етЪЧвЛЦЊдкarxiv7дТ2КХаТЩЯЕФвЛЦЊТлЮФЃЌзіЪгЦЕФПБъЗжИюЕФЁЃТлЮФБОЩэУЛгаЪВУДЬЋЖрЕФДДвтЃЌЪЙгУЯжгаЕФвЛаЉФЃПщзщКЯЃЌЬсГіСЫвЛжжДЎСЊНсЙЙЃЌАбVOSШЮЮёЗжГЩШ§ВНжшЃЌУПвЛВНжшЖдгІвЛИіФЃПщЃЌзюКѓЕФНсЙћДяЕНСЫstate of the art ЕФаЇЙћЁЃ
ТлЮФЕижЗ
ПЊдДЕижЗ
overview
зїепНЋVOSЗжВуШ§ИіВНжш
- object proposal network : ЯШгУmask rcnnПЊдДЕФRPNЃЌЭЈЙ§IOUПЩвдЬєбЁГіЪєгкЬиЖЈФПБъЕФКђбЁПђЃЌЬєбЁГіkИіЁЃ
- object tracking network : ЩЯвЛВНЕУЕНЕФKИіКђбЁПђЃЌЫЭШыЕНвЛИіЗжРрЭјТчЃЈMDNetЃЉзїЮЊХаБ№ЦїЃЌШЅХаБ№етаЉКђбЁПђЕФжЪСПШчКЮЁЃЩИбЁГізюКУЕФ5ИіЁЃжЎКѓАбет5ИіПђЕФзјБъЖМШЁЦНОљЃЌзїЮЊзюКѓЕФЕБЧАжЁЕФФПБъЧјгђЁЃ
- Dynamic Reference Segmentation Network ЃКЩЯвЛВНЕУЕНЕФзюжеЕФФПБъЧјгђЫЭШыЕНвЛИіЗжИюЭЗЭјТчЃЈseg headЃЉРяУцЃЌЭЌЪБНсКЯСЫmask rcnnЕУЕНЕФДжТдmaskЃЌЕквЛжЁЕФimage pairЃЈЭМЯёКЭдЄВтЕФpercise maskЃЉКЭЕкt-2ЕФ image pairЃЌЕкt-4жЁЕФimage pairЕФНсЙћЁЃ
дйИќЯИЕФНтЪЭвЛЯТЕквЛВНЕФЙ§ГЬЁЃЕквЛВНжЎЫљвдгУIOUЃЌЪЧвђЮЊRPNЪЧЖдШЋВПЕФФПБъЬсШЁЧБдкЃЈpotentialЃЉЕФФПБъКђбЁПђЃЌЕЋVOSНіНіеыЖдЬиЖЈЕФМИИіФПБъЛђепвЛИіФПБъЁЃЭЈЙ§IOUЃЌЕУЕНЫљгаКђбЁПђКЭЩЯвЛжЁдЄВтЧјгђЕФЗћКЯГЬЖШЃЌЬєбЁГіIOUДѓгк0.6ЕФзїЮЊЕБЧАжЁФПБъПЩФмДцдкЕФЮЛжУЁЃ
image pairЕФвтЫМЪЧЃКвЛИіДгдЭМcropГіРДЕФКђбЁПђЧјгђКЭетИіКђбЁПђЧјгђЖдгІЕФдЄВтmaskЁЃ
ЫљвдЫЕећИіЗНЗЈЃЌЪЕжЪУЛгаДДаТЃЌУЛгаЬсГівЛИіаТЕФбЇЯАЗНЗЈЃЌЪЙгУДЎааНсЙЙЃЈЯжгаФЃПщЃЉНтОіСЫVOSШЮЮёЁЃИќЯёЪЧНтОіСЫММЪѕЮЪЬтЃЌВЛЪЧЬсГівЛжжаТЗНЗЈЁЃВЛЙ§ЛЙЪЧИааЛзїепУЧЕФЙБЯзКЭПЊдДЁЃ
ећЬхЫйЖШгІИУВЛЛсЬЋПьЃЌЖјЧвЪЕЯжИДдгЃЌСЌзїепЖМгУСЫ effectiveетИіДЪаЮШнPTSNetЖјВЛЪЧefficientЁЃТлЮФЕФЗНЗЈашвЊFineTuningЃЌЫљвдВЛФмЯпЩЯдЫааСЫЁЃ
architecture
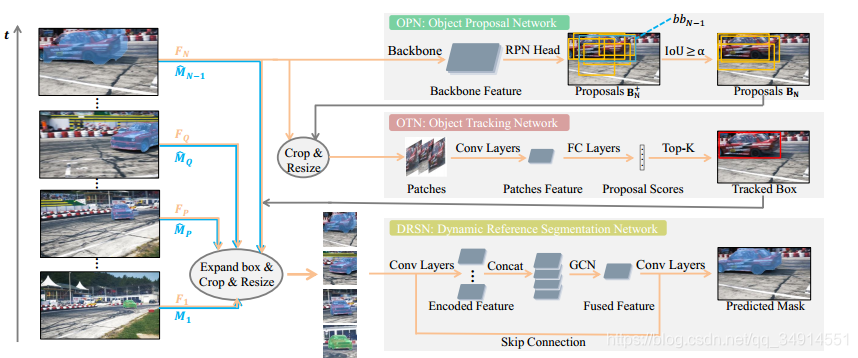
