三、蒙特卡洛树搜索(Monte-Carlo Tree Search)
讲蒙特卡洛树搜索之前,我们先讲一下蒙特卡洛规划(Monte-Carlo Planning)
蒙特卡罗是一类随机方法的统称。这类方法的特点是,可以在随机采样上计算得到近似结果,随着采样的增多,得到的结果是正确结果的概率逐渐加大,但在(放弃随机采样,而采用类似全采样这样的确定性方法)获得真正的结果之前,无法知道目前得到的结果是不是真正的结果。
举例说明,一个有10000个整数的集合,要求其中位数,可以从中抽取m<10000个数,把它们的中位数近似地看作这个集合的中位数。随着m增大,近似结果是最终结果的概率也在增大,但除非把整个集合全部遍历一边,无法知道近似结果是不是真实结果。
单一状态蒙特卡洛规划:多臂赌博机(multi-armed bandits)
单一状态指一位玩家,假设现在有k个赌博机,即有k个摇臂,也就是k种行动,玩家每次以随机采样形式采取一种行动 a ,好比随机拉动第K个赌博机的臂膀,得到?(?,??) 的回报。 问题:下一次需要拉动那个赌博机的臂膀,才能获得最大回 报呢?

多臂赌博机问题是一种序列决策问题,这种问题需要在利用 (exploitation)和探索(exploration) 之间保持平衡。
- 利用(exploitation) :保证在过去决策中得到最佳回报
- 探索(exploration) :寄希望在未来能够得到更大回报

在多臂赌博机的研究过程中,上限置信区间(Upper Confidence Bound, UCB) 成为一种较为成功的策略学习方法,因为其在探索-利用(explorationexploitation)之间取得平衡。


蒙特卡洛树搜索
由Kocsis和Szepesvari在2006年提出 的,它是将上限置信区间算法UCB应用于游戏树的搜索方法。
包括了四个步骤:选举(selection),扩展(expansion),模拟(simulation),反向传播(BackPropagation)

选择:
从根节点 R 开始,向下递归选择 子节点,直至选择一个叶子节点L。
具体来说,通常用UCB1(Upper Confidence Bound,上限置信区间) 选择最具“潜力”的后续节点
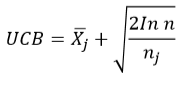
扩展:
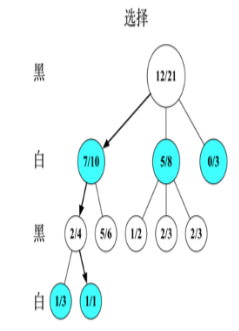
如果 L 不是一个终止节点(即 博弈游戏继续),则随机创建其 后的一个未被访问节点,选择 该节点作为后续子节点C。
模拟:
从节点 C出发,对游戏进行模拟, 直到博弈游戏结束。
反向传播 :
用模拟所得结果来回溯更新导致 这个结果的每个节点中获胜次数 和访问次数。
两种策略学习机制:
- 搜索树策略: 从已有的搜索树中选择或创建一个叶子结点(即蒙特卡洛中选择和拓展两 个步骤).搜索树策略需要在利用和探索之 间保持平衡。
- 模拟策略:从非叶子结点出发模拟游戏,得 到游戏仿真结果。
以围棋为例,假设根节点是执 黑棋方。

图中每一个节点都代表一个局面,每一个局面记录两个值 A/B:
A:该局面被访问中黑棋胜利次数。对于黑棋表示己方胜利次数,对于白棋表示己方失败次数(对 方胜利次数);
B:该局面被访问的总次数
该图刻画了蒙特卡洛树搜索四个步骤,
1. 假设根结点由黑棋行棋,为了选择根节 点后续节点,需要由UCB1公式来计算根 节点后续节点如下值,取一个值最大的 节点作为后续节点:
左1,7/10对应的局面奖赏值为: ![]()
左2, 5/8对应的局面奖赏值为:![]()
![]()
左3, 0/3对应的局面评估分数为: ![]()
由此可见,黑棋会选择局面7/10进行行 棋。
在节点7/10,由白棋行棋,评估该节点 下面的两个局面,由UCB1公式可得(注 意:此时A记录的的是白棋失败的次数, 所以第一项为1-A/B):
左1,2/4对应的局面奖赏为 ![]()
![]()
左2,5/6对应的局面奖赏为 ![]()
![]()
由此可见,白棋会选择局面2/4进行行棋。
2. 在节点2/4,黑棋评估下面的两个局 面,由UCB1公式可得:
左1,1/3对应的局面奖赏为: ![]()
左1,1/1对应的局面奖赏为: ![]()
由此可见,黑棋会选择局面1/1进行
行棋。此时已经到达叶子结点,需 要进行扩展。
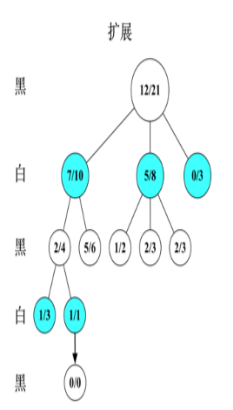
随机扩展一个新节点。由于该新节 点未被访问,所以初始化为0/0,接着在该节点下进行模拟。假设经过一系列仿真行棋后,最终白棋获胜。
根据仿真结果来更新该仿真路径上 每个节点的A/B值,该新节点的A/B 值被更新为0/1,并向上回溯到该仿真路径上新节点的所有父辈节点, 即所有父辈节点的A不变,B值加1

使用蒙特卡洛搜索Monte-Carlo Tree Search (MCTS)的原因:
蒙特卡洛树搜索基于采样来得到结果、而非穷尽式枚举(虽然在枚举过程中也可剪掉若干不影响结果的分支)