功能简介
昇腾AI处理器对网络执行层次进行划分,将特定功能的执行操作看做基本执行单位——计算引擎(Engine)。每个计算引擎在流程编排过程中对数据完成基本操作功能,如对图片进行分类处理、输入图片预处理及输出图片数据的标识等。计算引擎由开发者进行自定义来完成所需要的具体功能。
通过流程编排器的统一调用,整个深度神经网络应用一般包括四个引擎:数据引擎,预处理引擎,模型推理引擎以及后处理引擎。
数据引擎主要准备神经网络需要的数据集(如MNIST数据集)和进行相应数据的处理(如图片过滤等),作为后续计算引擎的数据来源。
一般输入媒体数据需要进行格式预处理来满足昇腾AI处理器的计算要求,而预处理引擎主要进行媒体数据的预处理,完成图像和视频编解码以及格式转换等操作,并且数字视觉预处理各功能模块都需要统一通过流程编排器进行调用。
数据流进行神经网络推理时,需要用到模型推理引擎。模型推理引擎主要利用加载好的模型和输入的数据流完成神经网络的前向计算。
在模型推理引擎输出结果后,后处理引擎再对模型推理引擎输出的数据进行后续处理,如图像识别的加框和加标识等处理操作。
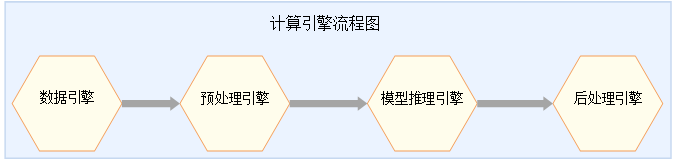
上图表示一种典型的计算引擎流程图。计算引擎流程图中每一个具体数据处理的节点就是计算引擎,数据流按照编排好的路径流过每个引擎时,分别进行相关处理和计算,最终输出需要的结果,而整个流程图最后输出的结果就是对应神经网络计算输出的结果。相邻两个计算引擎节点通过计算引擎流程图中的配置文件建立连接关系,节点间实际数据流会根据具体网络模型按节点连接方式进行流动。在配置完成节点属性后,向计算引擎流程图的开始节点灌入数据就会启动整个计算引擎的运行流程。
流程编排器,运行于L1芯片使能层之上,L3应用使能层之下,为多种操作系统(Linux、Android等)提供统一的标准化中间接口,并且负责完成整个计算引擎流程图的建立、销毁和计算资源的回收。
在计算引擎流程图建立过程中,流程编排器根据计算引擎的配置文件完成计算引擎流程图的建立。在执行之前,流程编排器提供输入数据。如果输入数据是视频图像等格式未能满足处理需要的形式,则可以通过相应的编程接口来调用数字视觉预处理模块进行数据预处理。如果数据满足处理要求,则直接通过接口调用离线模型执行器来进行推理计算。在执行过程中,流程编排器具有多节点调度和多进程管理功能,负责计算进程在设备端的运行,并守护计算进程,以及进行相关执行信息的统计汇总等。在模型执行结束后,为主机上的应用提供获取输出结果的功能。
应用场景
由于昇腾AI处理器针对不同的业务,可以组建具有不同专用性的硬件平台,所以根据具体硬件和主机端的协作情形,常见应用场景有加速卡(Accelerator)和开发者板(Atlas 200 DK)两种,流程编排器在这两种典型场景中的应用存在不同。
加速卡形式
基于昇腾AI处理器的PCIe加速卡主要面向数据中心和边缘侧服务器场景,如图2所示。PCIe加速卡支持多种数据精度,相比其他同类加速卡其性能有所提升,为神经网络的计算提供了更强大的计算能力。在加速器场景中,需要有主机来和加速卡相连,主机是能够支持PCIe插卡的各种服务器和个人计算机等,主机通过调用加速卡的神经网络计算能力来完成相应处理。
 ‘
‘
加速卡场景下的流程编排器功能由三个子进程来实现:流程编排代理子进程(Matrix Agent)、流程编排守护子进程(Matrix Daemon)和流程编排服务子进程(Matrix Service)。
流程编排代理子进程(Matrix Agent)通常运行在主机上,对数据引擎和后处理引擎进行控制和管理,完成与主机应用程序之间的处理数据交互,并对应用程序进行控制,还能与设备端的处理进程进行通信。
流程编排守护子进程(Matrix Daemon)运行在设备端,可以根据配置文件完成设备上流程的建立,负责启动设备上的流程编排进程并进行管理,同时在计算结束后完成计算流程的解除并进行资源回收。