РЖЩЋЯпЪЧmaskЃЌЛЦЩЋЯпЪЧcropГіРДЕФФПБъЧјгђЃЌетСНзщГЩimage pairЁЃзЂвтЕБЧАжЁЪЙгУЩЯвЛжЁдЄВтЕФmaskзїЮЊimage pairЕФmaskГЩдБЁЃЕБЧАжЁFnF_nFn?ЃЈЛЦЩЋЯпЃЉЫЭЕНOPNжаОЙ§RPNЕУЕНКђбЁПђЃЌИљОнIOU>aIOU > aIOU>aЬєбЁГіКЯЪЪЕФКђбЁПђЁЃШЛКѓИњзХгвЩЯНЧЛвЩЋЯпзпЃЌетаЉБЛЬєбЁГіЕФКђбЁПђОЙ§КЯЪЪЕФResizeжЎКѓЃЌЫЭШыЕНOTNжаЃЈТлЮФжагУMDNetЃЌвЛИіИњзйЭјТчЃЉЃЌМЬЖјЬєбЁГіTop -k ЕФПђЁЃШЛКѓЦНОљвЛЯТетИіkИіПђЃЌНсКЯЩЯвЛжЁЕФmaskзщГЩimage pairЃЌЛЙгаЕкQжЁЕФimage pairЃЌЕкPжЁЕФimage pairЃЌКЭЕквЛжЁЕФimage pairЃЌЫЭШыЕНDRSNжаЃЌЛёЕУЗжИюНсЙћЁЃ
QЮЊЕБЧАжЁКХ-2ЃЌPЮЊЕБЧАжЁКХ-4ЁЃ
OPN

RPNОЭВЛдкЖрЩйЃЌЩЯУцЕФЭМЪЧОЙ§IOUжЎКѓЬєбЁГіРДЕФПђЃЌПЩвдЗЂЯжПђЕФжЪСПЛЙЪЧВЛДэЕФЃЌШЗЪЕАќКЌСЫЬиЖЈЕФФПБъЁЃ
Object Tracking Network
етвЛВНОЭЪЧindentifyКђбЁПђжЪСПЕФЙ§ГЬЁЃMDNetНсЙЙБЛЭъШЋБЃСєЯТРДЃЌЯШдкDAVIS2017Ъ§ОнМЏЩЯзідЄбЕСЗЁЃЃЈЗЧГЃживЊЃЌОЭЪЧЫЕMDNetдкPTSжаЦ№ЕНЕФзїгУОЭЪЧвЛИіЖўЗжРрЕФаЇЙћЃЉЃЌдкЪЙгУЕФЪБКђЃЌКђбЁПђresizeГЩКЯЪЪЕФГпДчЃЈЗћКЯMdNetЕФвЊЧѓЃЉЃЌШЛКѓЫЭНјЭјТчЃЌЕУЕНе§Р§ЕФИХТЪЃЌбЁШЁзюДѓЕФkИіИХТЪЖдгІЕФКђбЁПђЃЌдйЦНОљвЛЯТзјБъЁЃOKЃЌетОЭЪЧOTNЕФЪфГіСЫЁЃ
noteЃК OTNжаЪЙгУЕНЕФMDNetвВЪЧвЊЪЙгУГЄЖЬЪБИќаТЕФЁЃtop -kИіПђЖдгІЕФИХТЪШчЙћЯрМгДѓгк0ЃЌдђДњБэГЩЙІевЕНКЯЪЪЕФКђбЁПђЃЌНјааЖЬЪБИќаТЃЛШчЙћаЁгк0ЃЌЫЕУїетkИіПђЖМВЛКЯЪЪЃЌдђНјааГЄЪБИќаТЁЃ
Dynamic Reference Segmentation Network
ШчЙћЗЧвЊЫЕТлЮФЕФДДаТЕудкФФЃЌЮвдИвтАбДДаТЕуЙщНсЕНетРяЁЃ
ДгOSVOSЃЌmaskTrackЕНШчНёЕФsiammaskЃЌMOTSКЭPTSNetЃЌДњБэСЫVOSДгОВЬЌЭМЯёЗЂеЙЕНРћгУЖЏЬЌаХЯЂЃЌЖржЁЕФСЊЯЕЁЃвдЭљЛљгкЕЅжЁЕФАьЗЈЃЌЪЧППappearanceЁЃЯждквЛаЉЗНЗЈаажЎгааЇЃЌжЄУїСЫдкvideoШЮЮёжаЃЌНЈФЃЖржЁжЎМфЕФСЊЯЕЪЧКмживЊЕФЁЃзїепШЯЮЊЃЌЕквЛжЁЕФmaskПЩвдЬсЙЉКмПЩППЃЌЕЋЭЌЪБВЛОпгазюаТЕФаЮЯѓЬиеїЃЈБШШчЪгЦЕПЊЭЗзпЙ§РДвЛИіШЫЃЌПДЕНЕФЪЧе§УцЃЌШЫзпЙ§СЫЃЌОЭжЛФмПДМћБГУцСЫЃЉЁЃЯждкЯыв§ШыЖржЁЕФаХЯЂЃЌОЁЙмГ§СЫЕквЛжЁЃЌКѓУцЕФжЁЕФimage pairЕФmaskПЩФмВЛзМШЗЃЌЕЋзїепШЯЮЊЃЌШдШЛПЩвдЬсЙЉгааЇЕФappearance cuesЁЃ
