1.2.4 训练数据与测试数据机器学习:从数据中学习知识、模式、规律。
机器学习的目标:

此时映射函数是将数据从像素点空间映射到我们人类的语义空间上。
如果原始数据是文本数据,则映射函数则是将文档中的单词序列映射成‘喜悦、愤怒’等表达情感的词汇,完成情感分类。
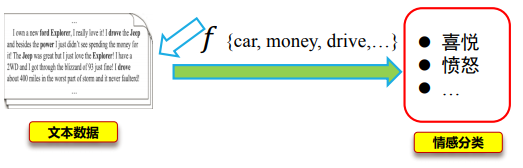
从图像中或者从文本中学习得到映射函数都实现了把数据从原始的数据空间映射到我们所定义的高级语义空间的这一个任务。
这也体现了机器学习中映射函数的重要性。
机器学习的分类:
1、 监督学习(supervised learning) :数据有标签、一般为回归或分类等任务。
2、无监督学习(un-supervised learning) :数据无标签、一般为聚类或若干降维任务。
3、半监督学习 (semi-supervised learning):一部分数据有标签,一部分数据没有标签。
4、强化学习(reinforcement learning): 序列数据决策学习,一般为与从环境交互中学习。
1.1监督学习中的分类问题
这类问题就是从标签数据中学习得到映射函数f(数学好 = Yes,会编程 = Yes, 身体好 =?,嗓门大 =?), 然后通过给定的参数信息,我们就可以判断这个人是否是程序员。

1.2 监督学习的重要元素
- 标注数据:标识了类别信息的数据
- 学习模型 :如何学习得到映射模型
- 损失函数 :如何对学习结果进行度量
1.2.1 标注数据详解,以及标记数据过程介绍:标记数据
1.2.2 学习模型 http://www.sohu.com/a/145845622_642762
1.2.3 损失函数

- 训练集中一共有?个标注数据,第?个标注数据记为 (?? , ??) ,其中第?个样本数据为??,??是??的标注信息。
- 从训练数据中学习得到的映射函数记为?, ?对??的预 测结果记为?(??) 。
- 损失函数就是用来计算??真实值?? 与预测值?(??)之间差值的函数。很显然,在训练过程中希望映射函数在训练数据集上 得到 “损失”之和最小,即


1.2.4 训练数据与测试数据

经验风险(empirical risk ): 训练集中数据产生的损失。经验风险越小说明学习模型对训练数据拟合程度越好,但它仅反映了局部数据。
期望风险(expected risk): 当测试集中存在无穷多数据时产生的损失。期望风险越小,学习所得模型越好,但它无法得到全量数据。


- 期望风险是模型关于联合分布期望损失,经验风险是模型关于 训练样本集平均损失。
- 根据大数定律,当样本容量趋于无穷时,经验风险趋于期望风 险。所以在实践中很自然用经验风险来估计期望风险。
- 由于现实中训练样本数目有限,用经验风险估计期望风险并不 理想,要对经验风险进行一定的约束。

结构风险最小化(structural risk minimization): 为了防止过拟合,在经验风险上加上表示模型复杂度的正则化项(regulatizer)或惩罚项(penalty term ) :

1.2.5监督学习方法
1、生成方法(generative approach)
所学到的模型分别称为生成模型 (generative model) , 生成模型从数据中学习联合概率分布?(?, ?)(通 过似然概率?(?|?) 和类概率?(?) 的乘积来求取) ![]()
典型方法为贝叶斯方法、隐马尔可夫链 , 联合分布概率?(?, ?)或似然概率?(?|?)求取很困难。
2、判别方法(discriminative approach) 。
判别方法直接学习判别函数?(?) 或者条件概率 分布?(?|?) 作为预测的模型,即 判 别 模 型 (discriminative model).。 判别模型关心在给定输入数据下,预测该数据的输出是什么。 典型判别模型包括回归模型、神经网络、支持向量机和Ada boosting等。