流程编排服务子进程(Matrix Service)运行在设备端,主要对设备端上预处理引擎和模型推理引擎进行启动和控制。它控制预处理引擎调用数字视觉预处理模块的编程接口实现视频图像数据预处理功能。Matrix Service还可以调用离线模型执行器中模型管家编程接口实现离线模型的加载和推理。
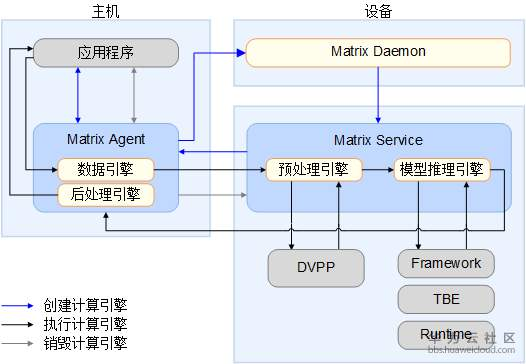
神经网络的离线模型通过流程编排器进行推理的计算过程如上图所示,主要分为3个步骤:
1.创建计算引擎流程图:通过流程编排器使用不同功能的计算引擎编排好神经网络的执行流程。
首先应用程序调用主机端的Matrix Agent,根据预先编写好的计算引擎流程图配置文件编排该神经网络的计算引擎流程图,创建好神经网络的执行流程,定义好每个计算引擎的任务。然后计算引擎编排单元将神经网络的离线模型文件和配置文件上传给设备端上的Matrix Daemon,接着由设备端的Matrix Service进行引擎初始化。Matrix Service会控制模型推理引擎调用模型管家的初始化接口加载神经网络的离线模型,完成整个计算引擎流程图的创建步骤。
2.执行计算引擎流程图:按照定义好的计算引擎流程图进行神经网络功能的计算和实现。
加载离线模型完成后会通知主机端的Matrix Agent进行应用数据的输入。应用程序直接将数据送入数据引擎中,进行相应的处理。如果传入的是媒体数据且不满足昇腾AI处理器的计算要求时,预处理引擎会马上启动,并且调用数字视觉预处理模块的接口,进行媒体数据预处理,如完成编解码、缩放等。预处理完成后将数据返回给预处理引擎,再由预处理引擎将数据传送给模型推理引擎。同时模型推理引擎调用模型管家的处理接口将数据和加载好的离线模型结合完成推理计算。在得到输出结果后,模型推理引擎调用流程编排单元的发送数据接口将推理结果返回给后处理引擎,由后处理引擎完成数据的后处理操作,最终再通过流程编排单元将后处理的数据返回给应用程序,至此完成了执行计算引擎流程图。
3.销毁计算引擎流程图:在所有计算完成后释放计算引擎占用的系统资源。
在所有引擎数据处理和返回完成后,应用程序通知Matrix Agent,进行数据引擎和后处理引擎计算硬件资源的释放;而Matrix Agent通知Matrix Service进行预处理引擎和模型推理引擎的资源释放。所有资源释放完成后,就完成了计算引擎流程图的销毁,由Matrix Agent再通知应用程序可以进行下一次的神经网络的执行。
开发者板形式
Atlas 200 DK应用场景是指基于昇腾AI处理器的Atlas 200开发者套件(Atlas 200 Developer Kit,Atlas 200 DK)场景,如下图所示。开发者套件将昇腾AI处理器的核心功能通过板子上的外围接口开放出来,方便从外部直接对芯片进行控制和开发,可以较容易且直观的发挥昇腾AI处理器的神经网络处理能力。因此,基于昇腾AI处理器构建的开发者套件可以被广泛的应用在不同的人工智能领域,也是日后移动端侧的主力硬件。

对于开发者板场景,主机的控制功能也在开发者板上,其逻辑架构如下图所示。
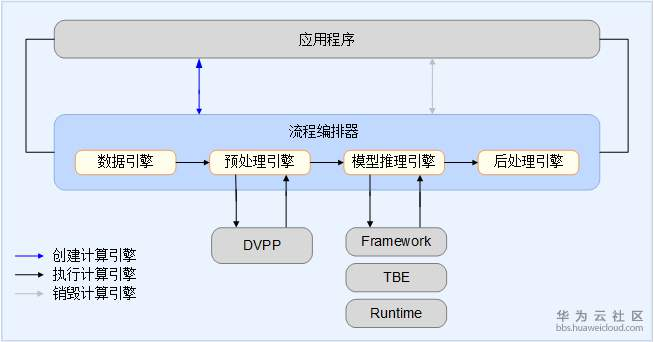
流程编排器作为昇腾AI处理器的功能接口,完成计算引擎流程图与应用程序的数据交互,流程编排器根据配置文件建立计算引擎流程图,负责编排流程和进程控制及管理,同时计算结束后进行计算引擎流程图的销毁和资源回收。预处理过程中,流程编排器调用预处理引擎的接口实现媒体预处理功能。在推理过程中,流程编排器还可以调用模型管家的编程接口实现离线模型的加载和推理。在开发者板应用场景下,流程编排器统筹整个计算引擎流程图的实现过程,不需要和其他设备进行交互。
作者:山人