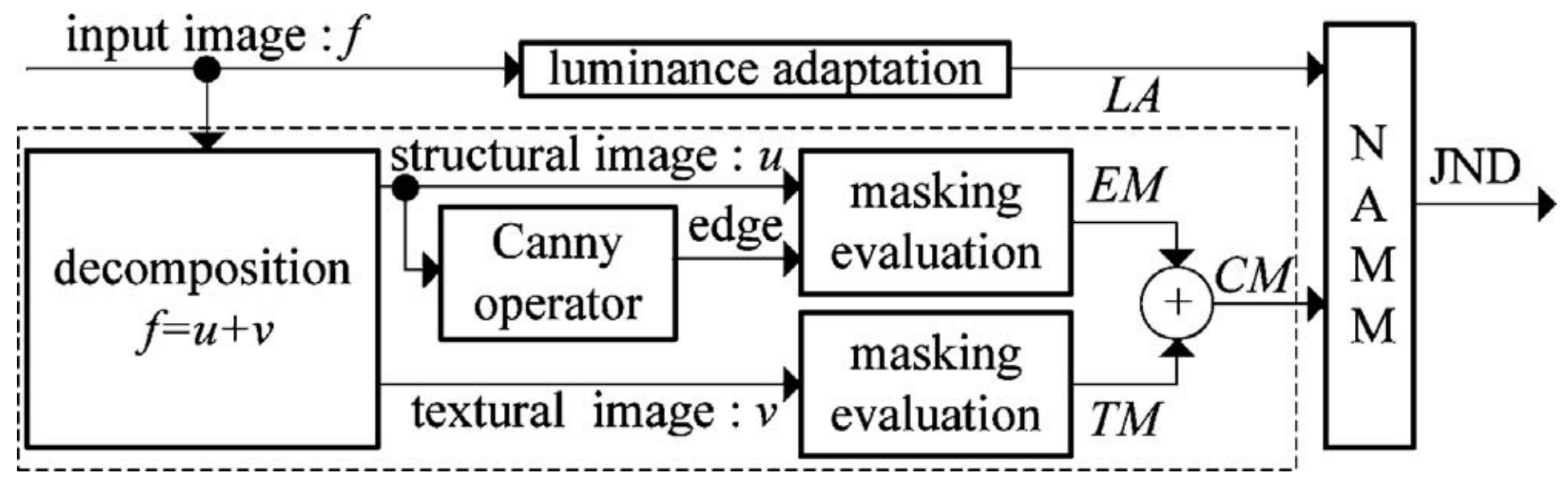
вдЩЯJNDПђМмжаНЋдЭМЯёfffЗжНтЮЊf=u+vf=u+vf=u+vЪЙгУЕФЪЧШЋБфЗжЃЌЗжНтжЎКѓгУЦфЕЭЭЈТЫВЈНсЙћuuuБэЪОЭМЯёЕФжївЊНсЙЙаХЯЂЃЌгЩгкШЋБфЗжОпгаБЃГжЭМЯёБпдЕШёЖШЕФаджЪЃЌДЫЪБuuuЕБжавРОЩБЃгаШёРћЕФБпдЕаХЯЂЃЌгУCannyЫузгДгuuuжаЬсШЁГіЭМЯёЕФБпдЕаХЯЂЃЌгУvvvзїЮЊЭМЯёЯИНкаХЯЂЁЃ
Luminance Adaptation
LALALAМДЪЧШЫблЪгОѕЯЕЭГЖдЭМЯёБГОАССЖШаХЯЂЕФЯьгІЃК
LA(x,y)={17ЁС(1?f(x,y)/127)+3,if f(x,y)Ём1273ЁС(f(x,y)?127)/128+3,otherwise L A(x, y)=\left\{\begin{array}{ll} 17 \times(1-\sqrt{f(x, y) / 127})+3, & \text { if } f(x, y) \leq 127 \\ 3 \times(f(x, y)-127) / 128+3, & \text { otherwise } \end{array}\right. LA(x,y)={
17ЁС(1?f(x,y)/127?)+3,3ЁС(f(x,y)?127)/128+3,? if f(x,y)Ём127 otherwise ?