ЫФжЁЕФimage pairЖМЭЈЙ§resnet50ЃЌзюКѓдкGCNДІЃЌдкЭЈЕРжсЦДНгЃЌЫЭЕНШЋОэЛњЭјТчжаЃЌЪфГіЭЈЕРЪ§ЮЊ2ЕФзюжедЄВтЁЃ
бЕСЗЗНЗЈ
ећИіЙ§ГЬВЛЪЧВЛЪЧЖЫЕНЖЫбЕСЗЕФЁЃ
- RPNРДзддкCOCOжадЄбЕСЗЕФФЃаЭЃЌЧвВЮЪ§ЙЬЖЈЃЌОЭЪЧВЛВЮМгбЕСЗЕФвтЫМЁЃRPNЕФNMSБЛвЦГ§ЃЌРДЛёЕУДѓИХ2000ИіПђЃЌет2000ИіПђКЭЩЯвЛжЁЕФpredictionЭтНгЕФОиаЮПђМЦЫуIOUЃЌЬєбЁГіIOUДѓгкaЕФПђЃЌaЩшжУЮЊ0.3
- OTNВЩгУMDNetЃЌАбГЄЪБИќаТЕФжЁЪ§БфГЩСЫ20ЃЌЖЬЪБИќаТЕФжЁЪ§БфГЩСЫ5ЁЃ
- DSRNЃЌResNet50ЪЧpretrainedЕФЃЌЪфШыЭМЯёЮЊ4256256,4ЪЧжИШ§ЭЈЕРЕФЭМЯёКЭ1ЭЈЕРЕФбкТыЃЌЫљвдResNetЕФЕквЛВуЕФЫљгаОэЛ§КЫЖМвЊМгЩЯвЛИіЭЈЕРЃЌКЭMaskTrackМгЭЈЕРЕФЗНЗЈРрЫЦЁЃСэЭтЃЌКЭMaskTrackРрЫЦЕФЛЙгаЃЌИУФЃПщашвЊonline finetuningЃЌЗНЗЈЪЧдкдЄВтвЛИіађСажЎЧАЃЌгУЕквЛжЁКЭЦфmaskВњЩњimage -pairЖдЁЃЦфЫћЩшжУКЭбЕСЗБЃГжвЛжТЁЃ
ДњТыНтЖС
ЮвУЧжЛПДПДDRSNЕФВПЗжЁЃ
def forward(self, ref_imask, p_imask, q_imask, x):_, _, h, w = x.size()visual_fea_list = []for g_imask in [ref_imask, p_imask, q_imask]:visual_fea_list.append(self.generate_visual_params(g_imask))visual_features = torch.cat(visual_fea_list, 1)feas = self.features(x)x = torch.cat((feas[-1],visual_features), 1)x = self.GCB(x)x = self.RM1(x, feas[-2])x = self.RM2(x, feas[-3])x = self.RM3(x, feas[-4])x = self.dropout2d(x)out = F.upsample(input=self.classfier(x), size=(h, w), mode='bilinear')return out
ЪзЯШОЭЪЧЫФИіЪфШывРДЮЫЭШыresNet50ЃЌЛёЕУstage5ЕФЪфГіЃЌШЛКѓconcatЃЌЫЭЕНGCBжаДЎаа ЫЭЕН3ИіRMФЃПщЁЃ