ЦфжаfffЮЊдЭМЕФЯёЫижЕЁЃ
Contrast Masking
гЩгкШЫблЖдБпдЕаХЯЂОпгавЛЖЈЕФдЄВтФмСІЃЌЖјЖдЮЦРэаХЯЂЕФдЄВтФмСІНЯВюЃЌвђДЫЮЦРэЧјгђЕФMasking EffectвЊЧПгкБпдЕЧјгђЕФMasking EffectЃЌЗжБ№МЦЫуБпдЕЧјгђЕФMasking Effect EMuEM^{u}EMuЁЂЮЦРэЧјгђЕФMasking Effect TMvTM^{v}TMvЃК
EMu(x,y)=Csu(x,y).ІТ.WeTMv(x,y)=Csv(x,y).ІТ.WtEM^{u}(x,y)=C^{u}_{s}(x,y).\beta.W_{e}\\ TM^{v}(x,y)=C^{v}_{s}(x,y).\beta.W_{t} EMu(x,y)=Csu?(x,y).ІТ.We?TMv(x,y)=Csv?(x,y).ІТ.Wt?
ЦфжаCsuЁЂCsvC^{u}_{s}ЁЂC^{v}_{s}Csu?ЁЂCsv?ЗжБ№ЮЊuЁЂvuЁЂvuЁЂvжаПеМфгђФк5ЁС55ЁС55ЁС5ЕФДАПкФкзюДѓССЖШВюЃЛWeЁЂWtW_{e}ЁЂW_{t}We?ЁЂWt?ЗжБ№ЖдгІБпдЕЧјгђЁЂЮЦРэЧјгђЕФMasking EffectЯьгІШЈжиЃЌдкCsC_{s}Cs?ЯрЭЌЕФЧщПіЯТЃЌЮЦРэЧјгђЕФЯьгІвЊИпгкБпдЕЧјгђЃЌЫљгаWe<WtW_{e}<W_{t}We?<Wt?ЃЌвЛАуЧщПіЯТWe=1ЁЂWt=3ЁЂІТ=0.117W_{e}=1ЁЂW_{t}=3ЁЂ\beta=0.117We?=1ЁЂWt?=3ЁЂІТ=0.117ЃЌзюКѓЕФContrast MaskingЮЊЃК
CM(x,y)=EMu(x,y)+TMv(x,y)CM(x,y)=EM^{u}(x,y)+TM^{v}(x,y) CM(x,y)=EMu(x,y)+TMv(x,y)

Overall JND Model
зюКѓНЋЩЯЪіЕФССЖШЯьгІКЭЯИНкЯьгІећКЯдквЛЦ№ЃЌМДЮЊШЫблЪгОѕЕФЯджјадЯьгІЃК
JND=LA+CM?ClcЁСmin(LA,CM)JND = LA+CM-C^{lc}ЁСmin(LA,CM) JND=LA+CM?ClcЁСmin(LA,CM)
ЦфжаClcЁСmin(LA,CM)C^{lc}ЁСmin(LA,CM)ClcЁСmin(LA,CM)ЪЧЮЊСЫШЅГ§LAЁЂCMLAЁЂCMLAЁЂCMНЋжиЕўЕФЯьгІЧПЖШЃЌвЛАуШЁClc=0.3C^{lc}=0.3Clc=0.3ЁЃ
A Hybrid Exposure Weight Measurement
Local Exposure Weight
ХаЖЯЭМЯёађСажаЕФФГвЛЕуЪЧЗёЦиЙтКЯЪЪЃЌЮЊСЫШУађСажаЙ§ЦиЁЂЧЗЦиЕФЧјгђВЛВЮгыШкКЯЃЌгУвдЯТКЏЪ§ЖдЭМЯёађСажаЕФЭМЯёЪЧЗёЦиЙтКЯЪЪНјааЦРМлЃК
Qi(x,y)=1?ЈO1a{log?Ii1c(x,y)1?Ii1c(x,y)?b}ЈOEi(x,y)=rgb2gray(Qi(x,y))(1)Q_{i}(x, y)=1- \left | \frac{1}{a}\left\{\log \frac{I_{i}^{\frac{1}{c}}(x, y)}{1-I_{i}^{\frac{1}{c}}(x, y)}-b\right\} \right | \\ E_{i}(x,y)=rgb2gray(Q_{i}(x,y))\tag{1} Qi?(x,y)=1?ЈOЈOЈOЈOЈO?a1?{
log1?Iic1??(x,y)Iic1??(x,y)??b}ЈOЈOЈOЈOЈO?Ei?(x,y)=rgb2gray(Qi?(x,y))(1)
ЦфжаaЁЂbЁЂcaЁЂbЁЂcaЁЂbЁЂcЮЊЧњЯпПижЦВЮЪ§ЃЌвЛАуa=3.2ЁЂb=?1.3ЁЂc=0.4a=3.2ЁЂb=-1.3ЁЂc=0.4a=3.2ЁЂb=?1.3ЁЂc=0.4
Global Exposure Weight
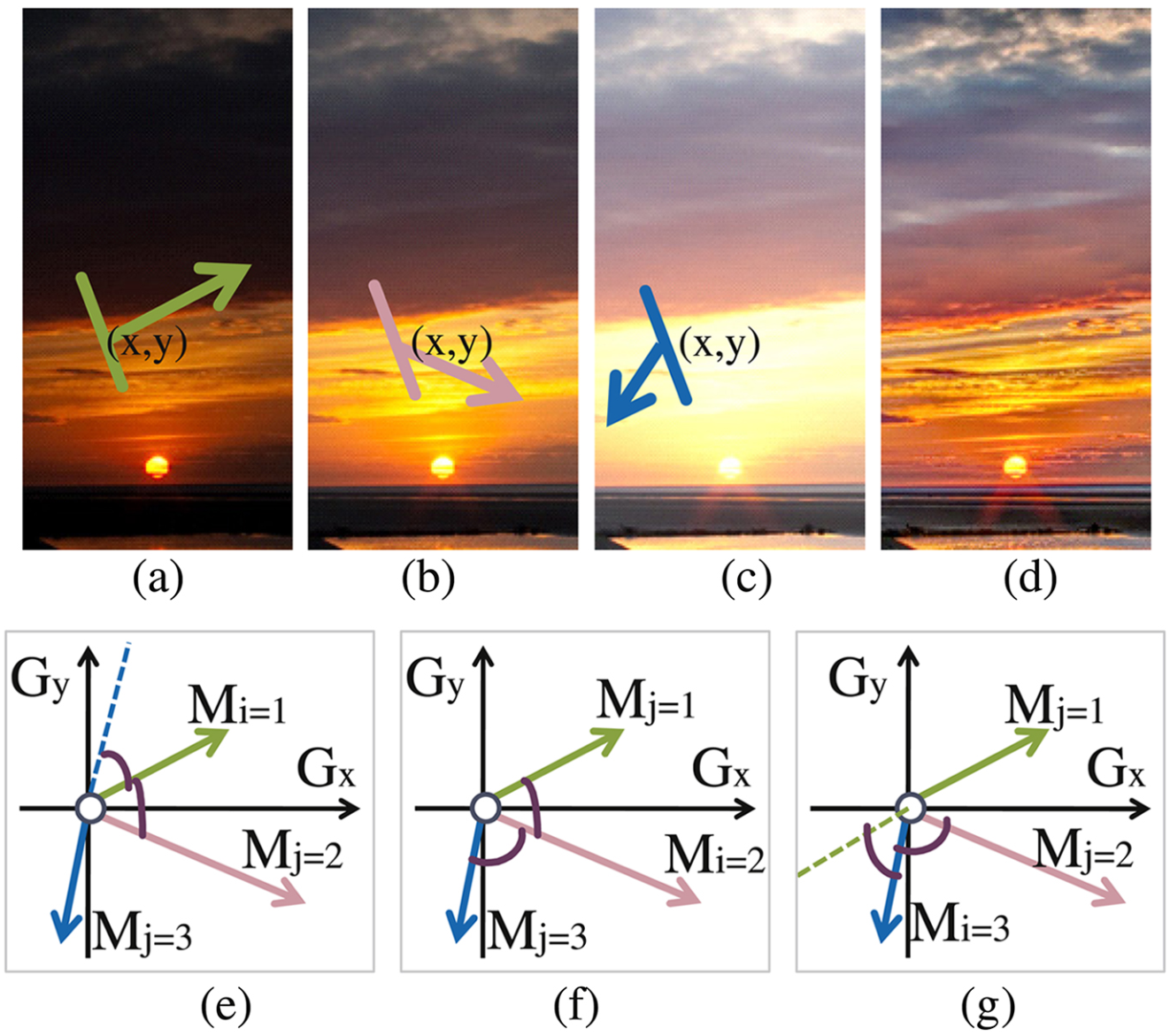
ХаЖЯЭМЯёађСажаФГвЛЕуЯрЖдгкећИіЭМЯёађСаЖјбдЪЧЗёЦиЙтКЯЪЪЃЌОпЬхЗНЗЈЪЧЖдЁЖGradient-directed Composition of Multi-exposure ImagesЁЗжаЛљгкЭМЯёЬнЖШЗНЯђБфЛЏзіЭМЯёШкКЯЕФЗНЗЈЕФбгЩъЁЃКЭдЗНЗЈВЛЭЌЕФЪЧЃЌБОЮФЪЙгУЭМЯёЬнЖШЗНЯђБфЛЏВЛЪЧЮЊСЫМьВтдЫЖЏЮяЬхЃЌЖјЪЧЮЊСЫМьВтгУгкШкКЯЕФЯёЫиЕуЪЧЗёОпгаСМКУЕФЦиЙтЃЌБОЮФжаЕФЗНЗЈМйЩшЃЌЖдгкОВЬЌГЁОАЃЌдкЭМЯёађСажаЦиЙтСМКУЕФЯрСкжЁдкЭЌвЛЕуЕФЬнЖШЗНЯђгІИУЪЧБШНЯНгНќЕФЃЌЧвгЩгкЭМЯёађСаЦиЙтСМКУЃЌЭМЯёЕФЬнЖШЗљЖШвВЛсБШНЯДѓЃЌвђДЫЃЌЭЈЙ§МЦЫуСНЬнЖШЯђСПМфЕФЦЋВюРДБэЪОЭМЯёађСажаШЮвтСНжЁНЋЕФЬнЖШВювьадЃК
Sij(x,y)=ЈOЈOMj(x,y)ЈOЈOЁСsin(Mi(x,y),Mj(x,y))(2)S_{ij}(x,y)=||M_{j}(x,y)||ЁСsin(M_{i}(x,y),M_{j}(x,y))\tag{2} Sij?(x,y)=ЈOЈOMj?(x,y)ЈOЈOЁСsin(Mi?(x,y),Mj?(x,y))(2)
ВЂЖдSijS_{ij}Sij?зі9ЁС99ЁС99ЁС9ЕФОљжЕТЫВЈЃЌвдЦНЛЌдыЩљЕФгАЯьЁЃ
Tij(x,y)=1?ІЫЁСSij(x,y)(3)T_{ij}(x,y)=1-\lambdaЁСS_{ij}(x,y)\tag{3} Tij?(x,y)=1?ІЫЁСSij?(x,y)(3)
KaTeX parse error: No such environment: align at position 55: Ёrray}{c} \begin{?a?l?i?g?n?}? T_{i j}(x, y),Ё
ЦфжаІЫ=100\lambda=100ІЫ=100ЮЊЦЋВюЕФЗХДѓВЮЪ§ЃЌзюжегУTijЁфT^{'}_{ij}TijЁф?БэЪОШЮвтСНжЁМфЕФЬнЖШЗНЯђЯрЫЦЃЌзюКѓМЖСЊTijЁфT^{'}_{ij}TijЁф?ЕУЕНШЋОжЕФЦиЙтШЈжиЃК
Vj(x,y)=ЁЧi=1,iЁйjNTijЁф(x,y)(5)V_{j}(x, y)=\prod_{i=1, i \neq j}^{N} T_{i j}^{\prime}(x, y)\tag{5} Vj?(x,y)=i=1,iЊС?=jЁЧN?TijЁф?(x,y)(5)
JND-Based Saliency Weight
JNDЪЧШЫблЪгОѕЯЕЭГ(HVS)жаЕФвЛИіживЊИХФюЃЌМђЕЅРДЫЕОЭЪЧЭМЯёЕБжаИеКУФмЙЛв§Ц№ЪгОѕИажЊЕФЭМЯёВювь(the visibility threshold below which any change cannot be detected by HVS)ЃЌгыжЎУмЧаЯрЙиЕФРэТлЪЧWeber-LawЁЂCenter-SurroundЁЂContrast Sensitivity FunctionЃЌзмЕФРДЫЕОЭЪЧФЃФтЖдШЫблЪгОѕЖдЭМЯёБфЛЏЕФЯьгІЃЌЙигкJNDЕФМђЕЅИХЪіПЩвдВЮПМЁЖDigital Video Image Quality and Perceptual Coding-Chapter 9 ЃКComputational Models for Just-Noticeable DifferenceЁЗЁЃ
- ЪзЯШМЦЫувдЕБЧАЕуЮЊжааФЕФвЛИі5ЁС55ЁС55ЁС5ЕФДАПкФкГ§ЕБЧАЕуЭтЕФЕЭЭЈТЫВЈIЁЅ(x,y)\bar{I}(x,y)IЁЅ(x,y)ЃЌвдДЫзїЮЊЕБЧАЕуЫљдкЕФБГОАССЖШжЕЃЌЫцКѓИљОнДЫБГОАССЖШМЦЫуССЖШЯьгІ(Background Luminance Masking)ЃК
Jil(x,y)={17(1?IЁЅ(x,y)127)+3,if IЁЅ(x,y)Ём1273128(IЁЅ(x,y)?127)+3,otherwise J_{i}^{l}(x, y)=\left\{\begin{array}{c} 17\left(1-\sqrt{\frac{\bar{I}(x, y)}{127}}\right)+3, \text { if } \bar{I}(x, y) \leq 127 \\ \frac{3}{128}(\bar{I}(x, y)-127)+3, \text { otherwise } \end{array}\right. Jil?(x,y)=????17(1?127IЁЅ(x,y)??)+3, if IЁЅ(x,y)Ём1271283?(IЁЅ(x,y)?127)+3, otherwise ?
Jl(x,y)J^{l}(x,y)Jl(x,y)гавЛЕуРрЫЦгыШЫблЖдССЖШЕФИажЊЧњЯпЁЃ
- ЫцКѓИљОнЭМЯёЬнЖШМЦЫуЮЦРэЯьгІ(Texture Masking)ЃК
Jit(x,y)=max?k=1,2,3,4{ЈOgrad?k(x,y)ЈO}grad?k(x,y)=I(x,y)?gk(x,y)\begin{array}{c} J_{i}^{t}(x, y)=\max _{k=1,2,3,4}\left\{\left|\operatorname{grad}_{k}(x, y)\right|\right\} \\ \operatorname{grad}_{k}(x, y)=I(x, y) \otimes g_{k}(x, y) \end{array} Jit?(x,y)=maxk=1,2,3,4?{ ЈOgradk?(x,y)ЈO}gradk?(x,y)=I(x,y)?gk?(x,y)?
g1=[000001383100000?1?3?8?3?100000],g2=[0010008300130?3?100?38000?100]g_{1}=\left[\begin{array}{rrrrr} 0 & 0 & 0 & 0 & 0 \\ 1 & 3 & 8 & 3 & 1 \\ 0 & 0 & 0 & 0 & 0 \\ -1 & -3 & -8 & -3 & -1 \\ 0 & 0 & 0 & 0 & 0 \end{array}\right], \quad g_{2}=\left[\begin{array}{rrrrr} 0 & 0 & 1 & 0 & 0 \\ 0 & 8 & 3 & 0 & 0 \\ 1 & 3 & 0 & -3 & -1 \\ 0 & 0 & -3 & 8 & 0 \\ 0 & 0 & -1 & 0 & 0 \end{array}\right] g1?=???????010?10?030?30?080?80?030?30?010?10????????,g2?=???????00100?08300?130?3?1?00?380?00?100????????
g3=[0010000380?1?30310?8?30000?100],g4=[010?10030?30080?80030?30010?10]g_{3}=\left[\begin{array}{rrrrr} 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 3 & 8 & 0 \\ -1 & -3 & 0 & 3 & 1 \\ 0 & -8 & -3 & 0 & 0 \\ 0 & 0 & -1 & 0 & 0 \end{array}\right], \quad g_{4}=\left[\begin{array}{lllll} 0 & 1 & 0 & -1 & 0 \\ 0 & 3 & 0 & -3 & 0 \\ 0 & 8 & 0 & -8 & 0 \\ 0 & 3 & 0 & -3 & 0 \\ 0 & 1 & 0 & -1 & 0 \end{array}\right] g3?=???????00?100?00?3?80?130?3?1?08300?00100????????,g4?=???????00000?13831?00000??1?3?8?3?1?00000????????
- зюКѓМЦЫуЯджјадШЈжиЃК
Ji(x,y)=Jil(x,y)+Jit(x,y)?Kl,t(x,y)min?(Jil(x,y),Jit(x,y))J_{i}(x, y)=J_{i}^{l}(x, y)+J_{i}^{t}(x, y)-K_{l, t}(x, y) \min \left(J_{i}^{l}(x, y), J_{i}^{t}(x, y)\right) Ji?(x,y)=Jil?(x,y)+Jit?(x,y)?Kl,t?(x,y)min(Jil?(x,y),Jit?(x,y))
Boosting Laplacian Pyramid
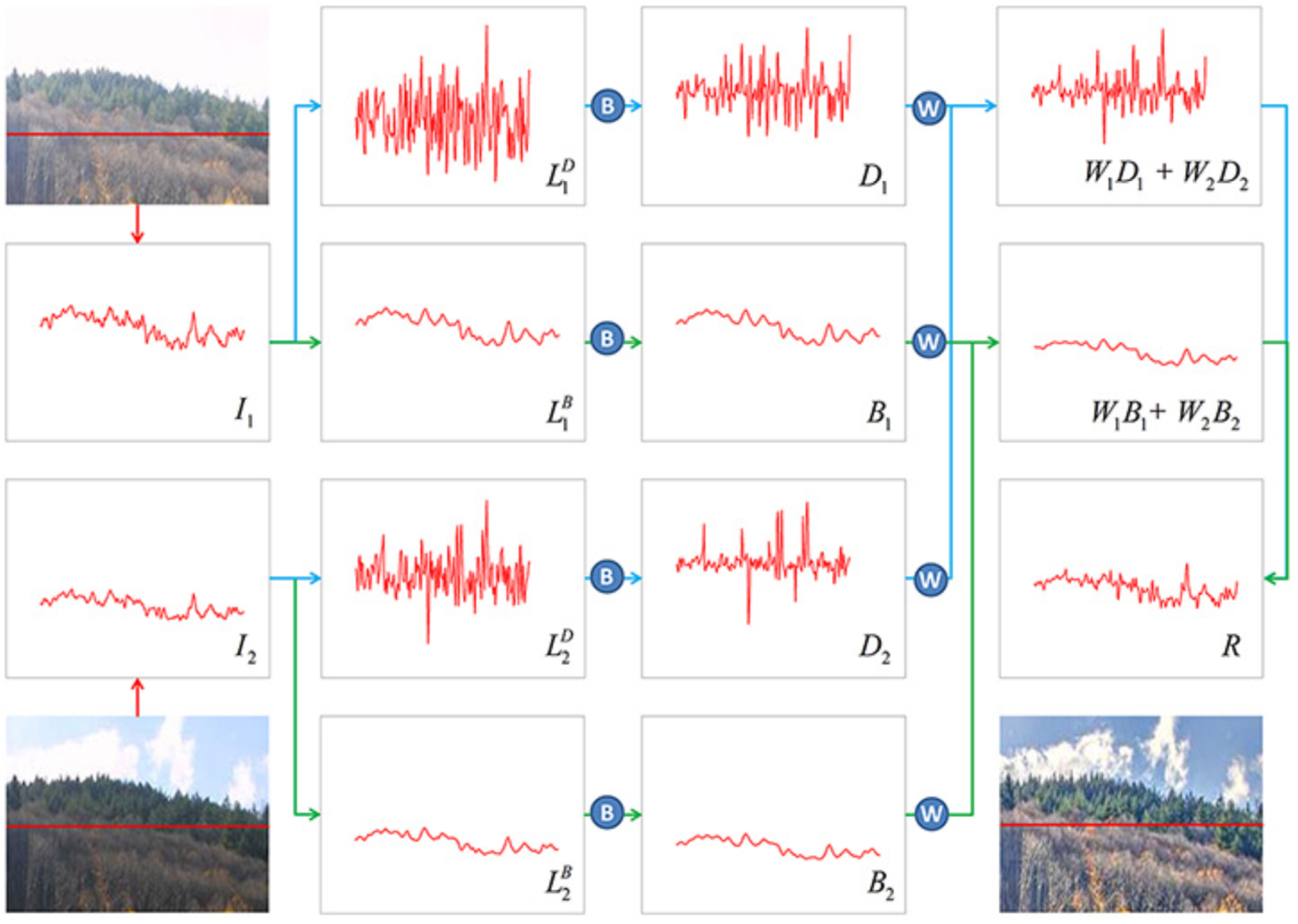
ЪзЯШЖдЖрЦиЙтЭМЯёађСазіИпЫЙН№зжЫўЁЂРЦеРЫЙН№зжЫўЗжНтЃЌдкРЦеРЫЙН№зжЫўжаЖдЭМЯёЕФЛљДЁВу(Н№зжЫўЕФзюЖЅВу)ЁЂЯИНкВу(Г§ЖЅВуЭтЕФЦфЫћВу)ЗжБ№зіЯргІЕФдіЧПДІРэЁЃдкКѓајЕФдіЧПЙ§ГЬжаЪЙгУЧАЪіЕФLocal Exposure WeightКЭJND-Based Saliency WeightзїЮЊдіЧПВЮЪ§ЃЌФПЕФЪЧЖдЪгОѕЯджјадЧјгђНјааЯИНкдіЧПКЭЕїећЭМЯёССЖШЫЎЦНЃЌМДдкН№зжЫўФкВПЕФTone MappingЁЃ
вдСНжЁЭМЯёЕФШкКЯЮЊР§ЃЌМЧРЦеРЫЙН№зжЫўЕФЖЅВуЮЊLiBL^{B}_{i}LiB?ЃЌЦфЫћВуЮЊLi,jDL^{D}_{i,j}Li,jD?ЃЌjjjЮЊЯИНкВуЕФЫїв§ЁЃ
Boosting guidance
-
гУОжВПЦиЙтШЈжиEiE_{i}Ei?бЁдёзіЯИНкдіЧПЕФЧјгђ
KaTeX parse error: No such environment: align at position 48: Ёrray}{c} \begin{?a?l?i?g?n?}? &1, E_{i}(x, yЁ
ЦфжаІв=0.01\sigma=0.01Ів=0.01ЃЌгУРДХХГ§ЕєЭМЯёађСажаЕФЙ§ЦиЁЂЧЗЦиЧјгђЃЌБмУтЖдетВПЗжЧјгђзідіЧПВњЩњArtifactsЁЃ -
гаЭМЯёЯджјадШЈжиJiJ_{i}Ji?ПижЦЭМЯёдіЧПЕФЧПЖШ
GiJ(x,y)=GiE(x,y)ЁСJi(x,y)G_{i}^{J}(x, y)=G_{i}^{E}(x, y) \times J_{i}(x, y) GiJ?(x,y)=GiE?(x,y)ЁСJi?(x,y)
Boosting Function
- ЖдЯИНкВуЕФдіЧПЃК
Di(x,y)=[LiD(x,y)]ІСi[LiD(x,y)]ІСi+ІТІСi,ІСi=ІС0GiJ(x,y)D_{i}(x, y)=\frac{\left[L_{i}^{D}(x, y)\right]^{\alpha_{i}}}{\left[L_{i}^{D}(x, y)\right]^{\alpha_{i}}+\beta^{\alpha_{i}}}, \alpha_{i}=\alpha_{0}^{G_{i}^{J}(x, y)} Di?(x,y)=[LiD?(x,y)]ІСi?+ІТІСi?[LiD?(x,y)]ІСi??,ІСi?=ІС0GiJ?(x,y)?
БОЮФбЁдёNaka-Rushton equationзїЮЊЯИНкВудіЧПКЏЪ§ЃЌЃЌNaka-Rushton equationЪЧGlobal Tone MappingЕФОЕфКЏЪ§ЃЌПЩвдПДГіЃЌзїепЫљЮНЕФдкН№зжЫўФкЗжБ№ЖдЛљДЁВуКЭССЖШВузідіЧПЕФзіЗЈЃЌЪЕМЪЩЯОЭЪЧдкН№зжЫўФкЗжБ№ЖдЛљДЁВуКЭЯИНкВузіTone MappingЁЃ - ЖдЛљДЁВуЕФдіЧПЃК
Bi(x,y)=[LiB(x,y)]ІУiІУi=ІУ0exp?(1nЁЦ(x,y)nlog?(GiJ(x,y)+?))\begin{array}{c} B_{i}(x, y)=\left[L_{i}^{B}(x, y)\right]^{\gamma_{i}} \\ \gamma_{i}=\gamma_{0} \exp \left(\frac{1}{n} \sum_{(x, y)}^{n} \log \left(G_{i}^{J}(x, y)+\epsilon\right)\right) \end{array} Bi?(x,y)=[LiB?(x,y)]ІУi?ІУi?=ІУ0?exp(n1?ЁЦ(x,y)n?log(GiJ?(x,y)+?))?
Combining
Н№зжЫўФкЗжБ№ЖддіЧПКѓЕФЛљДЁВуЁЂЯИНкВузіШкКЯЃЌзюКѓжиНЈШкКЯКѓЕФЭМЯёЃК
R=ЁЦi=1N=2Wi1Di1+(ЁЦi=1N=2Wi2Di2)Ёќ+(ЁЦi=1N=2Wi3Bi)ЁќR=\sum_{i=1}^{N=2} W_{i 1} D_{i 1}+\left(\sum_{i=1}^{N=2} W_{i 2} D_{i 2}\right) \uparrow+\left(\sum_{i=1}^{N=2} W_{i 3} B_{i}\right) \uparrow R=i=1ЁЦN=2?Wi1?Di1?+(i=1ЁЦN=2?Wi2?Di2?)Ёќ+(i=1ЁЦN=2?Wi3?Bi?)Ёќ